{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Greg Knauss
Testing and debugging are two of the most important-but underappreci-ated-phases of computer programming. Although most of the thought behind writing a CGI script goes into the script's design and most of the time goes into its coding, testing and debugging should be a part of not only your schedule, but your attitude as well.
Many programmers are prone to ignore testing and debugging the problems that testing uncovers. This is dangerous. By focusing on code creation and ignoring whether it actually works in all situations or not, they create something that looks sturdy enough but will fall over at the slightest brush. Look at it this way: A bad design, badly coded, can perform well enough if it's tested and debugged thoroughly. A good design, well coded, can cause endless problems if testing and debugging are neglected. To truly call your CGI script done, you can't skip the last half of the race.
In this chapter, you'll learn
Before you begin, a brief administrative concern should be addressed. Although testing and debugging are vital phases of software development, they are phases that should be entered into carefully, with forethought. For instance, you should have a place-isolated and stand-alone-to do your testing. The last thing you want to do is introduce your script to the world at large before it's ready.
You should take the time to set up a Web server that will act as a laboratory, separated from your real Web site and not even hooked up to the Net. Steps on how to do this are included later in the section "Creating an Isolated Environment." Although this may seem overly cautious-even paranoid-there are several good reasons to go through the trouble.
When you're testing and debugging your script, you want your environment to remain absolutely static so that repeating tests and tracking down bugs will be easier. If you test your CGI script on an isolated, non-networked machine, the process of keeping everything the same, of repeating exactly what you did to cause a bug, will be simplified.
Active Web sites are often very dynamic, and this can make debugging frustrating. The condition that causes your CGI program to accidentally delete database records (or simply report them wrong, or any number of other problems) might be transitory, appearing only when certain circumstances converge. A machine that isn't connected to the Web itself, that's cut off from the world in its own little lab, is absolutely vital in this regard.
The second reason for isolating your tests is that a script that hasn't been thoroughly tested and debugged is-simply put-not finished. You wouldn't ship any other type of program before you were done with it, and you should have the same attitude about your CGI scripts.
Your reputation on the Web is based on the quality and consistency of your site, and the control you maintain over your server reflects what type of administrator you are. By isolating your CGI scripts before they go live, you can preserve the reputation of all the other work you've done. Broken links, mangled graphics, and faulty CGI scripts are all signs of an ill-managed site. They make you look bad.
Untested scripts can actually damage your server as well as your
reputation. If you haven't given your CGI program a thorough workout
on an isolated machine before making it available on the Web,
you'll likely find that it's riddled with performance and security
problems.
| NOTE |
In one famous example, Pathfinder's The Netly News (http://www.pathfinder.com/Netly) got caught with its pants down. The Netly News was preparing to launch its article-a-day Web page and, while testing everything out, accidentally left its samples open to the entire Web. The test page was discovered, as almost anything on the Web is, and roundly mocked (most notably by competitor Suck, http://www.suck.com), even before the magazine made its first appearance |
Finally, if you think you've hidden your script away in such a deep, dark corner of your Web site that no human could find it and that will allow you to isolate your test, think again. Spiders (also known as Web crawlers) are automated programs designed to traverse every corner of the Web. They follow every link, check every machine, dig into every corner of every site on the Internet, and then index that information and present it to the public.
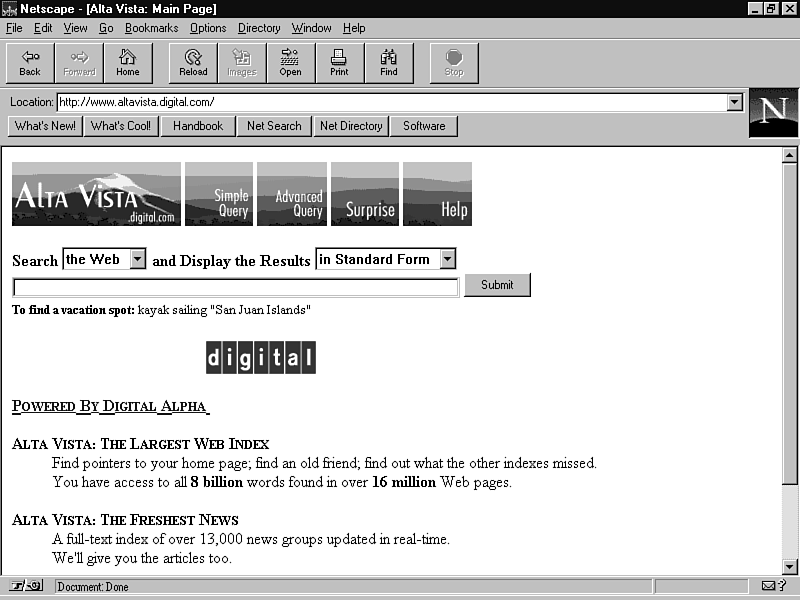
As of this writing, Digital Computer's Alta Vista (http://www.altavista.digital.com) is probably the most complete spider (see fig. 25.1). It claims an index of more than 16 million Web pages, all of which can be discovered simply by searching on any number of keywords. No doubt, thousands of those pages probably were never meant to be made public or advertised. But, of course, now they are.
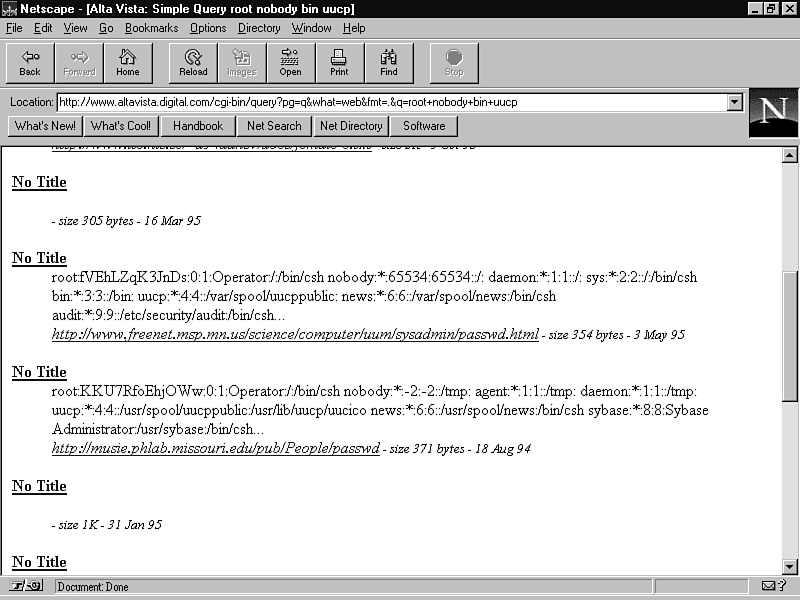
For instance, go to Alta Vista and search on root nobody. You'll get back something similar to figure 25.2, a listing of every Web page that contains those terms, including password files that just happen to be accidentally accessible from the Web.
Again, the only way to truly isolate your testing-and to protect your reputation and your Web site from buggy scripts-is to set up a computer off the Internet, disconnected from the Web, and do thorough testing there. Only after that should you make your script live to the world.
