


The World Wide Web
Why use CGI?
The Common Gateway Interface, or CGI, is a standard for communication between Web documents and CGI scripts you write. CGI scripting, or programming, is the act of creating a program that adheres to this standard of communication. A CGI script is simply a program that in some way communicates with your Web documents. Web documents are any kind of file used on the Web. They can be HTML documents, text files, image files, or any number of other file formats. The existence of this gateway between programs you write and your Web documents allows you to create much more dynamic and interactive Web pages than you could with HTML alone.This chapter will help you understand the role of CGI scripting within the World Wide Web and will show why you would want to use it. First, you will be introduced to some of the key elements and terminology of the Web, such as HTTP, URLs, HTML, and CGI. Then you will learn some of the advantages of CGI scripts.
The World Wide Web
Many people have heard of the World Wide Web, but not everyone knows what it is. Even people who use it may have trouble defining it precisely. The World Wide Web is a global collection of interconnected documents on the Internet. Because the World Wide Web has grown explosively and has been advertised so extensively, many people think it is the same thing as the Internet. However, the World Wide Web is only a part of the Internet.The Internet has been around for over three decades. It began as a Department of Defense program for enabling computers to communicate over great distances without requiring a central server to route the communications traffic. Since those early days, the Internet has grown substantially. Early on it was adopted by the academic community, and more recently it has been commercialized. The federal government no longer funds the Internet directly, leaving private and public telecommunications companies in charge of the major backbones-the major network connections of the Internet. The telecommunications companies charge Internet service providers for connections to the backbone, and Internet service providers in turn charge companies and individuals for their access to the Internet. The Internet itself is nothing more than an enormous number of networked computers all over the world. Like any computer network, the Internet has various software programs running on it, such as e-mail, newsgroups, FTP, gopher, and the World Wide Web.
The World Wide Web, or Web, was born in 1989 at CERN (the European Laboratory for Particle Physics). Since then, it has grown at a phenomenal rate. Today, Web traffic accounts for somewhere between one third and one half of the total traffic on the Internet. Because the Internet consists of many other sources of traffic, many of which have been around for decades, this is an impressive feat.
So, what is the Web? In simple terms, the Web is a part of the Internet that uses the Hypertext Transfer Protocol (HTTP) to display hypertext and images in a graphical environment. Hypertext refers to the ability to present text documents that are interlinked. You might click on a portion of the text in a document and be taken to another section of text in a different document. The Web is based on the concept of hypermedia, which is a superset of hypertext. Think of hypermedia as various forms of media (text, graphics, sound files, and so on) that are interlinked. For example, you could click on a text link in one document and display a graphic image. Figure 1.1 illustrates both a text link and an image link. Clicking on the word "resume" would take you to a page with the actor's rÈsumÈ, and clicking on the picture itself would take you to a larger version of the same image. In the early days of the Web, text links always had a different color of underlined text, and graphic links were always enclosed within a colored box. Now, however, the current shape of the mouse pointer gives you a better indication of what is and isn't a link. If the mouse pointer changes into a hand with the index finger extended, as shown below the "resume" link in Figure 1.1, the object being pointed to is a link to another document. Documents on the Web are interlinked so you can navigate between them by selecting links. The name World Wide Web alludes to the Web's spiderweb-like nature.
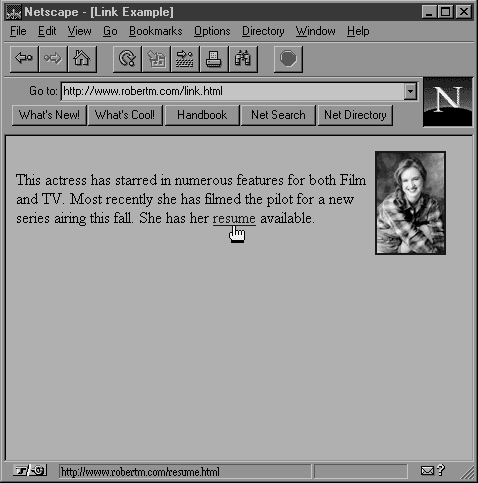
Figure 1.1: An example of a link
Clients and Servers
To understand the World Wide Web and CGI programming, you must understand the division between Web clients and Web servers and how HTTP facilitates the interaction between the two. Simply put, a server handles requests from various clients. For example, suppose you are using a word processing program to edit files on another computer. Your computer would be the client because it is requesting the file from another computer. The other computer would be the server because it is handling your computer's request. With networked computers, clients and servers are very common. A server typically runs on a different machine than the client, although this is not always the case. The interaction between the two usually begins on the client side. The client software requests an object or transaction from the server software, which either handles the request or denies it. If the request is handled, the object is sent back to the client software. On the World Wide Web, servers are known as Web servers, and clients are known as Web browsers. Web browsers request documents from Web servers, allowing you to view documents on the World Wide Web. There's a good chance that you have already used a Web browser. Some of the most common browsers are Netscape's Navigator, Microsoft's Internet Explorer, and NCSA's Mosaic. Like most software companies that distribute Web browsers, these companies also distribute Web server software.The process of viewing a document on the Web starts when a Web browser sends a request to a Web server. The Web browser sends details about itself and the file it is requesting to the Web server in HTTP request headers. The Web server receives and reviews the HTTP request headers for any relevant information, such as the name of the file being requested, and sends back the file with HTTP response headers. The Web browser then uses the HTTP response headers to determine how to display the file or data being returned by the Web server. (There's more information on these headers in Chapter 2.)
