{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Bill Schongar
How hard should it be to find information? Your time is valuable, and having to look through data that doesn't interest you uses up time that could be better spent elsewhere. Consider the number of people setting up their own Web sites every day, whether on a corporate or individual level. You get an idea of just how much data is being added on a daily basis. It's impossible to look through all that, even if you have a large pool of resources, because of the sheer volume and frequency of change to material you've seen previously.
Now consider people in a similar situation coming to your site. They want information, and they want it now-relevant information on demand. If you meet their needs, you've improved perception of your services. If you can accomplish that without too much work, that's all the better.
By using Wide Area Information Systems (abbreviated WAIS and pronounced "ways"), you can meet these information needs with minimum effort, regardless of the platform you're running on or the kind of information you're making available. All your data can be quickly and easily indexed, and any user can then get search access to the data through his or her preferred browser. Everything is done in plain language-no fancy terms or odd parameters-and information that matches your user's needs can be presented to your user in a variety of methods.
In this chapter, you'll become familiar with
The first step, then, is to take a look behind the scenes to understand who created the WAIS standard and why.
There's a lot of information out there. Every day something new is added to the accumulated pool, whether it's our own store of knowledge or some database growing to infinity. It's a lot to keep track of, but we sure try. Out of all that information, though, only some may be of interest to you at any given point and time. You may not care if it's snowing in New York, or how far a catapult can toss a head of lettuce, but someone out there does. Some day that someone might be you. And then wouldn't it be nice if there was an easy way to sort through it all? Some companies thought so.
In October 1989, a group of companies composed of Dow Jones, Thinking Machines Corporation, Apple Computer, and KPMG Peat Marwick saw the need for an easy way to provide text-based information systems on the corporate level and decided to do something about it. Their goal was to create an easy-to-use, flexible system for searching large amounts of distributed information in various formats built on an established standard.
For ease of use, they decided that instead of cryptic commands and proprietary interfaces, the users should be presented with a consistent access method on every platform. Because searching for information normally revolves around a keyword or concept, the easiest derivative of the access method would be a block where users could type in a word or phrase. Building on that, other interfaces could be constructed that gave lists of choices for the keywords, as well as choices for what particular database the user wanted to search.
The ability to select what to search is a definite advantage. One of the anticipated uses was for electronic publishing in wide distribution; therefore, the number of data sources someone might want to search was unlimited. After all, the goal of the system wasn't just for external people to be able to find information you make available, but for you to gain access to other systems' data as well through the same procedures. In this way you could transmit your query to a remote server if you couldn't find what you were looking for where you were. So if you were to query server A, looking for CGI libraries, it might return a reference to server B. You could then immediately repeat your search on server B, and so on.
If you were interested in data on only a single computer, selectable data sources come in handy as well. How many sites have you been to that allow you to do an overall search of the site's information, as well as narrow down the field to something like product updates? Quite a few are out there, because it's natural to want to process the information-you may be looking for something that's in a definable category, which reduces the amount of information you need to sift through.
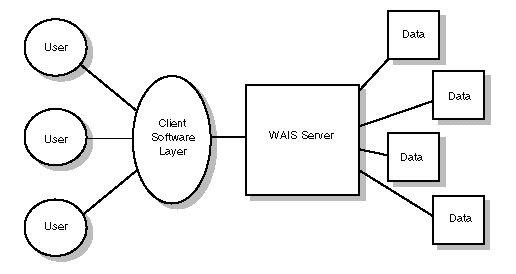
For example, look at how information can be connected when dealing with a WAIS server: multiple clients all going to one WAIS server, and that WAIS server in turn going to multiple data sources. Those data sources then could be (or could be connected to) other WAIS servers. See figure 12.1 for an example.
Figure 12.1 : A WAIS server can have multiple data sources and serve numerous clients.
Since the possible sources of information are limitless, for both local information and wide area servers, flexibility is important. Not only did the design process have to take current standards into account, but it needed to be open to improvement in the future. For building indexes, that meant that a large number of formats needed to be supported for generating the index, and the creator had choices in what that source contained and how it was formatted. For designing the methodology itself, the architecture needed to be built on an open, public standard.