Isolating your server from the Web can be very simple, with a few frustrating caveats. If you're inexperienced at network configuration, make sure that you write down everything you do (and what state something was in before and after you make a change) so that it's easy to undo in case of a mistake.
For the most part, you can create a sterile, off-network test
environment by simply unplugging your computer's network connection.
Often, the connection at the wall looks like a large telephone
jack that can simply be pulled out; or the connection on the computer
should be labeled as a network port, which can be unplugged as
well. Some machines have a small box with flashing lights between
it and the wall called a transceiver; you can also sever
the connection there.
| CAUTION |
As with any electrical equipment, you should always power down your computer before inserting or removing plugs |
Of course, removing your test server from the network can have complications. You should never isolate a machine that's actively using (or is being used by) the network, or you could disrupt the work of others. And be sure never to unplug the network connection of your real Web server! Your isolated tests must be done on another system.
If you're planning to isolate a UNIX machine on which to run your tests, make sure that all network services it uses are shut down. For instance, the machine can't export from itself or import from elsewhere any NFS partitions. If the computer is now using NFS, each connection must be unmounted before the network connection is broken. The same goes for time daemons, SNMP statistics collectors, timed mail queues, or any number of other network services.
Also, your computer will no longer be able to use DNS to resolve
host names. You must make sure that its /etc/hosts file contains
the IP address and name of the machine itself, because that's
the only way it will be able to translate names to IP addresses.
| CAUTION |
You should never try to isolate a machine that's dependent on the network. Some UNIX operating systems load part of themselves from a main server over the Net, and if that connection can't be established, the computer will fail to come up at all. Also, NIS (or Yellow Pages) is a popular way to share user information across many machines, but it's also dependent on the network. A machine with NIS disabled may have only a limited number of logons available, none of which may be yours |
Before you isolate a Windows machine, you must make sure that it doesn't share any drives or use any shared drives-through the built-in Windows networking, through a third-party NFS package, or through a Novell LAN. If you normally log on to a workgroup or domain server, you need to cancel the dialog box rather than enter your password now that the computer is isolated. (If you use Windows NT, you need to change your domain to the name of the local machine and enter your local password.)
Under Windows, DNS should be disabled if it's in use. Windows can take what seems like forever to time out an unknown DNS request, and when your machine is isolated, it won't have access to the DNS server. To disable DNS, follow these steps:
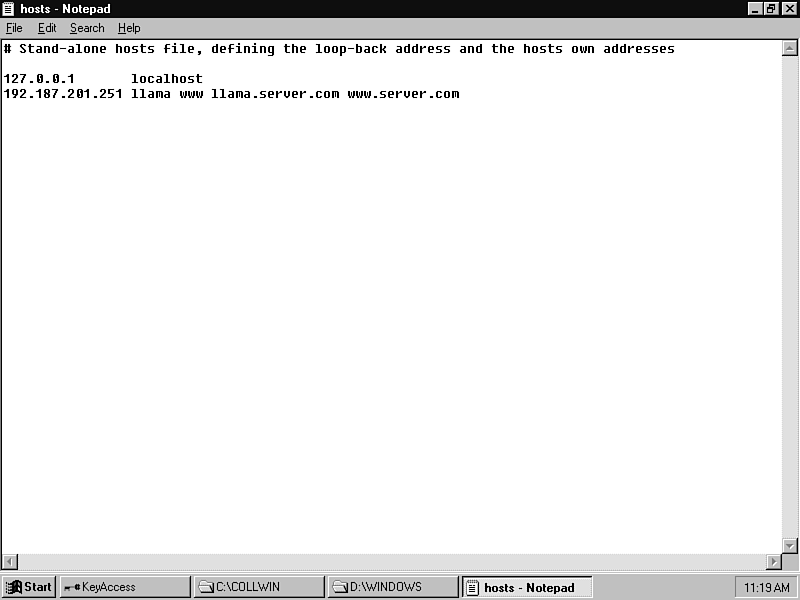
Because DNS is disabled, you must be sure to create a hosts file in your Windows directory, very similar to /etc/hosts on UNIX. At a minimum, there should be two entries (see fig. 25.3). Of course, the second line will vary for you-it will contain your machine's IP address and name.
Figure 25.3 : Windows host files can be small and simple.
| NOTE |
A more complicated way to create an isolated test lab is to build an entire subnet. Although the administration required to set up a subnet is well beyond the scope which is the capability to use more than one computer in your testing and debugging. With a single computer disconnected from the network, it must act as Web server and browser both. An isolated subnet allows you to better simulate real-world network interaction |
When your isolated server proves that your script is sound, you may want to gather a wider test audience-from within your company or university-before releasing it to the world at large. One way to do this is to reconnect your test server to the network, but change the port on which your Web server watches for connections. This can be done in your server configuration file-the default is port 80, but many people change it to 8008 or 8080 for testing.
When you enter the URL for this modified server, you must remember
to specify the new port number. If the old URL, to connect to
the server before it was reconfigured, was http://www.server.com/index.html,
the new URL will be, for example, http://www.server.com:8008/index.html.
| TIP |
Reconnecting to the network this way, with your server "hiding" on a non-standard port, is a good way to perform multiuser tests. See the later section "Types of Testing" for more information |
After you finish writing your CGI script and setting up an isolated test environment, you'll probably be ready to see it in action-and you'll probably be disappointed. Computer programs are notoriously difficult to get right, especially the first time they're run. Even "trivial" programs will have bugs, typos, or just about anything else that will prevent them from running correctly.
So in all likelihood, the first time you install and execute your completed CGI script, you'll end up with something that doesn't work as well as you'd hoped. It may not work at all.
This isn't the time to get discouraged. Although you may have just spent days or weeks on a program that, currently, accomplishes nothing, debugging is part of the entire development process and you should look on it as a stage as necessary as designing or coding.
There are two general categories of errors that your Web browser will receive from CGI scripts: server errors and incorrect output. Whereas server errors are usually simple to fix, incorrect output is a sign of bigger problems.
When a Web browser makes a request of a Web server, codes are exchanged on the request and on the response. Each code means something different-200, for instance, translates to "Message Follows (Success)"-and several indicate server errors. When Web browsers receive these error codes, they often display them to users, along with any textual information the server provided. Netscape isn't shy about informing users of problems (see fig. 25.4).
Although Netscape displays an error in one particular way, each browser is free to display that error however it chooses. Some hide the actual error code and display an English message instead. Some let the server itself define how the error looks. But no matter how the errors are displayed, every server responds with the same error codes when they encounter the same problems.
Users of your site might encounter many different server errors. 400, for instance, indicates a malformed request was made. 501 means that the browser tried to use a feature that's not implemented in your server software. 6993 informs the user that your Web server is misconfigured. But you'll most likely encounter three particular errors when testing and debugging your CGI scripts: 403, 404, and 500.
