{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by David Harlan
Perl and the World Wide Web are a natural team. A good Web site is, by definition, in constant flux. Users will not want to come back to a boring site too often, so all Webmasters are looking for any possible means to liven up their sites. The liveliest sites are dynamic sites-sites that show users different content from visit to visit. These types of sites also enable users to interact or create content on-the-fly.
Because you're reading this book, you're probably wondering just how to create a dynamic Web site. You're in the right place. Basically, the Webmaster has to become a programmer and use some of the great built-in features of the Web protocol to their fullest. To this end, a programmer has to have a language that facilitates quick programming, easy debugging, and fast revision. Perl fits this role perfectly.
When you started looking at Web sites, one of the first items that you probably were curious about was the .htmL extension on the files. Soon, you found out that HTML stands for Hypertext Markup Language, and you discovered that HTML is the foundation on which the Web is built. If you were interested in building your own Web site, you probably looked next at the source of a few Web sites to see how they were built. At that point, you may have exhausted your resources. But that's OK, because you discovered that HTML is not difficult to use. Strangely, this fact may be the Web's greatest advantage, as well as its major shortcoming.
Almost anyone can throw together some HTML and hang a home page out on the Web. But most sites are, quite frankly, boring. Why? Most sites are built as a simple series of HTML documents that never change; the sites are completely static. No one is likely to visit a static page more than once or twice. Think about the sites that you visit most often. Those sites have interesting content, certainly, but more important, they also have dynamic and interactive content.
What's a Webmaster to do? None of us has the time to update a Web site by hand every day. Fortunately, the people who developed the Web protocol thought of this problem and gave us the Common Gateway Interface, or CGI. CGI, which is the standard programming interface to Web servers, gives us a way to make our sites dynamic and interactive. To be specific, CGI is a set of standards (in Internet lingo, a set of protocols) that allows Web servers to communicate with external programs.
The reason why I use Perl for my CGI programming is simple: it is the best tool for the job.
Perl is the de facto standard for CGI programming for several reasons, but perhaps the most important are the language's flexibility and ease of use. The primary reason why Perl is so easy to use is that it is an interpreted language-which means that every time you run a Perl program, a separate program called (appropriately enough) an interpreter starts and processes the code in your Perl script. An interpreted language differs from a compiled language, such as C, in which you have to (not surprisingly) compile your code into an executable file before you can run it.
Why is the Perl way better? In some cases, C may be preferable to Perl. At times, you may not want the overhead of the interpreter and prefer a stand-alone executable. (I haven't run into those situations yet, but I'm sure that they exist.) The advantage of using an interpreted language in CGI applications is the language's simplicity in development, debugging, and revision. With the compilation step removed, you and I can move more quickly from task to task without the frustration that sometimes arises from debugging compiled programs.
Not just any interpreted language will do, of course. Perl has the distinct advantage of having an extremely rich and capable functionality.
When I started programming CGI scripts, few resources were available to help me. Unlike viewing the HTML source of a document, you cannot get a browser to show you the script that produced any given result on your browser. (For security reasons, this situation is good; it just makes learning a little more difficult.) So, like many CGI programmers, I learned by trial and error. The next few pages should help you avoid this frustrating process and move quickly to more advanced topics.
You need a few basic pieces of information before you successfully program a CGI script:
Unlike normal HTML files that are simply called up by a browser, a CGI script can be used in several ways. The most common use of CGI is for processing user input. (You probably have seen other uses of CGI without even knowing it.) This section takes a detailed look at that most common use of CGI: the fill-out form. In the next few pages, you'll see a form application being built from the ground up.
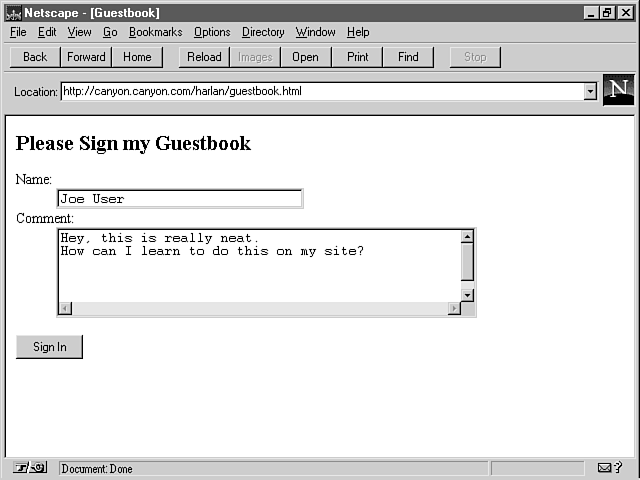
Undoubtedly, one of the first uses of CGI that you experienced was filling out and submitting a form. Perhaps that form looked something like the Guestbook sign-in form shown in figure 2.1.
Figure 2.1 : This form allows a user to sign a Guestbook on a Web site.
When the proper script support this simple form, it performs its function easily. You may be wondering how to call a script from this form. Listing 2.1 contains the source for this form and shows you where the script is referenced.
Listing 2.1 Calling a CGI Script (GUESTBOOK.htmL)
<html> <body bgcolor="#FFFFFF"> <title>Guestbook</title> <h2>Please Sign My Guestbook</h2> <form method=get action="/cgi-bin/harlan/guestbook"> <dt>Name:<br> <dd><input type=text name=name size=30> <dt>Comment:<br> <dd><textarea name=comment rows=5 cols=50></textarea><p> <input type=submit value="Sign In"> </form> </html>
In line 4 of the HTML code in Listing 2.1, you see the following:
...action="/cgi-bin/harlan/guestbook"...
This line tells the form what script to call to process the entered information.