Why an open standard? If two people speak the same language, they
can communicate fluently. If they don't, a lot more work is required
to get the same information from one to the other. In the same
way, the goal of the project was to make a system for corporate
business use where any database could be accessed with the same
interface. If each individual server used its own special "language"
to accept requests, it would be much more difficult to share data.
By choosing a public standard, the companies involved opened the
door to future improvements and tools from others' sources, hoping
to create enough of a base of users to have the systems be worthwhile.
The standard they choose to build on, known as Z39.50-1988, was
the 1988 revision of the Information Retrieval Service and Protocol
Standard from the National Information Standards Organization
(NISO). It met all the criteria: open, flexible, and powerful.
Working with this as a base, and extending it as necessary to
provide the text functionality they needed, they were under way
to creating a new information system.
| NISO Protocols |
The Z39.50 standard has gone through several revisions since its original draft in 1988. The latest of these, from May 1994, is referred to as Z39.50-1994 (earlier revisions are Z39.50-1988 and Z39.50-1991). The standard itself is part of the overall bibliographic format set up by the American National Standard for Information Retrieval Application Service Definition and Protocol Specification for Open Systems Interconnection. It's uniquely designed for dealing with entities such as titles, chapters, and other bibliographic entities. Although this limits its overall flexibility with respect to cataloging general documents, it would excel at tracking something such as an online legal reference, where it could perform both full-text and sectional reference searches. Medical and other similarly organized texts would also fall into the ideal category for indexing. With all the different types of information being passed back and forth, there are obviously many possible standards. NISO is one of the key players in the development and maintenance of these standards. More information on NISO and its protocols, such as Z39.50, can be found at http://www.faxon.com/Standards/NISO_Fact_Sheet.html. |
The End Result
In April 1991, the group concluded its work and released the first Internet version of WAIS. This system met the goals they had looked for, and now they hoped it would meet the needs of even more people. They made their source code freely available to developers, with the stipulation that there was no support for it. Even with that caveat to consider, it didn't take long before the system caught on.
The benefits of WAIS are ease of use (for clients and developers), full-text search capability, and support for a variety of document types. It also has a far-reaching knowledge base; it can draw on remote databases to continue the query by example started in one location. Using results from one search can lead to a more appropriate server, and so on until the desired result is found. The drawbacks can be grouped into WAIS's incapability to support relational functions, other than relevance feedback for similar documents.
When asking yourself whether WAIS is a good fit to your situation, consider the following questions:
If a large volume of text data is being tracked and it changes all the time, WAIS may be one of the best solutions. Indexing is quick and painless, and it encompasses the entire document rather than just keywords that need to be updated or accurately maintained. Frequent modification of a small segment of data doesn't preclude the use of WAIS by any means, but it opens up other database methods that might provide features better suited to the situation.
The type of data being referenced is very often text; however, in the case of graphics files, there's little benefit in a WAIS search other than finding file names. Querying by even more advanced methods, as some larger companies are moving to do in their search technology, will eventually provide more value by letting users visually or audibly specify patterns or colors that they're looking for: You might click a plaid shirt pattern to find shirts in a manufacturer's database with similar patterns or colors; or you might select a region of a picture to find other images with similar components (such as a bridge, water, or rivers). Although this type of data could be replicated in a descriptive file that served as a companion for each image, the manual creation of that other file would belie the purpose of being able to index the graphics by themselves.
If you were creating a customer database to track who ordered what, how much it would cost, and when it would arrive, WAIS wouldn't be the ideal candidate. On the other hand, if you had a sheaf full of technical documents for customers and were constantly adding things and revising old ones, WAIS would be perfect. Each situation brings with it a little addition or angle on a specific need that not every system will be able to address. By knowing whether your own needs are compatible with what WAIS provides, a combination of WAIS and something else, or just something else entirely, the chances that you'll get the right search system with the least amount of work on your part are greatly improved.
Think about a library's card catalog. Rather than duplicate all the data from every book, the card catalog mentions key references to help you conduct an organized and efficient search. The advantage that a WAIS database has over an old-fashioned card catalog is that even though the card catalog can contain only summary information about the documents it knows about, WAIS provides a search method that includes the contents of the documents as well as their summary information.