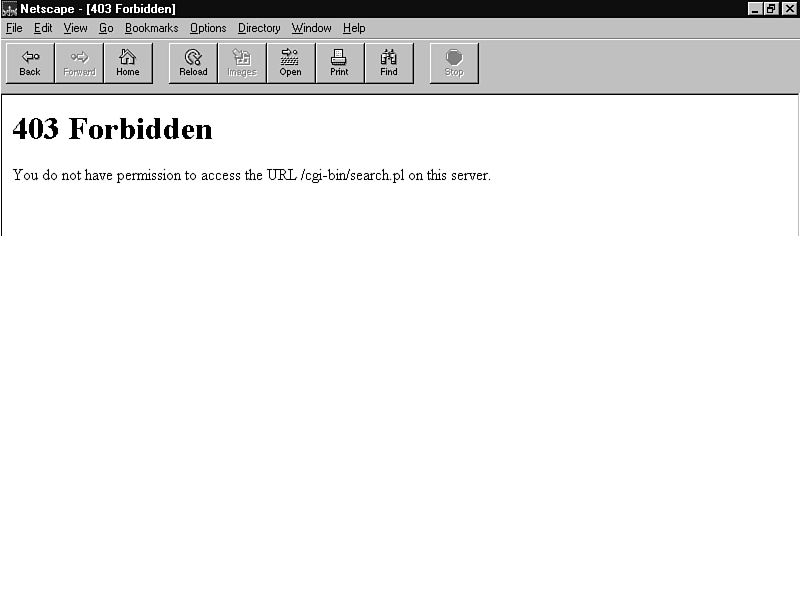
If you use your browser to try to run your CGI program and receive a 403 error instead of the nicely formatted page you were expecting, you're being told that access to the file you tried to reach is forbidden. The server has refused you entry.
The usual cause of this type of error is file permissions, either on the directories that contain the script or on the script itself. If, for example, the user your Web server is running as doesn't have read permission on your cgi-bin directory, the server will return 403 to the browser. Or if the CGI script itself doesn't have execute permission turned on, 403 will be sent back.
403 errors are easy to remedy. Under UNIX, simply chmod the directories that contain your script to readable, and the script itself to executable. For both cases, you must remember which user your Web server runs CGI programs as, and who owns the directories and the script itself, so you can set user, group, or world permissions accordingly. For example, if your CGI script is installed on your server as /usr/local/httpd/cgi-bin/script.pl, and the user your Web server ran as is "nobody," you want to make sure that usr and local have permissions that allow nobody to traverse them: The 555 command to chmod does this.
However, the permissions on the httpd and cgi-bin directories, and script.pl itself, should be more limited. If they're not already owned by the "nobody" user, they should be taken by him with the command
chown nobody /usr/local/httpd /usr/local/httpd/cgi-bin /usr/local/httpd/cgi-bin/script.pl
And their permissions should be made to allow only that user access:
chmod 700 /usr/local/httpd /usr/local/httpd/cgi-bin /usr/local/httpd/cgi-bin/script.pl
Under Windows NT, the File Manager's Security menu allows you to set directory and script permissions, but at a much more detailed level than UNIX does. Ideally, your cgi-bin directory allows access to, and the script itself is only executable by, only the user that the scripts run as. You can set these permissions as follows:
| TIP |
Under Windows 3.1 and Windows 95, there are no file system-based security limitations on reading, traversing, or executing directories or scripts, so none of this is a concern |
| CAUTION |
You might be tempted to just open up your cgi-bin directories and CGI scripts to the world, simply because you're guaranteed to never get a 403 error. This is a mistake, as you would open up many security holes for local users to crawl through. In general, you should set directory and file permissions as restrictively as possible while still allowing everything to run |
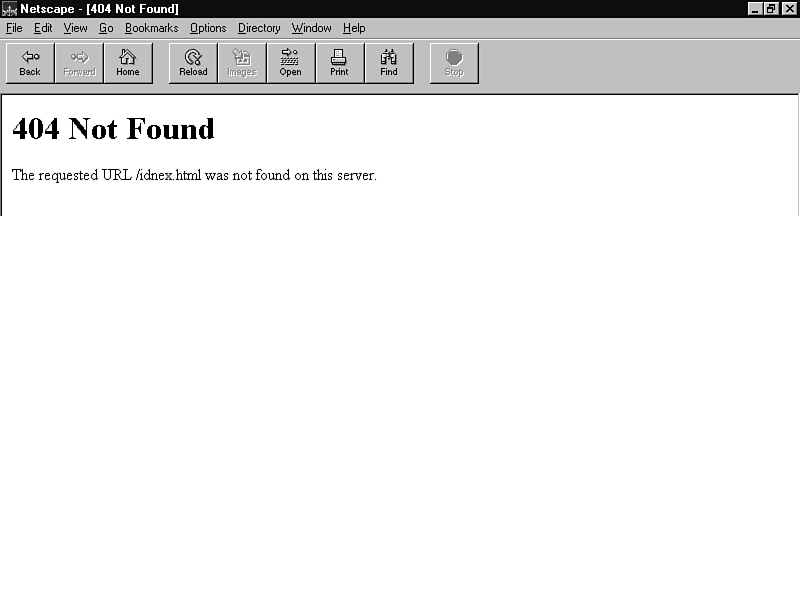
After correcting the permissions on your script and the directories that contain it, return to your browser and try to execute the CGI program again. This time, your browser might tell you that the server returned a 404 error (see fig. 25.5).
Figure 25.5 : A user encounters server error 404.
Error 404 simply means "Not found." The server
is telling your browser that it can't find the HTML file it was
asked to return, or the CGI script it was asked to execute. In
all likelihood, you've just mistyped the URL, either in the HREF
of a hyperlink or in your browser's Go To field. Simply correct
it and you're on your way.
| TIP |
If you're sure you typed the URL correctly, you should double-check your server to make sure that the HTML file or CGI script is installed where you expect it to be installed and is named what you expect it to be named. The cause of a seemingly intractable problem might simply be that something got moved or deleted accidentally |
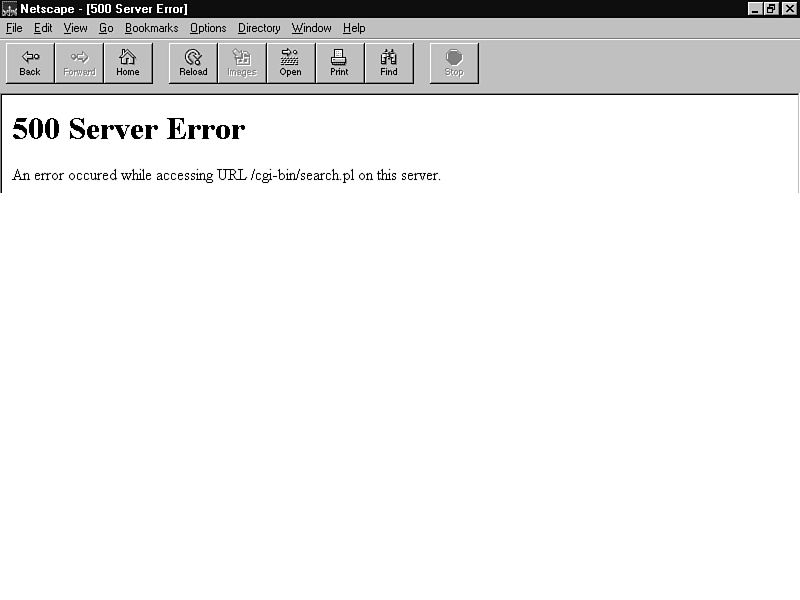
Finally, it's possible for the server to return one last error-500 (see fig. 25.6). A 500 means that a general, undefined error occurred; your Web software is saying "I got confused and didn't know what to do." While your Web browser may consider this a good enough reason not to display your CGI script's output, it doesn't help you much-unless you know that error 500 almost always occurs for only one reason: handshaking with your CGI script has failed.