Note: This discussion barely scratches the surface of what is actually happening, but it is enough for our study of CGI scripting. If you want more details on HTTP headers, check Chapter 2 as well as the "Useful Web Pages" section of the Appendix.
When a Web browser requests a CGI script from a Web server, the server starts the CGI script and passes the HTTP request headers to it. The information stored in the request headers is available for your script to use. Normally, when a CGI script is finished executing, the output is passed back to the Web server, which formats an HTTP response header and sends the information to the Web browser. It is possible, however, for your CGI script to format the HTTP response header and send the data directly to the Web browser. You can use this approach to reduce the work load of your Web server.Whether the Web browser is requesting a file or a CGI script, the browser has to know the location of the Web server and the name of the file in order to make the request. With the millions of documents on the Web, you might wonder how the Web browser knows exactly where to look for the file you want to see. You probably also realize that many files on the Web have the exact same name. So how do the Web browsers get the correct document? Each file on the Web has a unique identifier that not only sets it apart from other documents but also describes where it is located. These unique identifiers are called uniform resource locators, or URLs.
Uniform Resource Locators
The uniform resource locator (URL) is like an address for Web documents. Every document on the Web has a unique URL, and each part of the URL provides specific information about the location of the document it addresses. Here are some examples of URLs:
http://www.thepalace.com/palace-faq.html
http://www.yahoo.com
http://www.thepalace.com/cgi-bin/directory.pl
ftp://ftp4.netscape.com/pub/MacJavaB1/Mac2.0JavaB1.hqx
Each URL has three basic parts: the protocol, the server machine, and the file being requested.
The protocol is everything up to the colon and the first two slashes. The protocol for the first three of the preceding examples is http (hypertext transfer protocol) and the protocol for the last one is ftp (file transfer protocol). For a Web browser, the most common protocols are http://, ftp://, gopher://, and news://.
Following the protocol, between the double slashes and the first single slash, is the name of the machine you want to access. This name can be either the domain name of the machine, as in all of the examples, or the IP address. Just as every document on the Internet has a unique identifier, every machine on the Internet must also. This identifier is a number known as the IP (Internet Protocol) address. An example of an IP address is 206.17.52.2. Because names are easier for people to remember than numbers, IP address can be aliased to domain names. For example, the domain name www.thepalace.com points to the machine with the IP address 206.17.52.2. Sometimes you may see a colon and a number following the machine name, as in www.abletree.com:8080. This means that the server you are accessing on the www.abletree.com machine is using the port 8080 instead of the default port, which for Web servers is port 80.
After the protocol and the name of the server machine, the URL contains the name of the file being requested. This name often includes subdirectories on the server machine. If no subdirectories are included, the server looks in the document root, which it believes to be the highest-level directory. In the first example URL, the file palace-faq.html is in the document root on the www.thepalace.com machine. The fourth example is the address for a file called Mac2.0JavaB1.hqx in the pub/MacJavaB1 subdirectory of the ftp4.netscape.com machine.
The second and third examples illustrate special occurrences of URLs. The second example, http://www.yahoo.com, does not specify a file to retrieve. Most of the time, when no file is specified, the Web server automatically looks for a file called index.html and returns that file. If index.html does not exist, the Web server returns a list of files contained in that directory, which in this example is the document root. Many Web servers also allow you to specify a default file to return for URLs formatted in this manner. This default file you specify can be a CGI script, which gives you a great deal of control over what documents are available to certain Web browsers and Internet domains. The third example, http://www.thepalace.com/cgi-bin/directory.pl, looks like the first and fourth example, but with one key difference. The directory cgi-bin does not have to be a subdirectory of the document root. Most Web servers allow you to specify a location for the cgi-bin directory, which is outside of the document root. Also, when a Web server receives a request for a file contained in the subdirectory cgi-bin, it knows that the file is a CGI script and will run it and return only the output from the script. The cgi-bin directory is discussed in more detail in Chapter 3.