The location /CGI-BIN/HARLAN/GUESTBOOK is what's called a virtual path. The actual location of the script on the Web server computer depends on the configuration of the server software and the type of computer that is being used. In this case, the computer uses the Linux operating system and is running the NCSA Web server in a standard configuration. The physical path to the script in this case is /USR/LOCAL/ETC/HTTPD/CGI-BIN/HARLAN. Although a nearly infinite number of combinations of operating systems and Web servers is possible, the Linux/NCSA combination is relatively common. If you install and administer the Web server yourself, you know exactly where to place your scripts. If you are using a service provider's Web server, you may have to ask the server's administrator where to put your scripts and how to reference them from your documents.
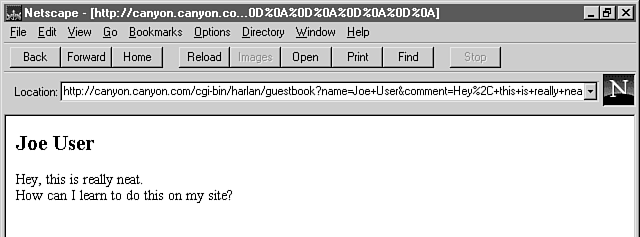
What happens if you sign this Guestbook? In its simplest form, the result of signing the book looks like figure 2.2.
Figure 2.2 : This screen shows the result of the Guestbook form submission.
To understand how submitting the form in figure 2.1 produces the result shown in figure 2.2, you first need to know how information is passed from the form to your Perl script.
Perl provides a special variable called %ENV. This variable is an associative array, or hash-essentially, a list of identifiers or keys and their associated values. I'll explain the syntax of a Perl hash later in this chapter. For now, look at the contents of %ENV. This particular hash contains information about the script's environment. If you have UNIX experience, you may have heard of environment variables. A UNIX user can set certain options, such as a default editor or default shell, by using environment variables.
A Perl script also has an environment. Much of the environment is inherited from the server that's running the script, but a CGI script gets some additional goodies. The CGI specification tells Web server software to provide a wealth of useful information to CGI scripts.
Using QUERY_STRING Perhaps the most-used CGI environment variable is QUERY_STRING. When a form is submitted, the Web server software processes the information that the user provided in the form and passes that information to the script specified in the form. The processing isn't too complex. Spaces in the data are replaced by plus signs, and special characters are translated into a code that is related to their ASCII value; then all the data is put together in one long string.
When the script is called with the GET method (as the Guestbook script is; see line 5 of Listing 2.1), the server places the string described earlier in the QUERY_STRING variable. Because this variable becomes part of the script's environment, you can access it through %ENV, as you'll see later in this chapter.
Using Other CGI Variables Several variables
in addition to QUERY_STRING are provided in the CGI specification.
Some of the descriptions may not make much sense to you right
now. But if you refer to Table 2.1 periodically as you continue
to read this book, you'll discover just how useful some of this
information is.
| Variable Name | Description |
| AUTH_TYPE | The authentication protocol that is currently being used. This variable is defined only if the server supports authentication and if authentication is required for access to the script. |
| CONTENT_LENGTH | The length, in bytes, of the content provided to the script in STDIN. This variable is used particularly in POST-method form processing. |
| CONTENT_TYPE | The type of content contained in STDIN. This variable is used for POST-method form processing. |
| GATEWAY_INTERFACE | The version of CGI supported by the Web server. |
| HTTP_ACCEPT | A comma-separated list of MIME types that the browser software accepts. You might check this variable to see whether the client will accept a certain kind of graphic file. |
| HTTP_USER_AGENT | The browser software and version number. |
| PATH_INFO | Extra path information from the request. |
| PATH_TRANSLATED | Maps the script's virtual path (from the root of the server directory, for example) to a physical path that could be used to call the script. |
| QUERY_STRING | A string containing the data from a form submission. |
| REMOTE_ADDR | The IP address of the client machine. |
| REMOTE_HOST | The host name of the client machine. |
| REMOTE_USER | The authenticated user ID of the user who is requesting the script. This variable is defined only if the server supports authentication and if authentication is required for access to the script. |
| REQUEST_METHOD | The method by which the script was called (most often, GET or POST). |
| SCRIPT_NAME | The virtual path to the script. |
| SERVER_NAME | The configured host name for the server (usually, www.something.com). |
| SERVER_PORT | The number of the port on which the server software is "listening" (usually, 80, the default Web port). |
| SERVER_PROTOCOL | The version of the Web protocol that this server uses. |
| SERVER_SOFTWARE | The name and version of the Web server software. |
Now that you know where the information comes from, you're ready to learn how you might use Perl to process this information. The script that performs the transformation from figure 2.1 to figure 2.2 actually is quite simple and is shown in Listing 2.2.
Listing 2.2 The First Guestbook Script (GUESTBOOK1.PL)
#!/usr/bin/perl
$temp=$ENV{'QUERY_STRING'};
@pairs=split(/&/,$temp);
foreach $item(@pairs) {
($key,$content)=split (/=/,$item,2);
$content=~tr/+/ /;
$content=~ s/%(..)/pack("c",hex($1))/ge;
$fields{$key}=$content;
}
print "Content-type: text/html\n\n";
print "<body bgcolor=\"#FFFFFF\">\n";
print "<h2>$fields{'name'}</h2>\n";
print "<pre>$fields{'comment'}</pre>\n";
The next few pages examine this script line by line.
Line 1 is a line that you need to use in every Perl script that
you write for your Web site. This line tells the operating system
that the script must be processed by the program listed after
the exclamation point. In this example, /USR/BIN/PERL is the location
of the Perl interpreter on my Web server computer.
| NOTE |
The #!/usr/bin/perl line in Listing 2.2 is needed only for UNIX and UNIX-variant versions of Perl. If your Web server is running another operating system (such as Windows NT or Macintosh System software), you need to check your Web server documentation for information on how to invoke CGI scripts. |
When the user submits the form, the Web server software passes the information to the script in the $ENV{'QUERY_STRING'} variable. Line 2 of the script copies this information to the variable $temp. The Perl syntax is straightforward; this line is a simple assignment of one variable to another. $temp is a scalar variable-the most common Perl variable. A scalar variable can contain almost any kind of data you can imagine. $ENV{'QUERY_STRING'} refers to an element in the associative array %ENV, which is described in "Getting Information to the Script" earlier in this chapter.