When the Web server receives a request to run a CGI script, it executes that program and communicates with it in a very specific, predefined way. When the CGI script tries to communicate back to the server with the data it wants displayed in the Web browser, another very specific format must be followed. If either of these strict protocols aren't adhered to, the server gets lost and gives up on the request, returning a 500.
In truth, because Web servers come preprogrammed, the only place that this handshake can break down is when the CGI script is returning data to the server. And because the data returned is almost entirely free-form-be it flat text, HTML, graphics, or whatever-the only place this part of the handshake can break down is in the HTTP header.
The following script is an example of a simple CGI program that returns error 500, even when all the permissions are set correctly and the URL that references the script is correct.
#!/bin/sh echo "<HTML><HEAD><TITLE>Fortune</TITLE></HEAD><BODY><PRE>" fortune echo "</PRE></BODY></HTML>"
Any time you try to run this script, your browser will give you a 500 error. The reason is simple, and it's a common oversight. Part of returning data to a Web server from a CGI script is including the HTTP header information. This shouldn't be confused with the HTML header information stored between the <HEAD> and </HEAD> tags. The HTTP header lets the Web server know what kind of data it's about to receive. At a minimum, it must consist of the MIME content-type of the data to follow and a blank line.
The following script is a corrected version of the preceding listing. It returns HTTP header information before the actual HTML data and works perfectly if you install it correctly in your cgi-bin directory and run it from your Web browser.
#!/bin/sh echo "Content-type: text/html" echo "" echo "<HTML><HEAD><TITLE>Fortune</TITLE></HEAD><BODY><PRE>" fortune echo "</PRE></BODY></HTML>"
Lines two and three make all the difference. If either is omitted-even the blank line-your server will respond to all references to the script with a disheartening 500.
The most common type of output you'll get from your CGI script is simply incorrect output. It will be HTML and it will appear on-screen, but it won't be what you were expecting. Figure 25.7 is just one possible example.
Discovering how and where your CGI script has gone wrong is the great purpose of testing and the great challenge of debugging. When you reach this stage, you're essentially debugging your CGI script like you've debugged every other program you've ever written. The only difference is that this program has a user interface that runs over the Web rather than be directly connected to your screen.
Any methods that you've found useful in the past for debugging programs will be useful for debugging CGI scripts. Indeed, huge volumes of infor-mation are available about methods and methodologies for testing and debugging, and each and every one of them can be applied to your CGI script: scattered printf()s or MessageBox()s, symbolic debuggers, code isolation, debugging flags…almost anything.
But because of the special circumstances inherent in CGI programming-a Web browser acting as a network-based user interface, input and output passing through the Web server, your CGI script functioning under all the special rules that the previous two conditions imply-a few unique approaches can make testing and debugging easier.
Testing often is assumed to take place while development is going
on. Those making the schedules and those fulfilling them figure
that in the course of writing the software, the coder will run
it repeatedly and discover any bugs that are hidden in the program.
This is, quite simply, a fantasy.
| TIP |
Because testing is so often taken for granted, it's almost always underscheduled. When planning a project, you should set aside a significant portion of your development time to test your script |
The person who writes the code is, in fact, the worst person in the world to test it. When you sat down at your computer to begin programming, you had a specific set of conditions in mind and you wrote your program to handle those conditions. In all probability, you'll test the software with those same assumptions in your head and-no surprise-find nothing wrong.
Ideally, testing is done by people who are familiar with computers,
but not with the application that's being tested. This not only
frees you from the assumptions that might have been made when
the CGI script was being written-regarding the type and form of
the input-but also allows you to test such abstractions as your
user interface and its ease of use.
| TIP |
If you must test your own code, try to shake off the mind-set that you used while programming. Play dumb. Try to forget how the program works and follow the instructions as a new user might |
Also-and ideally-testing should be done in two phases: as an ongoing task while the CGI program is being developed, and as an end-of-cycle task after the code is "frozen." Ongoing testing catches bugs early and prevents them from piling up at the end of the development cycle. This is usually why "the last 10 percent of the work takes 90 percent of the time." You should also spend a good amount of time testing "frozen" code, after you finish making your final changes to it. This allows you to get a good fix on how well your CGI script works without it changing every day, hour, or minute.
There are a few different types of testing, and each has its place in the process of shaking out all the bugs from a program-your CGI script included. There isn't one "best" type of testing; each type has strengths and weaknesses. To ignore any of these strengths or weaknesses increases the probability that something nasty will slip through your safeguards and onto your Web site.
The most common type of testing is single-user testing. When someone sits down in front of a Web browser and starts playing with your Web site and CGI scripts, he's essentially doing single-user testing. In fact, when your Web site goes operational, the entire world will have the opportunity to essentially single-user test your scripts.
There are a couple of advantages to this type of testing:
Because your Web server isn't a single-user environment, such as Microsoft Word or Netscape Navigator, you can't assume that only a single user will be accessing it at a particular moment. For this reason, multiuser testing should be a big part of your overall test strategy and schedule. Where a single user might discover many of the logic errors in your scripts simply by using them, multiuser testing is often good for discovering performance and resource problems.
For instance, if only a single user is running the database query
CGI program, it may work perfectly. But on the Web, a hundred
people may be accessing that script at the same time. (You'd have
to have a very popular site, but it's possible.)
| NOTE |
Popular sites, such as Yahoo and the Netscape home page, receive millions of hits a day. Since there are only 86,400 seconds in a day, these pages are accessed at least a few times a second, all day long. You should be prepared to be so lucky |
A number of problems can arise in heavy-use situations such as this. For instance, if 10 people are executing a database search at the same instant, your Web server might slow to a crawl, and the script that worked so well in single-user testing suddenly looks a lot less speedy.
You may discover resource contention issues where the same CGI program is run by two different users and each instance tries to access the same data, one locking the other out. You may find that some staticly named temporary file is constantly being overwritten with new data from a different user. Or any number of other things could happen.
Multiuser testing brings out bugs that single-user testing simply can't detect. It's much closer to real-world activity and, thus, allows you to discover your mistakes before the Web-at-large does.
Of course, multiuser testing has its drawbacks. Possibly the biggest drawback is that multiuser testing requires multiple users. Just gathering enough people together for a decent test can be an exercise in human resource contention-especially if they're working on their own deadlines. People often are too busy to help you test in any realistic way.
Also, when bugs are uncovered during a multiuser test, it's often much harder to discover what caused them than when they're found during a single-user test. Since the nature of a multiuser test is to introduce the elements of overload and chaos into the system, any bugs that rear their ugly little heads might be reluctant to reappear unless the exact conditions are reproduced.
Both factors are reasons to carefully plan your multiuser test. You should have schedules and suggestions handed out to each participant before the test begins so that you can have some sort of record about how many people were doing what when something went wrong. A carefully planned schedule assures that each feature of your Web site gets the attention you think it deserves.