So, each document on the Web has a unique URL, but what are these documents? Well, they can actually be any kind of file, such as graphic images, executable programs, text files, word processor documents, and spreadsheets. Any file can be sent by a Web server. However, only a limited number of file types can be displayed in a Web browser. Text, GIF images, and JPEG images are the only files that most Web browsers can display. If a Web server sends a file that the browser cannot display, the user can either start a helper application to display the file or save the file to the hard drive. Most of the documents you encounter on the Web will be text files containing HTML.
HTML
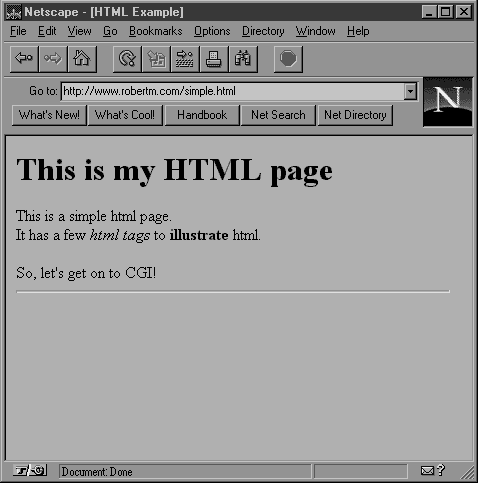
Hypertext Markup Language, or HTML, is a subset of the Standard Generalized Markup Language (SGML), a language that specifies document types and how to display the various types. HTML consists of various tags that describe to the Web browser how to display the information contained within the document. Every hypertext document on the World Wide Web is published in either HTML or SGML. What follows is an example of the contents of an HTML file. Figure 1.2 shows how the Netscape Navigator browser would display that HTML page.
<HTML> <HEAD> <TITLE>HTML Example</TITLE> </HEAD> <BODY> <H1>This is my HTML page</H1> This is a simple html page.<BR> It has a few <I>html tags</I> to <B>illustrate</B> html. <P>So, let's get on to CGI! <HR> </BODY> </HTML>
Figure 1.2: The HTML example in a browser window HTML is very important to CGI scripts. It is from within HTML documents that most CGI scripts get called. Also the information returned from a CGI script is usually either in HTML format or is a pointer to an HTML document. Because of this close interaction between CGI and HTML, it is helpful to be familiar with HTML before learning CGI scripting. This book does not teach HTML scripting, and it assumes a basic understanding of HTML tags. But don't be too concerned if you do not already know HTML. The examples in this book, like the one a moment ago, will only contain basic HTML, which should be fairly self-explanatory. For help learning HTML, try HTML3 Manual of Style by Larry Aronson (Ziff-Davis Press, 1995) or consult the "Useful Web Pages" section of the Appendix for a list of online resources.
CGI
Remember, CGI stands for Common Gateway Interface. As its name implies, it is a gateway between the Web server and your CGI script. It enables the CGI program that you write to receive input from and send output to a Web browser. You can write CGI programs in almost any programming language. If you already know how to program, CGI will be very easy for you to learn. To get started, you just need to know how data is passed back and forth between the Web server and your program. But because CGI is not a programming language, you need to know one to write CGI scripts.The way CGI works is quite easy as well. Let's take a simple CGI script and execute it from a Web browser. Here is the contents of first-one.pl.
#!/usr/local/bin/perl print "Content-type: text/html\n\n"; print "<H1>Simple CGI Script</H1>\n"; print "This is my first CGI script!\n";
Note: Most of the examples in this book are written in Perl 5 and run on a UNIX system. They have also been tested on a Windows system. If you are trying these examples on a Windows machine, be sure to remove the #!/usr/ local/bin/perl line, which is specific to UNIX environments. If you don't know Perl, don't worry. The examples will either be easy or there will be a line-by-line explanations of the code within the text. For instance, this example just prints three lines of text to standard out (stdout), which is the default location to which a program sends its output. In most cases standard out is the monitor. However, for CGI scripts, standard out is sent to the Web server and then on to the Web browser.
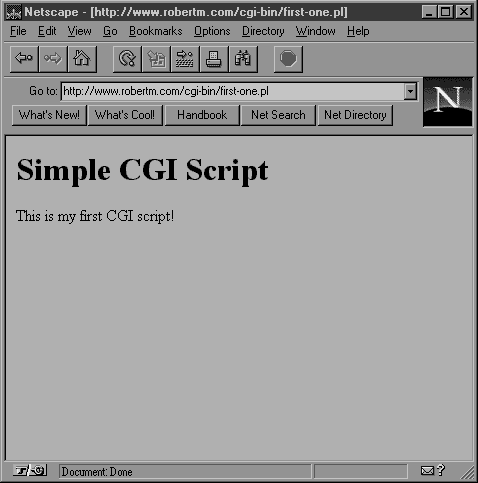
Because Perl is an interpreted language, you can just place the preceding code in a text file, save it as first-one.pl, and run the program with the Perl 5 interpreter. For UNIX systems, this means making the file first-one.pl executable. You can also run this file on Windows and Macintosh systems by using the Perl 5 interpreter available for those systems.For now, place the file first-one.pl in the cgi-bin directory of your Web server. cgi-bin is a naming convention for Web servers running on UNIX systems. Windows users will have something similar, such as cgi-shl for Windows 95 or NT machines running the WebSite Web Server by O'Reilly & Associates, Inc. You will learn about another option for file placement in Chapter 3. After you have placed the file in the cgi-bin directory, go to your Web browser and load the file by opening the URL http://www.robertm.com/cgi-bin/first-one.pl. Figure 1.3 shows the result in my browser window.