Because a WAIS database is really just an index of documents,
creating the database is a matter of going through each document
and creating tables of words from the documents, titles, document
locations, and other data that the search program can reference
later on. The capability that WAIS has to be flexible in what
people can search through leads to a number of different file
types supported for indexing (or parsing). The utility
that does this indexing is, appropriately enough, WAISINDEX. Some
of the more common formats it can parse are included in table
12.1.
| File Type | Description |
| bibtex | bibtex/latex format |
| dash | A long line of dashes separates document entries within a file |
| dvi | DVI format (Device Independent Printer output) |
| gif | CompuServe Graphics Interchange Format graphics (file names only) |
| html | Hypertext Markup Language |
| para | Each paragraph separated by a blank line is a new document |
| pict | PICT graphics (file names only) |
| ps | PostScript format |
| text | Plain text |
| tiff | TIFF graphics (file names only) |
Additional formats may be available depending on your platform and the software version you're using. One version supports Microsoft Knowledge base files; some even allow you to define your own document types. To be sure of what you can and can't parse with WAISINDEX, check the latest version of your toolkit documentation.
Creating the database is an easy job. If WAISINDEX supports the
types of files you want to include in your database, place them
where they're going to reside and run WAISINDEX with command-line
options that will give you the type of information you want in
your database. What kind of command-line options? The two that
are most often used are as follows:
| Purpose | |
| Specifies a database name | |
| Informs WAISINDEX of the type of files being parsed |
A sample command line might look something like the following:
% WAISINDEX -d /home/mydata -T HTML /files/*.HTML
This command line creates a database named mydata in the /home directory, setting the default type of file to parse to be HTML and indexing all the HTML files in the /files directory. Depending on the number of files you have to sort through, this process can take up a good deal of disk space and processor time; however, as an example, most indexes of less than 100 documents will be created in less than one minute.
Creating your database was done for one reason: to allow people to search it. The indexed tables of data allow keyword searches to be sent from any user, to run through the appropriate mechanism, and to have results sent back. What's the "appropriate mechanism"? Well, you have a choice: WAISSEARCH or WAISQ.
WAISSEARCH is the remote server for data. Like your HTTP server, FTP server, or anything else that listens to a port to provide feedback to requests sent to it, WAISSEARCH can be run in the background to process all those requests. On UNIX, it's started at the command line as a background process, whereas in NT and some other operating systems, it can be run as an automatic service. In either case, it's really concentrating on requests that come from some point outside your machine, rather than something local such as your own testing of the database.
WAISQ is the local search program. It doesn't sit and listen for information; it's executed from the command line and does all the searching right then and there. It's the easiest way to search through your database as a test for data that you know should be there. It's also the component that's used in locally executed scripts to grab input and bring it back to some program, such as a CGI-based script used with your Web server.
When a request comes in (locally or remotely), it has two basic components: the source to search through and what to search it for. Assuming the database can be accessed, the "seed words" of the query are checked against the source table of the database, and the output is generated. In the simplest case, a local query could be created to contain those two components, as in the following:
% WAISQ -d /home/mydata pancakes
In the preceding code, mydata is the database being specified (note that the -d option is common between indexing and searching for specifying a database), and pancakes is the keyword being searched for.
The searches performed aren't limited to that very generic format. Because WAIS supports Boolean operations, it could be a search for pancakes and syrup but not waffles or blueberries. This allows you to filter out more of the documents, returning only what's more relevant to your reason for searching. Another function of WAIS takes relevance one step further with relevance feedback, the capability to find a document that matches your parameters and send it back to ask for more documents like it.
When the server or local program processes your query, all the items that match (up to any preset limit set by the server to keep processing time down) are returned to you. These pieces of information are also returned with one large benefit: ranking. If you receive 50 documents after your search, the first one in the list is the one that best matched your query. Normally, this is word-frequency based, which lends itself nicely to a little trick that people often use when listing their Web pages with a search site with this type of relevance ranking.