Also, you'll find people more eager to participate in your test
if it's well organized. Be sure to treat your testers as more
than automatons. They're human beings-and are doing you a favor.
| The Art and Science of the Multiuser Test |
Before a multiuser test begins-before the participants are even selected-you must lay out a battle plan. You should set detailed requirements for the test: how many people you want to participate, what role you want each person to play, how much you expect each person to accomplish. A multiuser test can be a simple as two people working in tandem to make sure that resource contention is correctly handled, or as complex as dozens of people stressing every aspect of your script and site. When you have a vision of what you want the test to be, you should create a schedule-for the group at large and for each participant. You should create basic expectations for each person as to what he or she is to accomplish and how quickly you want it done. Your instructions should be as detailed as possible so that your testers will know what you expect and so you'll have a good idea about what has been achieved when everything is done. Also, precise directions prevent testers from spinning their wheels, wondering what to do next. Next, if you can, hold a group meeting just before the test begins. Explain your rationale for the test and what you hope to get done-spell out your main goal and how each participant will help you move toward it. When the test is under way, consider acting as a roving troubleshooter. Wander among your testers, standing back and watching to see what they have trouble with, and taking part to assure that they don't waste their testing time on irrelevant problems. After the test is over, it's a good idea to hold a post-mortem, to analyze what bugs were found in your CGI script and how the test itself may have been administered better |
The last type of testing you can perform on your CGI scripts is automated. This is far and away the most difficult type of testing to do, because it requires much more than gathering a few people together and asking them to play with your site. To run automated tests, you must first write auto-mated tests, and that can be almost as big a job as writing the CGI scripts themselves.
An automated test pretends that it's a user and makes predefined requests of your CGI program. Then it compares the results produced against those that it expected. If something varies, the reason could be a bug.
There are several ways to create automated tests. Commercial packages such as XRunner and WinRunner allow you to build scripts that control GUIs, so your tests point, click, and enter requests as the user might.
Or, cheaper and perhaps simpler, you might write tests that interact directly with your CGI script, skipping the Web. It's probably a pretty safe assumption that your browser and server will work correctly-they've already been tested-so your real goal is to rigorously run your script without using the Web at all. (See the section "Running from Outside the Server" later in this chapter for more information.)
For instance, your automated test might be as simple as a small program that sets the appropriate environment variables and directs simulated input into the script. The output could be captured and compared against idealized output. Listing 25.1 is an example.
Listing 25.1 A Simple Automated Test
#!/bin/sh
# Set the environment to simulate a request
set DOCUMENT_ROOT=/web/docroot
set SCRIPT_NAME=${0};
set REMOTE_HOST=www.server.com
set REMOTE_ADDR=127.0.0.1
set REQUEST_METHOD=GET
set QUERY_STRING=name=joanne&email=joanne@jojomoco.com
set PATH_INFO=
set PATH_TRANSLATED=${DOCUMENT_ROOT}/${PATH_INFO}
set HTTP_USER_AGENT=Mozilla 2.0
set HTTP_REFERER=http://www.server.com/referrer.html
# Run the script and save the output script.pl > /tmp/script.out
# Compare output (.out) against idealized version (.idl) and
# add it to the report (.rpt)
diff /tmp/script.out script.idl >> /tmp/script.rpt
After listing 25.1 runs, /tmp/script.rpt will contain any differences between the actual output of the script and an idealized version of the output you created by hand earlier-what you expected the resulting HTML to look like. More sophisticated versions of this automated test might read the environment from a configuration file, so many different scenarios can be easily tested. Each scenario, of course, needs separate idealized data to be compared against.
Of course, automated tests can get very involved, nearly equaling the complexity of the programs they were designed to inspect. But for requiring all this effort, they have a couple of unique advantages:
After you decide who's going to test your script-you, somebody else, a group of others, the computer itself, or (hopefully) all of the above-you must still pick a method: shot-gun, methodical, or code-path testing. A large part of setting up a test is defining how it will be conducted, in addition to who will participate.
The simplest but, ultimately, least effective method of testing is shot-gun. You sit down and begin using your script. You may catch bugs this way, but there's no rhyme or reason to the way you proceed from one activity to another.
If you're doing multiuser testing and don't have a schedule or detailed instructions about what your testers should be doing, they will invariably end up doing shot-gun testing-just pointing and clicking randomly until something breaks. Even trying, or telling someone, to "concentrate" on a particular feature will still result in haphazard coverage and an incomplete test.
On the other hand, when people visit your site and begin to use your CGI script, they will essentially be doing something similar to shot-gun testing. They have no motivation to methodically test your site and will make a beeline for whatever feature or information they want. Shot-gun testing most effectively mimics the behavior of real users, and although it won't guarantee the integrity of your script-bugs hide and must be hunted down-it's quick and simple.
More effective than shot-gun testing is methodical testing. When you-or those participating in your multiuser runs-test methodically, you can get a clearer picture of how each part of your CGI script performs, since you'll have a clearer picture of what has been tested and, as a result, what failed.
Methodical testing usually involves a list of commands, often confusingly referred to as a script (as in movie script). A tester takes the script and follows each command listed, in the order listed. Often, creating and using these test scripts is a tedious process, as it requires nothing but simple, mechanical interaction. Whereas shot-gun testing can be a creative process, with each user trying something random, methodical testing is often exactly the opposite. Although the results of a methodical test are much more useful, because you know exactly what has been tested, performing one can be painful.
Methodical testing has many advantages. Perhaps its biggest advantage is that it can be run as an automated test. Computers specialize in repeatedly performing (often mindless) activities, without raising one word of protest. Although a computer would be lousy at the randomness and creativity that shot-gun testing requires, computer-run automated tests fit perfectly with a more methodical approach.
Again, automated tests are often difficult to build, but imagine being able to run them whenever you feel like it, allowing you to get the latest information about which features work and which don't, and how those that don't are broken. You'd also have information about exactly how those features were tested, which can be just as valuable and is often difficult to pry out of a human tester who can't remember.
The ultimate in methodical testing is the form that's most ideally suited to be run by automated tests: the code-path test.
Whereas shot-gun testing is essentially random, and methodical
testing executes predefined commands in a predefined order, code-path
testing tests everything in your CGI script. When you test
code paths, you make sure that you execute every line of code
in your program, no matter how obscure.
| NOTE |
Many dedicated programmers perform code-path tests on their code the instant they write it. Although this can be very time-consuming, it can dramatically cut down on the number of bugs |
Code-path testing requires people who know how to program to have a printout of your CGI script next to them as they work. This allows them to read it and create the conditions that cause every path-every subroutine, every conditional, every loop-in your code to be run and tested.
Of course, as tedious as methodical testing can be, code-path testing is even harder. If following a general script of commands is difficult, imagine following the most detailed orders imaginable-the code itself. A human would slowly go crazy getting each and every line in your script to execute under as many different conditions as possible.
This is where automated testing really shines. A computer will happily test a thousand features and never issue a beep of complaint. While a human might decide that he has been over a particular feature enough, a computer will test and retest until you decide that it's done.
Of course, someone must write the automated code-path tests, which can be a huge endeavor. Often, programs to test each and every feature of another program, with as great a variety of input-good and bad-as possible, can balloon to many times the size of the original code.