An associative array (designated in Perl with a leading %) contains a series of scalar values. Each value is associated with a key. In this example, the key is QUERY_STRING, and the value is the encoded data from the form. (I performed this assignment for purposes of readability; the step is not strictly necessary.)
Line 3 of the script splits the data from the script into an array of strings: @pairs. Notice that this kind of array is different from %ENV. The @pairs array is a standard array that uses integers (starting at 0) to designate each separate element. Each element is a string that contains the variable name from the form, followed by an equal sign, followed by the text that the user entered at that spot in the form.
split() is a standard Perl function that takes two required parameters and one optional one. The first parameter is the string that separates the values that are to be split. The CGI protocol specification states that key/value pairs are separated by an ampersand (&), so in this example, the ampersand character is the first parameter. The second parameter is the string that you want to split ($temp). The optional third parameter (not present in this example) is a number that indicates the maximum number of times that the string should be split.
Lines 4 through 9 of the script run through the newly created @pairs array, processing the information from the form into a new associative array to be used in the following lines.
Line 4 starts a loop structure. This particular loop-a foreach
loop-iterates through the @pairs array, placing each
value in turn in the $item scalar variable. The commands
between the brace on line 4 and the one on line 8 are executed
one time for each item in the array.
| Using Shortcuts and Writing Readable Perl Code |
When reading another programmer's code, an inexperienced programmer sometimes finds various incarnations of foreach loops to be confusing. Many Perl programmers pride themselves on writing the shortest code possible. Perl provides numerous shortcuts and options that cut the length of a script-but that have the unfortunate side effect of making the script much more difficult to read and understand. The foreach structure requires a list between the parentheses. Most commonly, this list is simply an array. Sometimes, however, you see something like foreach(1..10), foreach (1,2,3,4,5,6,'blah'), or foreach (keys(%foobar)). Each of the expressions inside the parentheses represents a list. The first expression is a range of integers ranging from 1 to 10. The second should be obvious. The third uses the keys() function to get the list of keys for the %foobar hash. If you remember that foreach always requires a list between the parentheses, you will always have a basis from which you can figure out exactly what the loop does. More obscure, however, is the fact that the loop doesn't actually require you to provide a variable to contain each successive list item. If a variable isn't provided, the list item is assigned to the special variable $_. Therefore, I could have written lines 4 and 5 this way: foreach (@pairs) { This syntax would have done nothing to the functionality of the script but certainly would have obscured the meaning of the code. |
In line 5, split() is used again, this time to separate the key and value. Notice that the left side of the assignment in this line is not an array, as it was in line 3, but two scalars enclosed in parentheses. This syntax tells Perl that you want the enclosed list of scalars to be treated as an array for assignment purposes.
Lines 6 and 7 decode the information in the value portion of the key/value pair. This decoding is necessary, because the Web server software encodes the data (according to a standard scheme that is part of the CGI protocol specification) before placing the information in the $ENV{'QUERY_STRING'} variable. Therefore, you have to decode the information before you can present it to the user.
If you have no experience in Perl or UNIX, lines 6 and 7 of Listing 2.2 are likely to be the least understandable in the entire script. This section examines those lines one at a time to help you figure them out.
Line 6 uses the tr/// operator. This command takes two lists of characters as arguments. The first list (between the first two slashes) contains a list of characters to search for. The second list (between the second and third slashes) contains a list of replacement characters. The first character in the search list is replaced by the first character in the replacement list. The second character in the search list is replaced by the second character in the replacement list, and so on through the two lists. Thus, this syntax tells tr/// to perform this translation on $content, using the binding operator =~. So if you look at line 6 again, you see that the plus signs in $content are being translated into spaces.
Line 7 looks similar to its predecessor but is a little more complex. This line uses the s/// operator to perform further translation on $content (as designated by the =~ binding operator). This command takes a text pattern or regular expression between the first two slashes. Text that matches the first pattern is replaced by text designated by the replacement text between the second and third slashes. Some options for this command are designated by letters that follow the third slash.
What text pattern is the command searching for? This functionality looks benign and simple enough in this example, but Perl's pattern matching is so rich and useful that I'm going to explain the syntax briefly.
Regular expressions are familiar to veteran UNIX users, but they are likely to be Greek to everyone else. In its simplest form, a regular expression is a group of letters between two slashes, as in /word/. You might use a regular expression as follows:
if ($var=~/word/) { #do something here }
The conditional in this statement evaluates to true if $var contains the string word. This use of regular expressions is useful but very simple; Perl offers so much more.
First, Perl regular expressions, like normal UNIX regular expressions,
provide a set of characters called metacharacters, which
have special meaning within a search pattern. These characters
are listed in Table 2.2.
| Character | Meaning |
| ^ | Matches the start of the line or variable that is being searched. |
| $ | Matches the end of the line. |
| . (period) | Matches any character except a new-line character. |
| \ | When followed by another metacharacter, the two metacharacters combined match the second character. |
| () | Groups the enclosed pattern for later reference. The first such grouping is saved in $1; the second, in $2; and so on. |
| [] | Encloses a list of characters, any one of which you want to match. |
| | | Provides or functionality. |
In addition to metacharacters, Perl provides a set of predefined
character classes, which are very useful; they are shown in Table
2.3. Each class is designated by a string containing a backslash
followed by a single character.
| Meaning | |
| Matches any digit; same as [0..9] or [0123456789] | |
| Matches any nondigit character | |
| Matches any white-space character (for example, space and tab) | |
| Matches any non-white-space character | |
| Matches a word character: letters, digits, and underscore characters (_) | |
| Matches a nonword character |
Finally, Perl defines a set of quantifiers (shown in Table 2.4)
that you can use to modify your pattern.
| String | Meaning |
| * | Matches the preceding character zero or more times |
| + | Matches the preceding character one or more times |
| ? | Matches the preceding character zero times or one time |
| {x} | Matches the preceding character exactly x times |
| {x,y} | Matches the preceding character at least x times and at most y times |
A couple of examples may help make all this information a little clearer. The pattern /w..d/, for example, would match word and wand; it would also match forwarding and even how odd. So in the end, this pattern wouldn't be very useful. If you want to look in a string for four-letter words that start with w and end with d, you might use something like /\sw\w\wd\s/. If you want to find these occurrences and also save only the word (without the surrounding white space), you would modify this pattern to /\s(w\w\wd)\s/. So whenever this pattern matched, you would be able to find the word in $1.