Because each occurrence of a particular word in the document is a match and results in an increase in the score, placing several hundred copies of that word inside the document in an invisible place will cause most searches to be very favorable toward ranking your document at the top. For instance, if you have an HTML document on recycling that you want to be on the top of the list, you can put the words recycle and recycling in a comment block at the bottom of the document, repeated several hundred times. Although you may mention it only twice in context, the search engine that parses sees all those occurrences and thinks your document must be the be-all and end-all of recycling information. Of course, this is the whole reason behind having different parsing formats: Using the correct parsing format, or setting up your own (as allowed by certain toolkits), allows you to strike comment fields and such from the ranking order. Of course, if you type it in very small letters on a non-comment portion of the document, that will make it by a comment-eliminating parse format.
When someone is trying to access the information you've placed in a WAIS database, three separate entities are trying to communicate: the client, your Web server, and your data's WAIS server. Communication between the client and your Web server is an easy two-way street and would most often be taken care of through the HTTP protocol. The level of difficulty in getting the client's request from your Web server to your WAIS server's data and back to your Web server for sending is another matter entirely. You need to establish a "gateway" between your Web server and the WAIS server, one that will do all the fetching and formatting for you whenever a request is made. The most common method of establishing this gateway is to use a CGI script (and it's important to note that this isn't necessarily the same as "write a CGI script"), but an option that's becoming more popular and more accessible is automatic integration between the HTTP server you use and the WAIS protocol.
If you're fortunate (or "foresightful") enough, you may have a server that supports automated integration of a WAIS database. These servers normally ship with a version of the WAIS toolkit for their platform to keep from even needing to hunt for the software in the first place. An example of this server-WAIS integration can be seen in Process Software's Purveyor server for NT and is illustrated in the following example.
You've created a WAIS database called "manual" that indexes a particular reference manual by page to provide a search function for your online HTML version of the manual. As a prototype, you create a simple form to provide a keyword search field. Later, this can be integrated into a more elegant form after everything works to your satisfaction, but right now you're in a time crunch and just need to see it work. You start out with an HTML page, using the <ISINDEX> tag to provide the search field. It looks something like this:
<HTML> This is a prototype search page. <ISINDEX PROMPT="Enter words to search for here:"> </HTML>
| NOTE |
Defining searchable indexes in an HTML document relies on support for the <ISINDEX> tag to function properly. Most browsers today support <ISINDEX>, but not all. If you know that certain users who'll want access to your data will be using a package that doesn't support <ISINDEX> tags, many server-integrated search packages won't be right for your situation. |
Now save the HTML document by placing it in the same directory as the WAIS database and by naming it manual.htm. When you view this document in a browser that supports the <ISINDEX> tag, it looks like figure 12.2.
Figure 12.2 : You can use the <ISINDEX> tag to create your search page.
Now that you're finished, you decide to test it. That's right-you're already done. That's exactly the point of server integration: It removes almost all the work from the developer. By using the same name for the database and the HTML page, all the associative work that you would normally have to perform is done automatically by the Purveyor server. No external scripts, no messy configuration, nothing else to obtain-everything comes in one package.
Because they recognize the advantages of this type of integration, a growing number of other companies and individuals are providing this type of integration with their server packages, whether through support for freeWAIS or their own proprietary tool. To see whether your server package, or one that you're interested in, has built-in support for searches (or other features you're looking for), there's a well-maintained server comparison chart for almost any server package imaginable at http://www.proper.com/www/servers-chart.html.
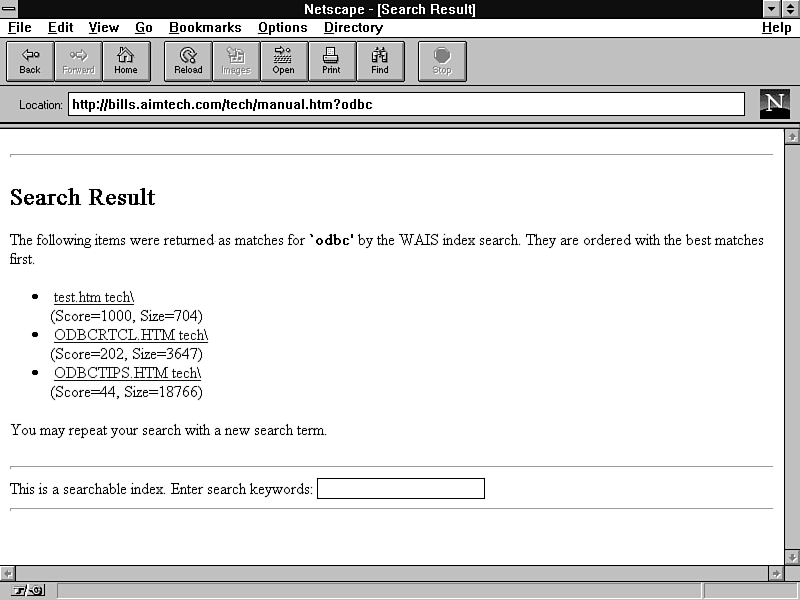
To understand the drawbacks of this particular method, figure 12.3 shows the output from a sample database created to be "manual." The query used was odbc, which resulted, as it should, with two hits.