Also, you must keep the test program updated. If a feature is
added to your CGI script, you must update your methodical test
program to attack that feature. Simple enough. But if you're trying
to maintain a test program that follows each code path, you must
update it every time you change the program, not just add
a feature. It can get very tiresome, and many people who try to
maintain such test programs often let them slip out of date and
into uselessness. Those that don't, however, often have the most
robust, bug-free code imaginable.
| It's a Big Job, But Somebody Has to Do It |
Some companies hire developers who do nothing but write automated test programs. Although they may work with any number of true testers, they spend most of their time writing code that's used only in testing other developers' output. Ideally, each test coder attends all the design meetings and is often more up-to-date about feature lists than the programmers themselves. Test coders can read all the code that's created and understand how it might be tested. They're not only responsible for creating the test programs but also for keeping them updated. If your company or organization is really serious about quality, it might want to con-sider such an approach. Your boss may be reluctant to use such a good programmer in a "side" capacity-one that doesn't directly contribute to the bottom line of new features and timely delivery-but it's ultimately worth it in improved quality, reduced bug counts, and user confidence |
When you run your tests, be they single-user shot-gun or automated code-path, make sure that they don't run on real data-information that's important and irretrievable. Remember that you're testing, and the information you use-databases, graphics, the CGI scripts themselves-is liable to have anything happen to it. An untested program is a bomb, just waiting for a match to light its fuse. And unrecoverable information should be nowhere near the blast radius.
As stated earlier, you should test your CGI scripts on an isolated machine, removed from the Web at large. But you should also make sure that the data you're using to test with are all copies, easily replaceable if something happens to them.
Realistic but non-critical data is often called non-production data. It's used to mimic the situations that a user who logs on to your Web site will encounter, but has none of the irreplaceability that real information might have.
The easiest way to create non-production data is to simply copy existing data, if you have any available. If, for example, you're modifying your CGI script to add features, you might simply copy the existing database that the program acts on and use that as the sample data for testing. If you're testing a new CGI script, you need to create this information by hand, building sample databases or configuration files.
Of course, an easy way to create this data is to use your program. As data is added in tests, it can be used by other tests further down the road.
Non-production data is absolutely vital for complete testing, and you should use it wherever possible. For instance, if your CGI script queries a database, something must be in the database to search-it should be as realistic as possible, but it should also be entirely replaceable, totally non-critical.
Automated tests also require non-production data. Because a computer can't interpret the information that's sent back from your script, the best an automated test can do is match the output-character for character-against expected results. That means that the data the automated test is acting on must be predefined and regular. Non-production data is the best way to accomplish that.
After you put in all the effort required to properly test your CGI program, the last thing you probably want to do is record how you did it. As with almost any type of documentation, the chronicling of testing-who did what and how-can be tedious. But like other types of documentation, it's absolutely necessary.
Although the job may be boring, the end result is invaluable. When you have a list of what features were tested, how they were tested, and what the ultimate output was, you can use this as historical information for future updates, saving yourself time and trouble down the road.
You can document your testing in two ways: by hand and automatically.
You can record a log of your tests by hand, writing down each idea you have and each path your test took. Such a log is priceless when problems arise, because you can review where the bug slipped through your testing and how you can prevent something similar from happening in the future.
A log of your testing procedure is also invaluable if you must repeat your tests. If you're doing shot-gun testing, having to go back and cover everything that you did previously is nearly impossible. Of course, if you wrote a script of testing instructions, these function almost exactly as hand-written logs of your test actions and would make an effective substitute, killing two birds with one stone. The code for automated tests also can be used this way, as incredibly detailed testing documentation written in an obscure language.
Using testing scripts or automated testing code as documentation has one big disadvantage-neither records the results of your tests. Although they may work perfectly as a log of what actions your tests consisted of, they do nothing to help you remember the results.
One solution to this problem is to have the computer remember the results for you. If, in the course of writing your CGI script, you've sprinkled debugging statements throughout your code, you can use their output as a record of not only how the script ran, but of what the input and output was. (For more information on how to do this, see the later section "The Error Log.")
Automatic documentation logs, like automated test programs, can take a lot more up-front effort than simply sitting down and testing your CGI script. But in the end, after you factor in all the time and effort you'll waste trying to remember how you accomplished something or what the result of a particular test was, you'll find that they're both well worth the labor. Taking the time to let the computer do what it's good at-repeated action, methodical record-keeping-is almost always the right way to go.
Now that your testing is done and you have a list of malfunctions and misbehaviors in your CGI program, you need to enter the debugging phase of software development.
Debugging can be the hardest part of the development cycle; it's easily the most frustrating. A few programmers, at the end of their ropes, simply throw up their hands and want nothing to do with the debugging process. Unfortunately, the code these programmers produce is almost never right, and if there's one thing worse than debugging code, it's using code that hasn't been debugged.
Under normal circumstances, debugging can be maddening. Under the limitations that CGI scripts place on you, it can be even worse.
The trouble with debugging CGI scripts is that they aren't used like normal applications. If a normal program you're writing has a problem, you can simply run it inside a debugger and find where the problem occurs.
But for CGI scripts, since they're launched by the Web server, you don't have this luxury. Because CGI scripts don't run with their input and output attached to the keyboard and the terminal, they can't be interacted with while running, by you or by a debugger.
So, for instance, even though Perl comes with a great built-in debugger, you can't use it. Running a Perl program in debug mode as a CGI script simply causes the debugger to read from standard in (stdin), gobbling any user input sent from a POST METHOD instead of the expected debug commands. Also, any debugger output would be sent to standard out (stdout), and thus down to the browser, or to standard error (stderr), which is deposited in the error log (see the next section, "The Error Log").
Under UNIX and Windows NT, it's possible to "attach" a debugger to a C program that's already running, but it can be difficult and time-consuming. And many CGI scripts execute so fast-you don't want to keep the user waiting-that the debugger doesn't even have time to load before the CGI script is finished and the process is gone.
Fortunately, there are some more primitive options than a fancy symbolic debugger that you can use to get the job done.
Your Web server keeps many logs of information about itself and about the browsers that connect to it. For instance, the National Center for Supercom-puting Application's (NCSA) HTTPd Web server not only keeps access_log (a list of machines that have contacted your site and the pages they've read), referer_log (a list of the pages that referred a browser to your site), agent_log (a list of the browser types that have visited), but also error_log.
The error log is a list of all the troubles anyone might have had accessing the pages on your site. It's where your Web server records all the problems it has had since it first started up-including, happily enough, problems with CGI scripts.
For instance, listing 25.2 is an example of what part of the error log might look like if the CGI script find.pl failed to run. If you tried to access find.pl through a Web browser, a failure like this would only report a 500 error, leaving you to guess at the cause. But by checking in the error log, you can find out what really happened.
Listing 25.2 An Extract from the Error Log
[Thu Jan 11 16:30:42 1996] httpd: malformed header from script parse error in file /usr/local/httpd/cgi-bin/find.pl at line 426, next 2 tokens "were found" Search pattern not terminated in file /usr/local/httpd/cgi-bin/find.pl at line 436, next char ^> (Might be a runaway multi-line "" string starting on line 435) parse error in file /usr/local/httpd/cgi-bin/find.pl at line 453, next token "}" Execution of /usr/local/httpd/cgi-bin/find.pl aborted due to compilation errors.