You can also search for more complex patterns. Consider this pattern: /[ ^]\w(\w{2}) \w$1 \w$1[ $]/. You might use this pattern to find the name of a certain canine cop and similar three-word phrases. This pattern would match rin tin tin, fun gun run, or even six six six; I think you get the idea.
In the Guestbook script, the search text is %(..). The percentage sign is a normal character. You're looking for a percentage sign, which is why % is in the pattern. All of the following four characters are metacharacters. You're not actually looking for two periods enclosed in parentheses; the period stands for any character. Therefore, you're looking for any two characters. The parentheses mean that you want to save the text that matches the enclosed portion of the pattern for later use.
This pattern will match something like %0D, placing 0D in the variable $1. The entire matched string then is replaced by the replacement text. Because the e option is specified after the last slash, the replacement text is evaluated as an expression before replacement.
The replacement expression contains two functions. The innermost function hex($1) is evaluated first. This function takes the two characters following any percentage sign and converts them from a hexadecimal number to a decimal number. That decimal number then acts as the second argument of the pack() function. pack() is used to pack the second argument into a binary value, as in the method designated by the first value. In this case, the c in the first argument tells pack to transform the number in the second argument into a character. Basically, this method is a fancy way of translating an integer into its corresponding ASCII character.
In the Location box in figure 2.2, the comma after Hey is translated into %2C by the Web server. The hexadecimal number 2C is the decimal number 44; the comma is ASCII character number 44.
The final piece of information that you should know about line
7 in Listing 2.2 is that in addition to the e option,
the g option is specified. This option indicates that
the specified pattern should be replaced every time it occurs
in the $content variable. Without the g option,
the command would end immediately after the first time that the
pattern matched and the text was replaced.
| TIP |
A common mistake that beginners make with tr/// or s/// is to accidentally use the plain = operator instead of the binding =~ operator. If you run into a strange problem with a script and think that the problem is related to s/// or tr///, but can't figure it out, check to see whether you're using the proper operator between the sides of the expression. The mistake is an easy one to make-and an easy one to miss when you're looking for problems. |
Line 8 simply associates each key and freshly translated value in the %fields hash.
Now look at a short example to make sure that all the preceding information makes some sense. The name in figure 2.1 is entered in the text-entry field created with this code:
<dd><input type=text name=name size=30>
Because this field is the first field in the form, the first element in @pairs contains name=Joe+User after the information in figure 2.1 is submitted. So you can see that the names of the fields in the form are passed directly to the script. If you process the provided data properly, you end up with an associative array with keys that correspond to the names of the fields in the form. Thus, in this example $fields{'name'} equals Joe User.
Now that the form data is properly translated, you want to output data to the user. Line 10 prints a header. Whenever you print information from your script back to the user, you have to print this line (or a similar one). The header tells the browser the type of information contained in the document that the script is about to produce (thus, "Content-type"). Notice the \n\n at the end of the quoted string. The backslash is an escape sequence. In a string enclosed in double quotes in a Perl script, escape sequences are translated into special characters that you would not otherwise be able to include in a string (see Table 2.5). In this case, \n translates into a new line. The two new lines after the header are required, according to the HTTP specification.
In addition to \n, several escape sequences in Perl allow
programmers to output special characters. Table 2.5 describes
the escape sequences.
| Translation | |
| Produces a bell character. | |
| Produces a control character. \cM, for example, translates into Ctrl+M or a carriage return. | |
| Produces an escape character. | |
| Ends a case modification started with \L or \U. | |
| Produces a form feed. | |
| Makes the next character lowercase. | |
| Makes all succeeding characters until the next \E lowercase. | |
| Produces a new line. | |
| Produces the character with the octal ASCII character code nn. | |
| Puts backslashes before any regular-expression metacharacters until the next \E. | |
| Produces a return. | |
| Produces a tab. | |
| Makes the next character uppercase. | |
| Makes all succeeding characters uppercase until the next \E. | |
| Produces a vertical tab. |
The final three lines of the script print the necessary HTML to make a simple page for the user to view. Notice that the script is still printing double-quoted strings. The double quotes tell Perl not only to translate the escape sequences, but also to print the contents of any variable referenced in the string. If you mistakenly enclosed this string in single quotes, instead of the value of $fields{'name'}, enclosed in some HTML tags and followed by a new line, the script would have printed the string literally-"<h2>$fields{'name'}</h2>\n." Clearly, that result is not what you want.
Always remember that double-quoted strings are parsed and that
variables and escape sequences are translated appropriately. Single-quoted
strings are not parsed and are interpreted literally.
| TIP |
When you're creating HTML forms, remember that you will be using the names of your various input fields as keys for associative arrays. For ease of programming, you'll want to keep the names as short as possible. |
Now that you know some basic Perl, you'll want to know how you create a Perl script on your computer. The procedure isn't difficult. Perl scripts are just simple text files. If you have a favorite way of creating HTML files on your server, you can use the same method to program in Perl.