Note: The domain name www.robertm.com in the preceding URL is specific to my machine. All the examples in the book will reference that domain. For your URL, you need to use the domain name or IP address of the machine on which you are working. If you don't know this information, ask your system administrator.
Figure 1.3: Results of first-one.pl script Let's take a look at what is happening behind the scenes when you call this script from your browser. First, the browser sends an HTTP request for the first-one.pl file in the cgi-bin directory on the www.robertm.com machine. The Web server on the www.robertm.com machine receives the request and finds the file on the system. Because the request is for a document in the cgi-bin directory, the Web server knows that it is a CGI script, and executes it. At this point, the script takes over. It executes its three lines and sends the output, stdout in this case, to the Web server. The Web server receives the data and checks the header the CGI script returned. The header in the preceding script is the Content-type: text/html line. (Valid headers are discussed in detail in Chapter 2.) This header tells the Web server that the data it received from the CGI script is just HTML. The Web server then forms an HTTP response header and sends the header and the CGI output to the Web browser that called it.
As you can see in the preceding example, only the line
print "Content-type: text/html\n\n";in the CGI script is CGI specific. The other two lines simply output the HTML that is displayed in the browser. The HTML would be exactly the same if it were in an HTML file on the Web server. When you begin writing CGI scripts, you will discover that only a small amount of your code has to deal with the CGI. The rest of the code is specific to the task you want to accomplish.
Why Use CGI?
You may have noticed that the preceding CGI example could just as easily been a simple HTML file. In fact, you don't gain any advantage from making it a CGI script. So why use CGI? Well, for the preceding example, you wouldn't. It is just a simple example CGI script. As you learn CGI, however, you will see that it allows you to extend the functionality of Web documents to produce dynamic and interactive pages.
Dynamic Web Pages
Recall that the World Wide Web is divided into Web browsers and Web servers that use HTTP to communicate, and that most Web pages are written in HTML. But HTML pages are always static. They do not change unless you edit the file and alter the contents. CGI, however, allows you to create very dynamic documents. A CGI script can draw from up-to-date information to form the Web page that is displayed in the browser. For example, you can use CGI to create documents that display current data such as the time, date, and number of accesses to that page. With HTML alone, it would be impossible to display this information in real time.CGI can also interface with a database to make dynamic documents. If your database included a lot of information that you wanted to make accessible via the Web, it would be a laborious project to convert all of the data into HTML pages. Then, every time the data in your database changed, you would have to edit every HTML page containing the information that had changed. For a large database, this process would be very time consuming and error prone. There would also be limits on how the user could search through the data. Every possibility for search results would have to be an HTML page created and maintained by you. CGI makes this process much easier. All of the data can remain in your database, where you maintain it as you always have. When a user requests information from your database through the Web pages you create, your CGI script extracts the relevant data and displays it in the browser. You can even allow the user to change to the data by adding, deleting, or modifying records.
As mentioned, you can set up your Web server to use a CGI script for the default document returned to the user when just your domain name is entered as the URL. This approach allows you to send different documents depending on the type of browser being used or the domain from which the request originated, giving you some control over which users see your data. You can also make a script return different data virtually every time it is called. In this way, your home page would always be different for all users, every time they accessed it.
Interactive Web Pages
CGI scripts also provide a mechanism for making Web pages interactive. By using the <FORM> tag in HTML, you can receive data directly from the user who is viewing your Web pages. All of this data can be sent to a CGI script that can then act upon it. For example, you could create a simple navigation control for your entire Web site using a drop-down list containing the names of all the Web pages on your site. The user would simply select which page he or she wanted to view, and the CGI script would return it.Bulletin boards are another way you can use CGI to create interactive Web pages. You can write scripts that will display all of the messages posted so far and allow the user to post new messages. You could make the page very simple, with just a list of messages, or you could make it a Usenet-style message area, with replies to messages underneath the original posting.
CGI lets you do all this and more. For the most part, the only limit is in your own ability to program. If the data you want to display can be formatted with HTML, you can output it from your CGI script.