The first line, with the timestamp, is the complaint from the Web server about why it couldn't continue. The rest of the entry is the output from Perl, describing why it failed. From the looks of this particular error, the CGI programmer forgot to close a quoted string on line 435. A simple mistake, but imagine trying to track such a thing down if your only clue is the message 500 (internal error).
What do you do if your script gets far enough to actually generate output to the Web browser? What if it correctly handshakes with the server, thus allowing output to be sent, but that output is all wrong? How do you track down bugs then?
The error log can still be useful in this situation. Anything your program sends to standard error (stderr) is dumped to the error_log, whether your script works as planned or not. This allows you to print debugging information to the error_log even if your program is working perfectly.
One good thing to do when writing or debugging your code is to sprinkle it liberally with status messages-information about what's going on, the values of important variables, how things are, and how they actually should be. That way, if there's a problem, you'll have a record of what happened where, making it much easier to track the problem down and kill the bug that's responsible.
Of course, you want to include a way to turn off these messages after all the kinks are worked out of your program. The best way to handle this is with a debugging flag. A debugging flag is a variable used only to control the output of your debug statements. If your script is having trouble, you can turn the flag on to track the flow of your code and find the problem. If your code is working perfectly, you leave it off and nothing is dumped into the log.
Listing 25.3 shows the most common method of implementing a debugging flag.
Listing 25.3 One Example of a Debugging Flag
# Turn the flag on
$debug_Flag = 1;
# Some code
print STDERR ("Output header\n") if $debug_Flag;
print("Content-type: text/html\n\n");
print STDERR ("Loop through %user_Info array\n") if $debug_Flag;
foreach $user_Key sort(keys(%user_Info))
{
print STDERR ("\"$user_Key\" = \"$user_Info{$user_Key}\"\n")
if $debug_Flag;
if (...
With this method, a debug statement is printed if $debug_Flag is set to anything other than 0. By adding such statements to your code, you can enable and disable a program trace as needed.
Listing 25.4 is, perhaps, a better implementation of the same idea.
Listing 25.4 Another Example of a Debugging Flag
# The current debug level
$debug_Level = 2;
# Print debugging status
sub debug_Print
{
if ($debug_Level >= $_[0])
{
print STDERR ("@_[1..@_]\n");
}
}
# Some code
&debug_Print(1,"Output header");
print("Content-type: text/html\n\n");
&debug_Print(2,"Loop through %user_Info array");
foreach $user_Key sort(keys(%user_Info))
{
&debug_Print(3,"\t\"$user_Key\" = \"$user_Info{$user_Key}\"");
if (...
In this case, the subroutine debug_Print() takes the level of importance a particular debug statement is assigned and the actual statement itself. If the level of debugging that you're now interested in is equal to or greater than the level you've set for a piece of information, it's dumped out to the error log, which would look like this:
Output header Loop through %user_Info array
Note that error_log doesn't contain information sent by debug_Print() inside the loop. Its importance is rated a 3, and you're interested only in those rated a 2 or better. If you were to change $debug_Level to 3, the following would be the result:
Output header
Loop through %user_Info array
"foo" = "bar"
"pants" = "funny"
"llama" = "loon"
By using a system like this, you can vary how much debug detail your script generates. $debug_Level can also be set higher before troublesome sections of code, and then lowered again later. And, of course, debug_Print() can be expanded and improved-for example, it might (and probably should) time-stamp each line of output.
The only thing that really matters-whatever method you use-is that information about the execution of the program is placed in the error log. How you do it is largely a question of style and need.
Perhaps the best way to debug your CGI script is to forget that it's a CGI script at all. By removing the Web-both the browser and the server-from the equation, you gain a lot of flexibility in your debugging, and more traditional, convenient methods return to the process.
When the Web server executes your CGI script, it simply sets several environment variables and, perhaps, places some information on your program's standard in (stdin). These steps are easy for you to duplicate yourself, and the process gives you an atmosphere where traditional debuggers can be used and output is dumped to your screen instead of to the error log.
Table 25.1 lists all the environment variables that are set when
the Web server runs a CGI script. Others may be set, of course,
but they're related to the shell and the startup environment of
your server.
| Environment Variable | Contents |
| SERVER_NAME | The Internet name of your server machine |
| SERVER_PORT | The port where the browser attached to your server |
| SERVER_SOFTWARE | The name and version of your server software |
| SERVER_PROTOCOL | The protocol your server is using to talk to the browser |
| GATEWAY_INTERFACE | The protocol your server is using to talk to your CGI script |
| DOCUMENT_ROOT | The root path where your Web files are installed |
| SCRIPT_NAME | The file name of the CGI script that's now running |
| REMOTE_HOST | The Internet name of the browser's machine (may be empty) |
| REMOTE_ADDR | The Internet address of the browser's machine |
| REQUEST_METHOD | The method form data has been submitted (GET or POST) |
| CONTENT_TYPE | The MIME type of the submitted form data |
| QUERY_STRING | The encoded form data, if REQUEST_METHOD is GET |
| CONTENT_LENGTH | The length of the form data waiting on standard in (stdin), if REQUEST_METHOD is POST |
| PATH_INFO | The path information that followed the script name in the URL |
| PATH_TRANSLATED | The path information that followed the script name in the URL with DOCUMENT_ROOT prepended |
| HTTP_USER_AGENT | The name and version of the browser software |
| HTTP_REFERER | The URL of the page that the browser visited before the CGI script |
Perhaps the best way to see the value these variables normally have is to write a small CGI script, install, and run it. Listing 25.5 is such a program and, when run, will show you each variable listed in table 25.1 and the values they have in a "real" situation.
Listing 25.5 A CGI Script to Show its Environment
#!/bin/sh echo "Content-type: text/html" echo "" echo "<HTML><HEAD><TITLE>Environment</TITLE></HEAD><BODY><HR><PRE>" env echo "</PRE></BODY></HTML>"
Just as the Web server sets the variables before it executes a CGI script, you can define them yourself-with setenv or set-and execute your CGI script by hand. Of course, if your script doesn't use a particular environment variable, you don't need to set it. If your script doesn't take any form input, it will execute as it would normally, but with the output sent to the screen instead of back to the Web browser. Because the Web is now out of the loop, you can eyeball the resulting HTML for errors, run the script inside a de-bugger, or do any number of other bug-tracking methods.
The situation gets a little more complicated if you're trying to simulate form input to your script.
Listing 25.6 is an HTML page that, when run with listing 25.5, will show you what the environment variable QUERY_STRING is set to for the included form. This, like the other variables, can be set by hand before the script is executed outside the context of the Web server. If you choose to dummy a value in QUERY_STRING to simulate submitting form data to your script, you must be sure to set REQUEST_METHOD to GET, because that's what the Web server would do.
Listing 25.6 Submitting a Query to Listing 25.5
<HTML>
<HEAD><TITLE>A Simple Form</TITLE></HEAD>
<BODY>Please enter some data:<P>
<FORM METHOD="GET" ACTION="/cgi-bin/show_env.sh">
<INPUT TYPE="TEXT" NAME="text"
VALUE="Some sample text">
</FORM>
</BODY>
</HTML>
Simulating the POST METHOD is even more complicated. You must take what a Web browser would normally try to send to your script's standard in (stdin) and save it off to a file. Then, when you run your CGI script outside the Web server, you must redirect this file into your script as though it were being sent from the server.
Listing 25.7 is a form that will submit data to listing 25.8, which then saves the form data away for later use.
Listing 25.7 A POST METHOD Form
<HTML>
<HEAD><TITLE>A POST METHOD Form</TITLE></HEAD>
<BODY>Please enter some data:<P>
<FORM METHOD="POST" ACTION="/cgi-bin/savepost.pl">
<INPUT TYPE="TEXT" NAME="text"
VALUE="Some sample text">
</FORM>
</BODY>
</HTML>
Listing 25.8 A Script to Save Data Submitted from a POST METHOD Form
#!/usr/bin/perl
# Where the form data is dumped
$dump_File = "savepost.dat";
# Output header
print("Content-type: text/html\n\n");
# Dump the input to a file
if ($ENV{"REQUEST_TYPE"} eq "POST")
{
if (read(STDIN,$dump_Output,$ENV{"CONTENT_LENGTH"})
{
if (open(DUMP_FILE,">$dump_File"))
{
print DUMP_FILE ("$dump_Output");
close(DUMP_FILE);
print("<HTML><HEAD><TITLE>");
print("POST METHOD Dump");
print("</TITLE></HEAD><BODY>\n");
print("POST METHOD output dumped to $dump_File.\n");
print("</BODY></HTML>")
exit(0);
}
}
}
print("<HTML><HEAD><TITLE>");
print("POST METHOD Dump Error");
print("</TITLE></HEAD><BODY>\n");
print("Something went wrong...\n</BODY></HTML>");
exit(-1);
After collecting the form data that the browser sent to the server and the server passed onto your script, you simply need to redirect this information to your CGI program by hand. Under UNIX and Windows NT, you can do this with a single command: myscript.pl < savepost.dat.
Although capturing form input and setting environment variables by hand may seem like a lot of work to debug a script, it's often worth it, allowing you options that aren't available when your CGI program executes from within the Web server.
Perhaps the most important thing to keep in mind while debugging your CGI programs is to remain creative. Sometimes, a quick glance at the error_log tells you instantly what's malfunctioned in your script; other times, you have to reproduce exactly the server's environment to track down a pesky bug. But in either case, knowing where and how to look remains the most important thing. You should debug like you should program-flexibly, thoughtfully, and with an eye turned toward the solution that works best for you.
After your script is tested and debugged, you must pay one last consideration-how the script interacts with itself and the server it runs on.
Most of your testing probably has focused a single occurrence of your CGI script running on trial data. This is usually the case with either single-user or automated testing. The test is run on some sample information and everything appears to work perfectly. But how will the script-and the machine it's running on-react if a hundred copies of it are executed at once on more realistic data?
Remember, the Web is a multiuser environment, and it's within the realm of possibility that any number of people will be using your script at the same time. Although Web servers are designed to execute your CGI program as many times as needed, how the script performs under those circumstances is an entirely separate issue.
It's a common mistake to write CGI scripts so that they busy loop, or aggressively go about their task, no matter how long it takes, with no consideration for other programs running on the same machine. On a UNIX server, the loop in listing 25.9 will run forever, raising the CPU usage to 100 percent and slowing any other programs that are executing.
Listing 25.9 A Busy Loop
int main()
{
int dummy_Var = 0;
for (;;)
{
dummy_Var++;
}
}
A busy loop, of course, doesn't need to run forever, as this example
does. It can be any piece of code that eats more than its fair
share of CPU time, causing other programs to slow down. Even a
small program can busy loop; although its effects may not be noticeable
with only one instance of the program running, when magnified
over dozens of instances, it becomes very noticeable.
| To Err Is Human |
As an experienced UNIX programmer, I should have anticipated the problem. I had written a CGI program to search a local database for matches to a user query. Everything appeared to work well in my testing, so I packed up my program and carted it off to the company I had written it for. We installed the script on their test machine and ran it. My little program brought their machine-a fancy, multiprocessor UNIX box-to its knees. I was incredibly embarrassed, because I had made two stupid mistakes. First, I had tested my program on an unrealistic data set. I had created a small database to search and not thought about the impact of having to run through hundreds of megabytes-a stupid mistake, perhaps, but not what I was most embarrassed about. I was most embarrassed about having created a busy loop. As my program slowly ground through their huge database, it slowed everything else that was running on the machine down…to a crawl Writing a bad CGI script is one thing, but writing it so that it affects other, better-written scripts is worse. |
Easing the impact of a busy loop is simple, but it must be handled carefully. Your program must be willing to give some time back to the system, but not so much that it runs too slowly. For example, if listing 25.9 had been changed just slightly, as listing 25.10 has been, it would have eaten almost no CPU time.
Listing 25.10 Not a Busy Loop
int main()
{
int dummy_Var = 0;
for (;;)
{
dummy_Var++;
sleep(1);
}
}
The difference between listing 25.9 and listing 25.10 is the UNIX sleep() command, which causes a program to pause for the number of seconds specified. Under Visual C on Windows NT and Windows 95, the function call is Sleep() and it specifies the number of microseconds to pause.
When your program is asleep, it not only doesn't do anything, but it gives the time that it's not using back to the machine so it can be doled out to the other running programs.
To prevent busy loops in your CGI scripts, you need to make sure that any time your program may loop, it offers the operating system a chance to take some time. There are actually dozens of calls that do this, such as read(), write(), fread(), and fwrite(). Almost any function that invokes some operating system-provided service has an escape in it to keep your program's CPU usage as low as possible.
In fact, Perl and C's select() call (which shouldn't be confused with the single-argument select(), also available in Perl) lets you control how long your program sleeps with much greater precision than the 1-second accuracy of sleep(). The following script is Perl code that counts to a thousand (very inefficiently) and contains a busy loop that pegs the CPU at 100 percent-not for very long, but it happens.
#!/usr/local/perl
for ($count_Index = 0;$count_Index < 1000;$count_Index++)
{
$count_Number++;
}
print("Final count: $count_Number\n");
The following script introduces a sleep() call, which prevents the CPU usage from climbing out of control, but causes the script to take a thousand seconds to execute. Not good.
#!/usr/local/perl
for ($count_Index = 0;$count_Index < 1000;$count_Index++)
{
$count_Number++;
sleep(1);
}
print("Final count: $count_Number\n");
The next script uses the select() call, instead of sleep(), to still give time up to the CPU, but not nearly so much. The impact of the loop on the machine as a whole is still negligible-as it was with sleep()-but now the user doesn't have to wait almost 17 minutes for the program to finish. In fact, from all appearances, it executes just as fast as without the select().
#!/usr/local/perl
for ($count_Index = 0;$count_Index < 1000;$count_Index++)
{
$count_Number++;
select(undef,undef,undef,0.01);
}
print("Final count: $count_Number\n");
The impact your script has on the server that runs it is almost as important as what features it offers and what services it can perform. A slow CGI program that does everything you need can be almost as frustrating as a fast one that doesn't.
The best way to measure server impact is through multiuser (be they human or automated users) testing on realistic, non-production data. You'll be surprised how many things you can catch if you follow a full-fledged test plan.