Some people edit their scripts on their desktop computers (using something like Wordpad in Windows 95 or SimpleText on a Macintosh), save the scripts as text files, and then transfer them to the server with FTP. Using this method to write a large number of scripts, however, would be tedious, so most people find a file-editor program to use on the Web server computer.
Many UNIX veterans swear by an editor called vi. In fact, many of these people say that if you don't use vi as your only editor, you must be a UNIX dabbler. Don't listen to them. I'm sure that vi is a wonderful text editor, but I discovered early in my experience with UNIX that its command structure was so counterintuitive that it was useless for me. So I looked around until I found an editor called joe, which is the only text editor that I use now. joe's commands are based on the commands in an early DOS-based word processor called Wordstar, which I used to use, so joe's commands were a snap for me to pick up. (Don't tell anyone; they might not respect me as a programmer.) You also have other options. If you have experience with the UNIX mail program pine, you may want to try pico, an editor that uses the same commands as the message editor in pine.
My point in this little digression is that you should find and editor that is quick and easy for you to use. Most CGI scripts are short and simple, so you don't need many advanced features.
One final note about script-file creation: when you first make a file on a UNIX computer, the file has a default set of file permissions. A file's permissions tell the operating system what a user can do with that file. Usually, default permissions do not allow that file to be executed as a program, so you'll have to change them. The command that you use for this purpose is chmod. In most cases, you want to issue the command chmod 755 scriptname after you create your Perl scripts; this command gives the file proper permissions for execution by the Web server. For more information about the chmod command, type man chmod at the command prompt on your UNIX server.
With the information provided in the preceding few pages, and with a little knowledge of your Web server and operating system, you should now be able to use a Perl CGI script to process information from a form and print a simple page. This knowledge is a good start; now you learn how to build on it.
In addition to processing form input, CGI can be used to create and display documents on-the- fly. To start this example, I modified Listing 2.2 slightly to come up with the script shown in Listing 2.3.
Listing 2.3 Revised Guestbook Script (GUESTBOOK2.PL)
#!/usr/bin/perl
$temp=$ENV{'QUERY_STRING'};
@pairs=split(/&/,$temp);
foreach $item(@pairs) {
($key,$content)=split (/=/,$item,2);
$content=~tr/+/ /;
$content=~ s/%(..)/pack("c",hex($1))/ge;
$fields{$key}=$content;
}
$fields{'comment'}=~s/\cM//g;
$fields{'comment'}=~s/\n\n/<p>/g;
$fields{'comment'}=~s/\n/<br>/g;
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst)=localtime(time);
if (length ($min) == 1) {$min = '0'.$min;}
$date="$mon/$mday/$year, $hour:$min";
open (gbfile, ">> guestbook.txt");
print gbfile $date,"::$fields{'name'}::$fields{'comment'}\n";
close (gbfile);
print "Content-type: text/html\n\n";
print "<body bgcolor=\"#FFFFFF\">\n";
print "<h2>$fields{'name'}</h2>\n";
print "$fields{'comment'}\n";
This script functions exactly like the original from the user's standpoint. A couple of key differences exist, however.
First, immediately after processing the data as in the original version of the script, the script performs three additional substitutions on the $fields{'comment'} variable. The first of these three lines removes any carriage returns that the browser inserts into the comment field. The escape character \c tells Perl that the next character in the pattern should be taken as a control character. Thus, \cM matches Ctrl+M, which is a carriage return.
The next two lines substitute a <p> HTML tag wherever two new lines appear in a row. The second line substitutes a <br> tag for a single new line. These new tags replace the <pre> tags that were used in Listing 2.2, making the output prettier.
Next, you see a call to the localtime() function. This function returns a nine-element array that contains various portions of the current time. I used fairly standard descriptive variables on the left side of the equation; these variables do a good job of showing what each element of the returned array is.
After getting the time information, the script uses the length() function to determine whether $min is a single digit. If so, the script adds 0 on the left, using the dot operator; otherwise, $min is used as is. The script creates a date/time string from the data returned from localtime().
This string is used in the final new section of the script. The first line opens a file handle (gbfile) that points to a file called guestbook.txt. The >> characters before the file name indicate that I want to append to the file. The following print command writes the data from the form into a single line in the Guestbook file. Notice that this print statement has two arguments. The first argument is the handle of the file that you're writing to; the second is the expression to be printed. In all the other print statements used so far, no file handle is specified. In these cases, the output defaults to STDOUT, which is the standard output on UNIX systems.In CGI scripts, STDOUT is ultimately redirected back to the browser.
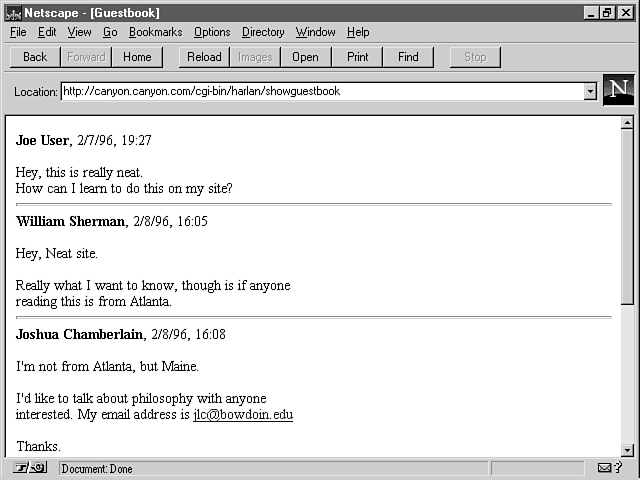
All these changes to the form-processing script are carried out in such a way that you can save and, later, access all Guestbook entries. You'll use a CGI script to access the entries. Figure 2.3 shows what simple output might look like.
Figure 2.3 : This screen shows a display of multiple Guestbook entries.
Listing 2.4 shows the Perl script that created the output shown in figure 2.3.