Figure 12.3 : Some servers have integrated WAIS- querying cap-abilities.
The formatting of the output isn't terrible, but it's not what most people would prefer to have. Things such as inserting a corporate or personal logo, providing instructions for narrowing a broad search, or even just general formatting on the page to match a theme are all options that may or may not be available with a server-integrated package. If it can't be done for you, you'll have to do it yourself.
You might choose script-based access to a WAIS database over server-integrated packages for a number of reasons. Two of the more common reasons are as follows:
In these cases, you'll still be providing users with a generic interface, but the script will intercept the data on the way out and on the way back to provide you with whatever level of customization you want.
To function as a gateway, keywords and other database-related selection data from the user will need to be gathered and used as part of that query, more often than not retrieved from a forms-based interface. Because many CGI libraries process forms input, creating a suitable form and constructing a script to gather the information and store it to variables isn't a real challenge.
The next step in the script is to use those variables to call the WAISQ program and query the database with the gathered information, gathering the data that WAISQ returns into a file or into standard input (STDIN) so it can be parsed. It's there, in parsing, that most of the work begins to create the format you're looking to output. Fortunately, a great deal of work on doing just that has already been performed by other programmers, and they've been kind enough to make it available to people everywhere to show how it's done.
This series of Perl scripts is a good example of evolution in action. The first version, WAIS.PL, took the first major steps by providing a basic method of executing the WAIS query and feeding back results that weren't just a jumble of plain text. Eric Lease Morgan decided to take that a step further with Son-of-WAIS, making the output more "human-readable," as he called it, so users could understand what they were getting back with less effort. Soon after, Mike Grady built on top of Son-of-WAIS's functionality to add even more things, including the option to add highlighting of the matching text. The result of Mike's work is Kid-of-WAIS, the next generation of the WAIS gateway scripts.
To get more information on Son-of-WAIS or Kid-of-WAIS, try the following locations:
http://dewey.lib.ncsu.edu/staff/morgan/son-of-wais.html
http://www.cso.uiuc.edu/grady.html
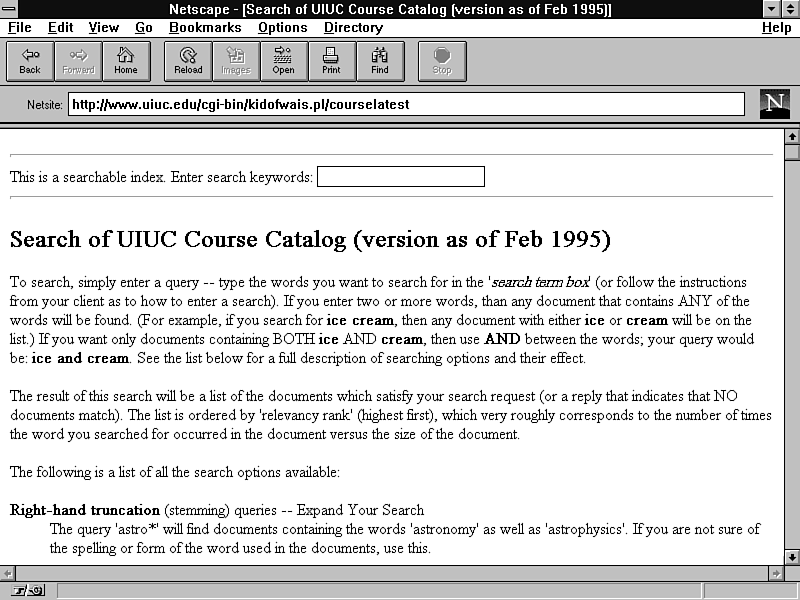
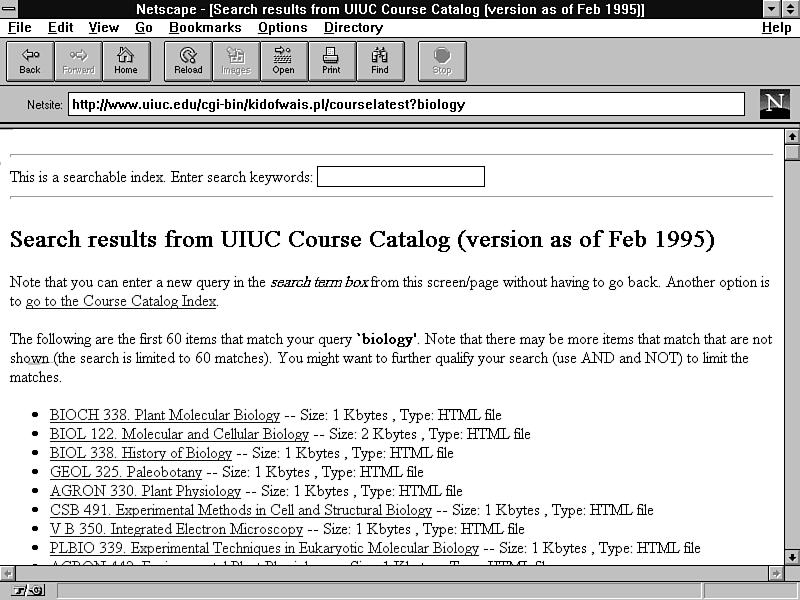
To see an example of Kid-of-WAIS in action, figures 12.4 and 12.5 show a set of search and result screen shots, respectively.
Figure 12.4 : Kid-of-WAIS.pl uses the standard search interface.
Figure 12.5 : Kid-of-WAIS has a variety of output formatting options.
Although originally part of the components for the University
of Dortmund's extension of freeWAIS that added structured field
support and a variety of other cool enhancements, SF-Gate is a
gateway interface that will also function with any standard WAIS
server. One of the more intriguing things about it, though, is
that it's not quite WAIS-based. It communicates directly with
the underlying protocol and bypasses WAISQ entirely. This is a
neat approach. Also, the script, written in Perl, comes with a
question-and-answer-based installation script and a separate configuration
script you can modify to suit your own needs, rather than rely
on fields within the forms you create. You can find out more about
SF-Gate and all the benefits of freeWAIS-SF at http://ls6-www.informatik.uni-dortmund.de/freeWAIS-sf/README-sf.
| NOTE |
SF-Gate's direct communication is another bit of innovation made possible by the open Z39.50 standard. By not being limited to just what other people had built on top of it, the folks at U of D could take ingenuity and turn out a great idea. |
An excellent program written in C to bring more functionality into a CGI gateway is Kevin Hughes's WWWWAIS.C. It's small, fast, and efficient. In addition to his contribution to gateways, Kevin has come up with an efficient and easy search and indexing system of his own called SWISH (Simple Web Indexing System for Humans). Find about them both at http://www.eit.com/software.
Throughout this chapter, discussion has focused on WAIS, but one of the first things you'll encounter on the Net when using WAIS is the term freeWAIS. What's the difference? freeWAIS is the implementation of WAIS that the CNIDR (Center for Networked Information Discovery and Retrieval) began maintenance of some years back after Thinking Machines Corporation decided it was time to pass on support of the project to someone else. CNIDR provided a public area where ideas and fixes for a WAIS implementation could be focused, and released new builds to accommodate the needs. Some time back, the literature on CNIDR's Web site (http://www.cnidr.org) specified that the center could no longer make maintenance releases available, because it was going to focus on other Z39.50 implementations (its ISite software is the primary result of this). However, that was at version 0.3, and version 0.5 is on the center's FTP site as of this release, along with the outdated support notice. Even with the center's new tools, one can hope that versions of freeWAIS are still made available on its site for some time yet to come.
If you're ready to try WAIS for yourself, you'll want to get a hold of the right software for the right platform. Depending on your platform, you can have any number of choices, but freeWAIS is the most straightforward to experiment with and the most commonly used. To cover two common networking platforms, first look at obtaining and installing freeWAIS for a UNIX system; then look at obtaining and installing a version of freeWAIS for Windows NT. Also, if you want to investigate some of the alternative tools or get information on alternative platforms, the reference list at the end of this chapter will point you in the right direction.
Whenever you obtain freeWAIS or a derivative, you're really getting four components:
Because installation procedures vary from system to system and may change from version to version, review the documentation of your software version for the most accurate installation instructions. Also, if you aren't the system administrator for your machine or your network, you may want to check with the systems administrator before installing, so you can obtain additional information or access permissions for the system you'll be using.
You can obtain the freeWAIS software for almost any UNIX flavor directly from CNIDR. Via anonymous FTP, go to cnidr.org/pub/NIDR.toold/freewais. After you get there, you'll notice a number of builds of different versions for different platforms. As of this writing, the latest build available was 0.5, but newer builds may be there now. Download the appropriate version for your flavor of UNIX and then unpack it. Most builds are tarred and gzipped; therefore, in most cases you would do something like the following at the UNIX command prompt:
% gunzip -c freeWAIS-0.X-whatever.tar.gz | tar xvf -
Depending on your platform, the version of freeWAIS you obtain, and a variety of other system-specific details, the exact steps to create a functioning freeWAIS installation will vary. As a general rule, though, you'll need to do the following:
| NOTE |
While an ANSI C compiler is the default for compiling freeWAIS on a UNIX system, other libraries are available for compiling with Gnu CC and non-ANSI C. Check the freeWAIS documentation for the most current details, based on your version and platform. |
TOP=/users/me/freewais
make aix
| NOTE |
X Window users have more work to do when compiling a freeWAIS build. Use Imakefile to set the location of necessary X resources on your system, so that the result will act normally in your window-management system. |
Although most server utilities start out on UNIX, ports to other platforms are becoming more common. For Windows NT servers, a ported version of freeWAIS 0.3 has been made available by EMWAC (the European Microsoft Windows Academic Centre) in its WAIS toolkit. As of this writing, version 0.7 was the latest version. However, you'll want to check with EMWAC to see what its latest version is when you're ready to use the utility. Versions are available for all flavors of NT-386-based, Alpha, and Power PC-at ftp://emwac.ed.ac.uk/pub/waistool/.
Again, full installation instructions are provided in the documentation, but there are two important things to be aware of that are specific to the NT port of freeWAIS:
Because further instructions (and most scripts) refer to WAISQ, you'll need to take this into account.
With so many people out there using WAIS, you can turn to a number of places for more information on use, integration, and even future developments.
The WAIS FAQ at Ohio State University is an excellent starting point and can be found at
http://www.cis.ohio-state.edu/hypertext/faq/usenet/wais-faq/getting-started/faq.html
RFC (Request For Comments) 1625 deals with WAIS and the Z39.50 protocol, and can be seen at
ftp://ds0.internic.net/rfc/rfc1625.txt
For a list of all the companies and agencies involved with making solutions based on the Z39.50 protocol, the Library of Congress maintains a master list at
http://lcweb.loc.gov/z3950/agency/register.html
The primary newsgroup for discussion of WAIS issues, comp.infosystems. wais, has everything from technical discussions to inquiries by people just getting started. Like most other Internet resources, it has a FAQ (its URL is listed in WWW Resources) that provides a great deal of information.
A number of mailing lists are available. The following list includes some general-interest mailing lists taken from the comp.infosystems.wais FAQ:
If you'd like to see the full list of mailing lists available, the FAQ has it at
http://www.cis.ohio-state.edu/hypertext/faq/usenet/wais-faq/getting-started/faq-doc-4.html
A lot of new tools are out there. A few of the more interesting "meta-indexers" and similar tools can be found with just a search on parameters of WAIS or Text search at your favorite Web searching site. Because the list changes almost every week, it's hard to know what the most intriguing ones will turn out to be. However, a few you might want to search on individually are ISite (from CNIDR), Glimpse, GLOSS, and Harvest, just to start you on the trail.