Listing 2.4 Guestbook Display Script (SHOWGUESTBOOK1.PL)
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<body bgcolor=\"#FFFFFF\">\n";
print "<title>Guestbook</title>\n";
open (gbfile, "guestbook.txt");
while (defined($line=<gbfile>)) {
($date,$name,$comment)=split(/::/,$line);
print "<b>$name</b>, $date<p>\n";
print "$comment<hr>";
}
close (gbfile);
This script contains only one new concept: the while loop. This loop simply runs through each line of the file referenced by the gbfile file handle. First, the script opens the file. The open command is the same as in the Guestbook script, with one key difference: the >> characters are missing. When a file is opened with no symbol before the file name, the file is opened for reading. Then the script in Listing 2.4 starts the while loop.
The conditional for the while loop works as follows.
When a file handle is enclosed in angle brackets and evaluated
in a scalar context, it returns the next line of the file. Perl's
defined() function evaluates as true if the
expression is defined. The expression $line=<gbfile>
is undefined (and the loop exits) when all the lines in the file
have been processed. The statements in the loop are fairly simple.
The first line splits the data into three separate variables;
the next two lines print the data.
| NOTE |
Looping through and processing each line in a file is one of the most common operations in Perl. For that reason, a common shortcut is used for that operation. That shortcut looks like this: while (<gbfile>) { In a while loop, if a file handle enclosed in angle brackets is the only conditional in the loop, the current line from the file is assigned to $_ each time through the loop. The expression <gbfile> is true until all lines in the file have been read. |
At this point, you may be curious about why I didn't just write the Guestbook information to a straight HTML file in the first place, so that the user could just call up that file to look at the Guestbook list. Certainly, that method is an option, and many guestbook programs do just that. But this method provides some additional flexibility that straight HTML can't offer.
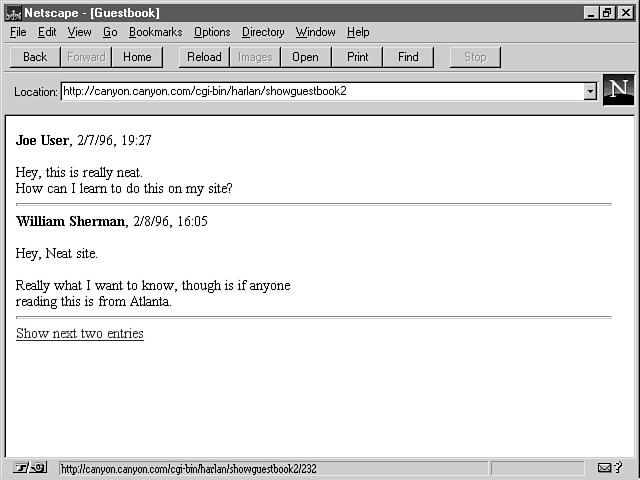
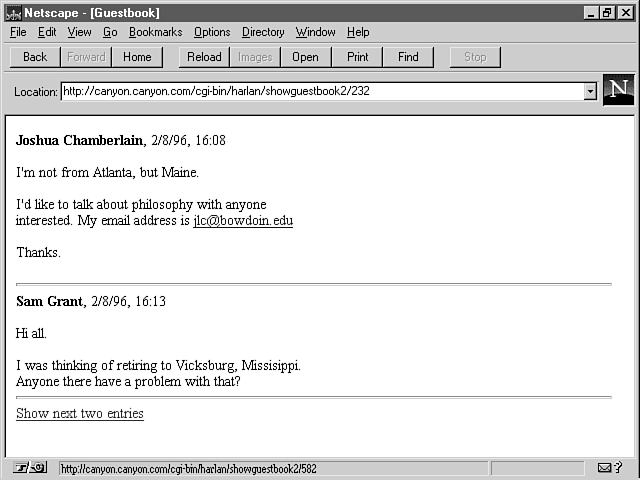
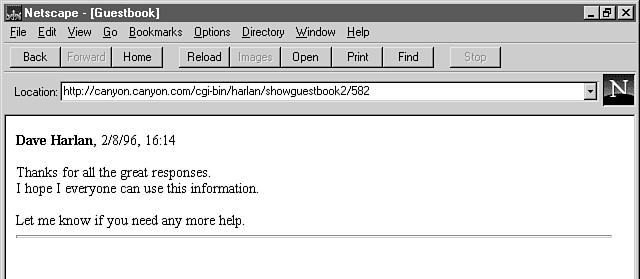
If, for example, you want to display only x number of lines on any given page and limit the total number of entries in the file, the result would look like figures 2.4, 2.5, and 2.6. Figure 2.4 shows the result of the initial call to this new script. Figure 2.5 shows the page that is returned after the user selects the Show next two entries link in figure 2.4. The URL in the Location box in figure 2.6 also has a number, but the text does not include a Show next... link.
Figure 2.4 : The screen in this figure shows a new way of displaying the entries.
Figure 2.5 : Two more entries are displayed after the user selects the link in figure 2.4.
To figure out how this output is produced, examine Listing 2.5, which contains the SHOWGUESTBOOK2 script.
Listing 2.5 Revision of the Guestbook Display Script (SHOWGUESTBOOK2.PL)
#!/usr/bin/perl
$filepos=$ENV{'PATH_INFO'};
$filepos=~s/^\///;
$filepos=0 if $filepos eq '';
print "Content-type: text/html\n\n";
print "<body bgcolor=\"#FFFFFF\">\n";
print "<title>Guestbook</title>\n";
open (gbfile, "guestbook.txt");
seek (gbfile,$filepos,0);
$i=1;
while (<gbfile>) {
($date,$name,$comment)=split(/::/,$_);
print "<b>$name</b>, $date<p>\n";
print "$comment<hr>";
$i++;
last if $i==3;
}
$newfilepos=tell(gbfile);
if (<gbfile>) {
print "<a href=/cgi-bin/harlan/showguestbook2/$newfilepos>Show next two
åentries</a>\n";}
close (gbfile);
The changes in this script introduce one new CGI concept and a couple of new Perl commands. As pointed out earlier in this section, the URL in the Location box shown in figures 2.5 and 2.6 has additional information tacked on at the end. At first glance, this information might seem to be a bit odd. In figure 2.5, it appears that you're calling a script called 232 in the /CGI-BIN/HARLAN/SHOWGUESTBOOK2 directory. Clearly, that's not what's happening, though.
The CGI specification includes an environment variable called PATH_INFO. All CGI-compliant Web servers can translate any URL appropriately. If the URL that points to a script includes any information after the script name, all that information is passed to the script in the PATH_INFO environment variable.
When you click the link at the bottom of figure 2.4, /232 is passed to showguestbook2. Line 1 of the script assigns this value to $filepos; line 2 removes the leading slash. To make the script work the first time through (that is, when PATH_INFO contains no information), line 3 makes $filepos zero when it contains the null string. After printing the top of the document to be sent back to the user and opening the GUESTBOOK.TXT data file, line 9 performs the key action in the new script.
Perl's seek() function takes three arguments: a file
handle, a position, and a number that indicates what this position
is relative to. In this script, the third argument is zero. This
argument indicates that you want the change in position to be
relative to the top of the file. Because $filepos is
232, the seek() command in line 9 moves the position
pointer to 232 bytes from the top of the file. This position is
where the script will start reading lines from GUESTBOOK.TXT after
the user clicks the link in figure 2.4, producing the result shown
in figure 2.5. When the user selects the link in figure 2.5, the
script starts reading 582 bytes into the file, producing the output
shown in figure 2.6.
| TIP |
$ENV{'PATH_INFO'} is an extremely effective means of passing information to scripts. Many times, you can avoid using a trivial form by using PATH_INFO instead of the form to pass information. |
All this should make sense now, although you might be curious about where the numbers that end up in the PATH_INFO variable come from. Look at line 16:
last if $i==3;
The last command is something that you haven't seen before. The command breaks the script out of a loop when the condition of the loop otherwise would tell the script to continue. In this case, you want the loop to end if the counter variable $i equals 3, because if it has reached 3, the script has printed two Guestbook entries, and you don't want to print any more.
So you exit the loop and end up at line 18, where you get the magic number that tells the script where in the file to start the next time around. The tell() command returns the current file position of the provided file handle. By saving this value at this point in the script, you know exactly where the last Guestbook entry that you printed ends and where the next one begins.
All you have to do now is print the link at the bottom of the page. The if statement in line 19 makes sure that the script prints the link only if some entries in the GUESTBOOK.TXT file haven't been printed.
Now that you have an effective means of printing the Guestbook entries, you want to make more changes to the Guestbook entry script, as shown in Listing 2.6.
Listing 2.6 The Further-Revised Guestbook Script (GUESTBOOK3.PL)
$date="$mon/$mday/$year, $hour:$min";
#revisions start here...
open (gbfile, "guestbook.txt");
@gbfile=<gbfile>;
close (gbfile);
open (gbfile, "> guestbook.txt");
print gbfile $date,"::$fields{'name'}::$fields{'comment'}\n";
$i=1;
foreach (@gbfile) {
print gbfile $_;
last if $i==9;
$i++;
}
close (gbfile);
print "Location: http://192.0.0.1/cgi-bin/harlan/showguestbook2\n\n";
Listing 2.6 makes two major changes in the Guestbook entry script. In line 3, the script opens the GUESTBOOK.TXT file. The script reads the entire file into an array in line 4 and closes the file in line 5.
To reopen the file in line 6, I used the > character to tell Perl that I want to overwrite the file. (Recall that in the preceding version of this script, I used the >> symbol because I wanted to append to the file.) Why would I want to overwrite the file? Displaying the entries in reverse chronological order makes more sense, so I overwrite the file each time to accomplish this task.
In line 7, the script writes the new entry to the file. In line 9, the script starts a loop that writes the rest of the old entries back into the file. Line 11 terminates the loop after 9 entries have been written to the file, discarding the last entry. This line limits the file to the 10 most recent entries.
Now that the output has been refined, you want to send the user straight to the Guestbook display script after he signs in. That task is exactly what the last line of Listing 2.6 accomplishes.
When a browser receives a properly formatted Location header, it knows to retrieve the document specified after the colon. This feature can save a programmer a great deal of time. Instead of reinventing the wheel that displays the data by churning out HTML in the form-processing script, the programmer can write output code only once, in some cases. This function isn't a cure-all, but you should keep it in mind.
If you have done extensive HTML development, you may know about server-side includes, or SSI-a set of functions built into some Web servers that allow a developer to use special HTML directives to insert some data into documents on the fly.
The information that you can insert can take the form of a local file or a file referenced by a URL. You can also include information from a limited set of variables. Finally, you can execute scripts to output the data that will be inserted into the document; for details, see the sidebar titled "What Else Can You Do with SSI?"
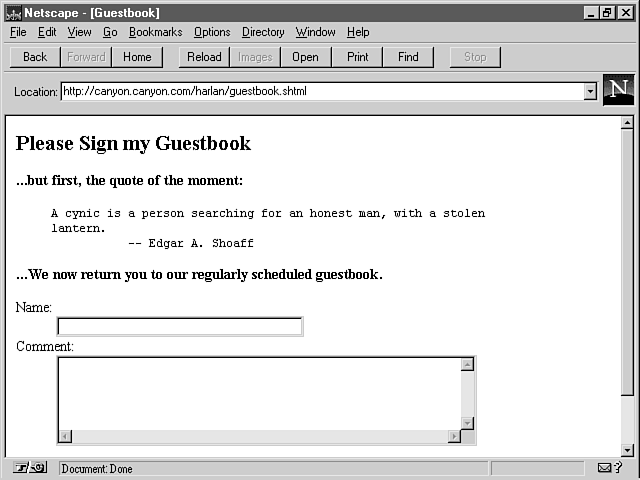
One thing that you may notice about the page shown in figure 2.7 is the fact that the file name has changed to GUESTBOOK.SHTML. The change in the file extension tells the server that it should check the file for SSI commands. The file extension depends on server configuration, but .SHTML is a common choice.
Figure 2.7 : This new Guestbook form includes a quote to spice up the page a little.
| What Else Can You Do with SSI? |
When they're available, server-side includes are a good way to make simple pages more interesting. In this chapter, you see an example of executing CGI to create dynamic sections in otherwise-static documents. This sidebar describes what else SSI can do. The format for any SSI command is as follows: <!-#command option=value-> |
Table 2.6 lists the SSI commands and their options.
| Command | Options | Explanation |
| config | errmsg | Sets the value that will be sent if an error occurs when future SSI commands are parsed in a document. |
| timefmt | Sets the format for outputting dates from SSI commands. See the strftime() UNIX manual page for details on how to format dates with this command. | |
| sizefmt | Sets the manner in which file sizes are displayed. Set this option to bytes (to display SSI file-size command results in bytes) or abbrev (to display sizes in kilobytes or mega-bytes, as appropriate). | |
| Echo | var | Prints the specified variable. All CGI environment variables and the following SSI variables can be echoed: DATE_GMT, DATE_LOCAL, DOCUMENT_NAME, DOCUMENT_URI, LAST_MODIFIED, and QUERY_STRING_UNESCAPED. |
| Exec | cmd | Executes the specified command, using /BIN/SH, and includes the resulting output on the page. Requires a physical path to the command. |
| cgi | Executes the specified CGI script. Takes a virtual path to the script (for example, /CGI-BIN/HARLAN/FORTUNE rather than /USR/LOCAL/ETC/HTTPD/CGI-BIN/HARLAN/FORTUNE). | |
| Flastmod | file | Includes the last modification date of the indicated file in the document. Requires a physical path to the document. |
| virtual | Same as file, except that it takes a virtual path. | |
| Fsize | file | Includes the size of the indicated file in the document. Requires a physical path to the document. |
| virtual | Same as file, except that it takes a virtual path. | |
| Include | file | Includes the text of the indicated file in the document. Requires a physical path to the document. |
| virtual | Same as file, except that it takes a virtual path. |
As you can see, SSI provides a fairly rich set of features to the programmer. You might use SSI if you have an existing set of documents to which you want to add modification dates. You also could have a file that you want to appear on several of your pages. You could use the SSI include command on each of those pages instead of copying the document into each page individually.
One problem is the fact that SSI may not be available on all Web servers; it opens some security holes that some site administrators are not willing to risk. If you administer your own site and trust all the page designers on your site, however, SSI is a useful tool in your Web development arsenal.
The following paragraphs focus on the exec command. Refer to figure 2.7, which appears earlier in this section. This figure shows the familiar Guestbook entry form, with a twist: a "quote of the moment" appears at the top of the form. Knowing what you do from having read this far, you probably could write a CGI script that would read a quote from a file, print that quote, and then print the HTML for the form.
But that's not how I created this page. Listing 2.7 shows the source for the page in figure 2.7.
Listing 2.7 Source for GUESTBOOK.SHTML
<HTML> <body bgcolor="#FFFFFF"> <title>Guestbook</title> <h2>Please Sign My Guestbook</h2> <b>...but first, the quote of the moment:</b><p> <!--#exec cgi="/cgi-bin/harlan/fortune"--> <b>...We now return you to our regularly scheduled guestbook.</b><p> <form method=get action="/cgi-bin/harlan/guestbook"> <dt>Name:<br> <dd><input type=text name=name size=30> <dt>Comment:<br> <dd><textarea name=comment rows=5 cols=50></textarea><p> <input type=submit value="Sign In"> </form> </html>
You can see that I added three lines to the document. Two lines
are straight HTML. The third line-the one that you may not recognize-is
an SSI command. The syntax is straightforward; it says, "Execute
the CGI script /CGI-BIN/HARLAN/FORTUNE." Easy, right?
| NOTE |
If you point your browser at GUESTBOOK.SHTML and then use your browser's View Source command, you do not see the code in Listing 2.7. When you use SSI, the commands inside the <!-- ... --> tags are translated into straight HTML before they get to the browser. |
The fortune CGI script isn't difficult, either. Listing 2.8 shows the code.
Listing 2.8 Code Listing for fortune (FORTUNE.PL)
#!/usr/bin/perl
open (fortune,"/usr/games/fortune |");
print "Content-type: text/html\n\n";
print "<pre>\n";
while (<fortune>){
print " $_";
}
print "</pre>";
This script presents only one new concept. Look at line 2. You saw the open() command earlier in this chapter, but this time, it uses a new option. The pipe (|) at the end of /usr/games/fortune | tells Perl to run the operating-system command /USR/GAMES/FORTUNE (on the server machine) and to provide (or pipe) the information in the given file handle as though the result of the command was being read from a file.
fortune is a common UNIX command that spits out a random quote, so if you look at the rest of the script, you can see what happens. First, the script prints the standard HTML header; then it outputs the opening <pre> tag. Next, the script simply loops through the lines of output from the command. Then the script prints each line of output back to the browser with five leading spaces, indenting the output on the resulting page. Finally, the script prints the closing </pre> tag.
The result is the page shown in figure 2.7. Of course, the next user (or you, if you reload) will see a different quote at the top of the page.
You now have basic knowledge of CGI and Perl. In this chapter, you learned how to process data from a form and print a properly formatted page. You also learned how to call Perl scripts directly and how to use Perl in server-side includes. Finally, you were exposed to a useful subset of Perl. Regular expressions, saving and retrieving data in text files, printing, and looping should all be within your grasp now.
For further information, read the following chapters: