{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Rod Clark
Finding information tucked away in complicated, unfamiliar Web sites takes time. Often enough, users want to correlate the information in ways that the authors and the menu builders never envisioned. Especially at large sites, no matter how good the navigation is, finding all the files that mention a topic not listed separately on the menus can be difficult and uncertain. After a few failed attempts to find something at a new site, most users give up and move on.
Even the best Web site with a good menu system can present a faster, friendlier interface to its information by offering a supplementary search tool. The good news is that more and more good search tools are becoming available.
In this chapter, you'll learn more about
Today's search tools have much to offer compared to the tools of a few years ago. Many search techniques remain the same, but there have been some new developments. One active area in search engine development is concept-based searching.
Some newer search tools can cross-check many different words that people tend to associate together, either by consulting thesauri while carrying out their search operations, or by analyzing patterns in the files in which the query terms appear and then looking for similar documents. Some use a combination of both techniques.
The following sections discuss a few things to keep in mind when considering search tools for your site.
A review of some terminology and of common search functions may help you better choose among the search tools available. You'll also need to be familiar with what follows before you dive into the source code for the Hukilau 2 Search Engine later in the chapter.
Most search engines let you conduct searches in more than one way. Some common options include AND, OR, and exact-phrase searches. Each of these has its place, and it's hard to get useful results in every situation if you can use only one of them. Several search engines also allow you to use more complex syntax and specify other operators, such as NOT and NEAR.
In general, to narrow a search in a broad subject area, you can AND several search terms together. You might also search for whole words instead of substrings. To narrow things even more, you can search for an exact phrase and specify a case-sensitive search.
To broaden the scope of a search, you can OR several search terms together, use a substring search instead of a whole-word search, and specify case-insensitive searching.
OR is the default for some popular search tools; AND is the default for others. Because the results of an OR search are much different from those of an AND search, which you prefer depends on what you're trying to find.
If you consistently prefer to use a search method other than the
default for a given tool, and it runs as a CGI program on another
site, you can generally make a local copy of its search form and
edit its settings to whatever you like.
| NOTE |
Here's an example of this approach that sets consistent AND defaults for a number of Net search services. You can individually download these drop-in search forms and include them in other HTML pages. Http://www.aa.net/~rclark/search.html |
Some search tools let you search for an exact phrase. For example, the web-grep.cgi UNIX shell script in the "Searching a Single File, Line by Line" section later in this chapter searches only for exact phrases. But with it, you can type an exact phrase (or word fragment) that also happens to be a substring of some other words or phrases. The script then finds everything that matches, whether or not the match is a separate whole word. But this still isn't as flexible as many users would like.
Suppose that a friend mentions a reference to "dogs romping in a field." It could be that what he actually saw, months ago, was the phrase "while three collies merrily romped in an open field." In a very literal search system, searching for "dogs romping" could turn up nothing at all. Dogs aren't collies. And romping isn't romped. But the query "romp field" might yield the exact reference, if the same very literal tool searches for substrings.
Whole words start and stop at word boundaries. A word boundary is a space, tab, period, comma, colon, semicolon, hyphen, exclamation point, question mark, quotation mark, apostrophe, line feed, carriage return, parenthesis, or other such word-beginning or word-ending character.
Now let's say that you've searched for romp field and found hundreds of references to romper rooms, left fielders, the infield fly rule, and, of course, the three romping collies. To narrow these search results further and gather the references to the article about romping collies into a shorter search results list, you could run an AND search for the whole words three collies romped.
Many search engines rank search results from the most relevant to the least relevant. No one agrees on the best relevance ranking scheme. Some engines simply rank the results by how many instances of the search keywords each file contains. The file with the most keywords is listed first on the search results page.
Other search tools weight keywords found in headings and in other emphasized text more than keywords found in plain text. Some programs take into consideration the ratio of keywords to total text in the file, and also weight the overall file size. All of these methods are appropriate to consider when programming relatively simple CGI search scripts,
Search engines rarely search through the actual document files on a Web site each time you submit a query. Instead, for the sake of efficiency, they search separate index files that contain stored information about the documents. Building index files is a slow process. But once built, the index files' special format lets the engine search them very fast. Sometimes the index files can take up as much space on the server's disk drives as the original document files.
The index files contain a snapshot of the contents of the document files that was current whenever the search engine last ran an indexing pass on the site. That might have been a few hours ago, yesterday, or last week. Often, a search engine's indexing process runs as an automatically scheduled job in the dead of night, when it won't slow down more important activities. Sometimes you can find out when the indexes were last updated at a site, and sometimes you can't.
Some large, complex search engines continuously update their indexes, incrementally. This doesn't mean that all the index entries are always up to the minute. Some portion of the entries are very current, and the rest range in age depending on how long it takes the indexing software to traverse the entire document library.
There are many different formats for index files, and comparatively few interchangeable standards. Some of the more complex search engines can read several types of index files that were originally generated by different kinds of indexing software, such as Adobe PDF "catalogs."
Conventional query syntax follows some precise rules, even for simple queries, as you saw in the preceding section. But as you also saw, people don't usually think overtly in terms of putting Boolean operators together to form queries.
Concept-based search tools can find related information even in files that don't contain any of the words that a user specifies in a search query. Such tools are particularly helpful for large collections of existing documents that were never designed to be searched.
One way to broaden the reach of a search is to use a thesaurus, a separate file that links large numbers of words with lists of their common equivalents. Some newer thesauri automatically add and correlate all the new words that occur in the documents they read as they go along. A thesaurus can be a help, especially to users who aren't familiar with a specialized terminology. But manually maintaining a large thesaurus is as difficult as maintaining any other large reference work. That's why some new search engines' self-maintaining thesauri statistically track the most common cross-references for each word, so that the top few can be automatically added to a user's query.
Some, but not all, search engines offer stemming. Stemming is trimming a word to its root, and then looking for other words that match the same root. For example, wallpapering has as its root the word wall. So does wallboard, which the user might never have entered as a separate query. A stemmed search might serve up unwanted additional references to wallflower, wallbanger, wally, and walled city, but catching the otherwise missed references to wallboard could be worth wading through the extra noise.
Stemming has at least two advantages over plain substring searching. First, it doesn't require the user to mentally determine and then manually enter the root words. And it allows assigning higher relevance scores to results that exactly match the entered query and lower relevance scores to the other stemmed variants.
But stemming is language-specific, too. Human languages are complex, and a search program can't simply trim English suffixes from words in another language.
Several newer search engines concentrate on some more general non-language-based techniques. One such technique is pattern matching, used to find similar files. For example, given a file about marmosets, a concept-based search engine might return references to some other files about tamarins, even though those files don't contain the word marmoset. But many other aspects of the marmoset files and the tamarin files would be very similar. (They're both South American monkeys.)
Thesauri can help provide this kind of capability, to an extent. But some new tools can analyze a file even if it's in an unknown language or in a new file format, and then find similar files by searching for similar patterns in the files, no matter what those patterns actually are. The patterns in the files might be Swahili words, graphics with Arabic characters, or CAD symbols for freeway interchanges, for all the search program knows.
Building specific language rules into a search engine is difficult. What happens when the program encounters documents in a language it hasn't seen before, for which the programmers haven't included any language rules? There are people who have spent their whole adult lives formally recording the rules for using English and other languages, and they still aren't finished. We hardly think of those rules, because we've learned (or accumulated) them in our everyday human way-by drawing conclusions from comparing and summing up a great many unconscious, unarticulated pattern matching events.
Even if you don't know or can't explain the rules for constructing
the patterns you see, whether those patterns are in human language,
graphics, or binary code, you can still rank them for similarity.
Yes, this one matches. No, that one doesn't. This one is very
similar, but not exact. This one matches a little. This one is
more exact than that one. This is the approach that some of
the newer search engines take to analyzing files for content similarity.
They look for patterns, nearness, and other such qualities, and
use fuzzy logic and a variety of weighting schemes.
| NOTE |
An active Usenet newsgroup, comp.ai.fuzzy, is devoted to explaining fuzzy logic. You can read what the experts have to say there to find out much more about this rapidly evolving area. |
As businesses integrate their Web sites more into their everyday
activities, they're adding more and more Web-accessible documents.
At a busy site, it may be hard to keep up with the latest additions,
even from hour to hour. Search functions can supplement ordinary
links, to help users more easily sort out the flood of information.
| TIP |
If you offer a search capability at your site, you should consider making it easily accessible from any page. I've been to a few sites where it took a wild-goose chase to get back to the special page with the link to the search tool, among the welter of other pages on the site. |
In rapidly changing subject areas, it makes sense to link specific documents to menu pages but to avoid or minimize links from within documents to other specific documents, especially to inherently dated ones. Such a design, which minimizes document-to-document cross links and instead emphasizes links to menus and to a search function, can help users find the most recent material, even from pages that were built weeks or months ago. It also makes page maintenance easier for the administrators who maintain the site.
To provide users with a search function that's tailored to a given subject, you can use a hidden form that sends your search engine a preset query about the subject.
The hidden form fits easily into a page design because its only visible element is a submit button. To avoid confusion, you can describe the search's special purpose in the button text, rather than use the default Submit button text or a generic word such as Search.
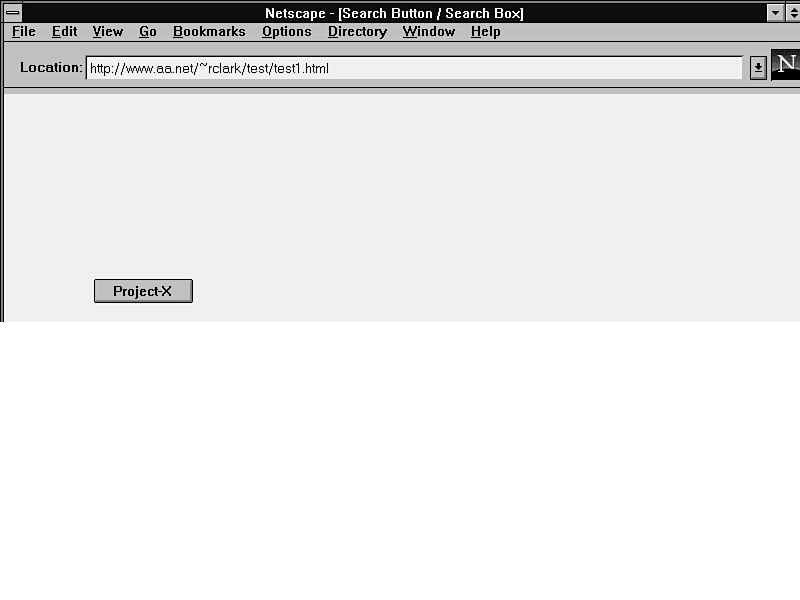
The first example, shown in figure 11.1, shows a button that's part of a hidden search form. The form's hidden text field is preloaded with the query keywords that you'd use to stamp all new files on the related subject.
Here's the HTML code for the hidden search form in figure 11.1:
<FORM METHOD="POST" ACTION="http://www.substitute_your.com/cgi-bin/hukilau.cgi"> <INPUT TYPE="HIDDEN" NAME="Command" VALUE="search"> <INPUT TYPE="HIDDEN" NAME="SearchText" value="Project-X"> <INPUT TYPE="SUBMIT" VALUE=" Project-X "><br> </FORM>
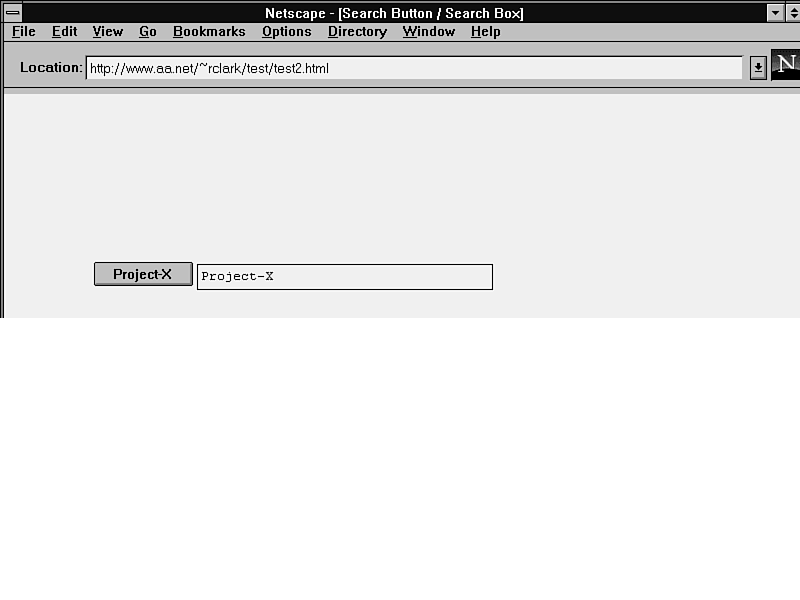
The next example, shown in figure 11.2, shows the same drop-in search form, but with a visible single-line text input box that's preloaded with the same search keywords as in the first example. The difference is that this form lets the user type some added words, if needed, to narrow the search.
Figure 11.2 : This is the same form, but with a visible input box preloaded with a query keyword.
Here's the HTML code for the compact search form in figure 11.2 that includes a visible text input box:
<FORM METHOD="POST" ACTION="http://www.substitute_your.com/cgi-bin/hukilau.cgi"> <INPUT TYPE="HIDDEN" NAME="Command" VALUE="search"> <INPUT TYPE="SUBMIT" VALUE=" Project-X "> <INPUT TYPE="TEXT" NAME="SearchText" SIZE="36" value="Project-X"><BR> </FORM>
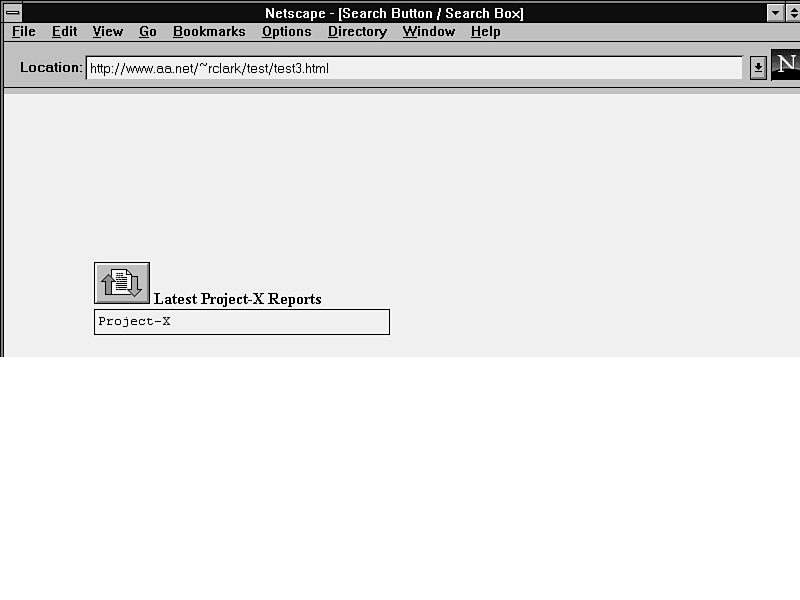
The next example shows the same drop-in form as before (see fig. 11.3). The only change is that here, an image is used as a button.
Figure 11.3 : This compact search form uses an image for a button.
The HTML code for the search form in figure 11.3 displays a visible input box and uses an image instead of a text submit button:
<FORM METHOD="POST" ACTION="http://www.substitute_your.com/cgi-bin/hukilau.cgi"> <INPUT TYPE="HIDDEN" NAME="Command" VALUE="search"> <INPUT TYPE="IMAGE" SRC="http://www.aa.net/~rclark/button.gif" alt=" Project-X " ALIGN="bottom" border ="0"><b> Latest Project-X Reports</b><br> <INPUT TYPE="TEXT" NAME="SearchText" SIZE="36" value="Project-X"><BR> </FORM>
These forms call the Hukilau 2 search script, which is described in the "Hukilau 2" section later in this chapter. This search script doesn't use a stored index. Instead, it searches through the HTML files in a specific directory (but not its subdirectories) in real time. Although that's a slow way to search, sometimes it can be useful because it always returns absolutely current results.
A search script such as this one is a good tool to use when it's okay to use the computer's resources inefficiently, to find the very latest information. Although this kind of script lets you see up-to-the-second file changes, site administrators might not want too many users continually running it, because it exercises the disk drives and otherwise consumes resources. Of course, you can always use the same kind of hidden form to call a more efficient search engine that uses a stored index.
Time Daily's Latest News page is a good example of embedding search forms in a page. Each search button on the Time page brings up a list of whatever articles are available in the archives about the related subject, as of the moment you perform the search. To view the Time Daily page, use the following URL:
http://pathfinder.com/time/daily/time/1995/latest.html
When searching for something, users often have in mind no more than a few scattered and fragmentary details of what they want to find. Offering only page titles sometimes isn't enough for the user to make a good decision.
Showing context abstracts from the files reduces the number of trial-and-error attempts that users make when choosing from the search results list. Displaying large enough abstracts so that the user makes the right choice the first time instead of the second or third time is an important usability consideration. Programmers are often tempted to display smaller abstracts, in the interests of efficiency, than are really needed to minimize trial-and-error file viewing.
Some search engines let the user choose the size of the context abstracts, along with other search conditions, by using a drop-down menu or radio buttons on the search form. This is a worthwhile option to include, if the CGI program supports it.
Context abstracts taken from the text surrounding the user's search keywords are often more useful than fixed abstracts taken from the first few lines of a file. Not every search engine can produce keyword-specific abstracts.
Some of the simpler freeware search engines don't provide context abstracts, but do rank files by relevance or report the numbers of matching words found in each file.
Adding keywords to files is particularly important when using simpler search tools, many of which are very literal. But even the simplest search scripts can work very well on pages that include well-chosen keywords.
Keying files by hand is slow and tedious. It isn't of much use when faced with a blizzard of seldom-read archival documents. But new documents that you know will be searched online can be stamped with an appropriate set of keywords when they're first created. This provides a consistent set of words that users can use to search for the material in related texts, in case the exact wording in each text doesn't happen to include some of the relevant general keywords. It's also helpful to use equivalent non-technical terminology that's likely to be familiar to new users.
Sophisticated search engines can give good results when searching documents with little or no intentional keying. But well keyed files produce better and more focused results with these search tools, too. Even the best search engines, when they set out to catch all the random, scattered unkeyed documents that you want to find, can't help but return information that's liberally diluted with info-noise. Adding keywords to your files helps keep them from being missed in relevance-ranked lists of closely related topics.
To help find HTML pages, you can add an inconspicuous line at the bottom of each page that lists the keywords for the page, like this:
Poland Czechoslovakia Czech Republic Slovakia Hungary Romania Rumania
This is useful. But some search engines assign a higher relevance to words in titles, headings, emphasized text, name= tags and other areas that stand out from plain text. The next few sections consider how to key your files in ways other than by placing extra keywords in the body of the text.
You can put more information than simply the page title in the <HEAD> section of an HTML page. Specifically, you can include a standard Keywords list in a <META> tag in the <HEAD> section.
People sometimes use <META> tags for other non-standard information. But search engines should ordinarily pay more attention to the <META> Keywords list. The following is an example:
<HEAD> <META HTTP-EQUIV="Keywords" CONTENT="Romania, Rumania"> <TITLE>This is a Page Title</TITLE> </HEAD>
Many but not all search engines index comments in HTML files. If yours does, putting "invisible" keywords in comments is a more flexible way to add keywords than putting them in name= statements, because comments have fewer syntax restrictions.
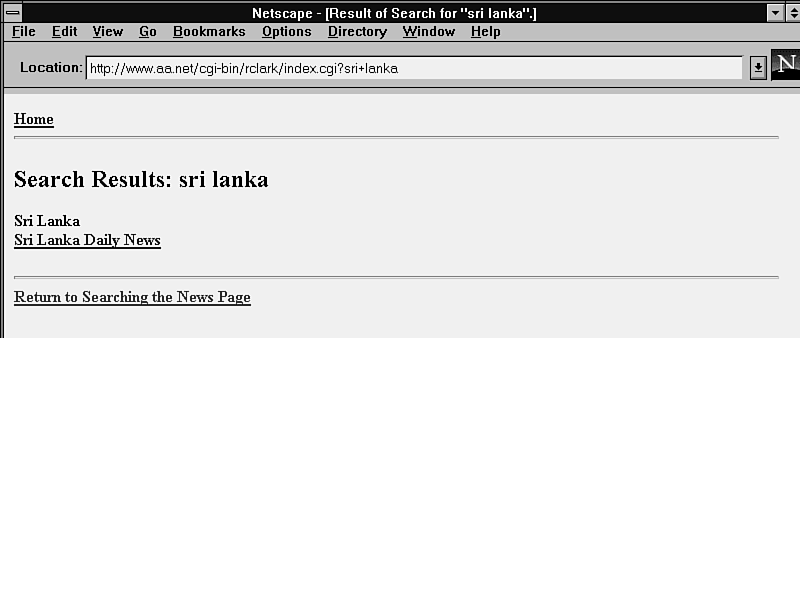
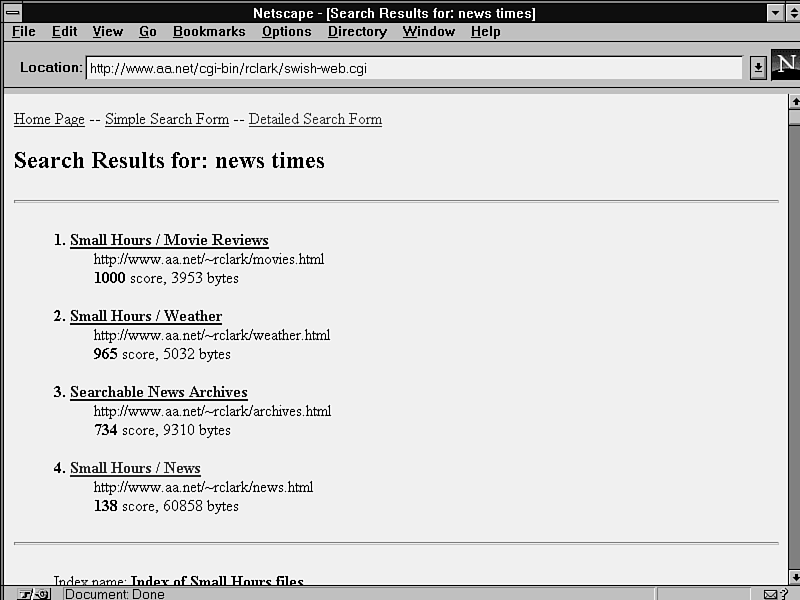
The next example shows some lines from an HTML file that lists links to English-language newspapers. The visible link names on the individual lines don't always include words that users would likely choose as search queries. That makes no difference when finding the entire file. But with a search tool that displays matches on individual lines in the file, such as web-grep.cgi, a query has to exactly match something in either a particular line's URL or in its visible text. That's not too likely with some of these lines. Only one of them comes up in a search for Sri Lanka (see fig. 11.4). None come up in a search for South Asia, which is the section head just above them in the file.
Figure 11.4 : In this unkeyed file, the search doesn't find all
<b><a href="http://www.lanka.net/lakehouse/anclweb/dailynew/ select.html">Sri Lanka Daily News</a></b><br> <b><a href="http://www.is.lk/is/times/index.html">Sunday Times </a></b><br> <b><a href="http://www.is.lk/is/island/index.html">Sunday Island </a></b><br> <b><a href="http://www.powertech.no/~jeyaramk/insrep/">Inside Report: Tamil Eelam News Review</a></b><i> - monthly</i><br>
To improve the search results, you can key each line with one or more likely keywords. The keywords can be in <!--comments-->, in name= statements, or in ordinary visible text. Some of these approaches are more successful than others. The next three code snippets show examples of each of these ways to add keywords to individual lines in a file.
This first listing shows how you can add keywords as HTML comments:
<!--South Asia Sri Lanka--><b><a href="http://www.lanka.net/ lakehouse/anclweb/dailynew/select.html">Sri Lanka Daily News</a> </b><br> <!--South Asia Sri Lanka--><b><a href="http://www.is.lk/is/ times/index.html">Sunday Times</a></b><br> <!--South Asia Sri Lanka--><b><a href="http://www.is.lk/is/ island/index.html">Sunday Island</a></b><br> <!--South Asia Sri Lanka--><b><a href="http://www.powertech.no/ ~jeyaramk/insrep/">Inside Report: Tamil Eelam News Review</a> </b><i> - monthly</i><br>
The next listing shows similar keywords in name= statements. But HTML doesn't allow spaces in name= statements, which prevents searching for whole words instead of substrings. You also can't include multiple identical name= statements in the same file, to relate items together for searching, because each name= statement must be unique. So overall, putting keywords in name= statements isn't the best choice here, although it might be workable with some search tools.
<b><a name="southasiasrilankadaily" href="http://www.lanka.net/ lakehouse/anclweb/dailynew/select.html">Sri Lanka Daily News</a> </b><br><b><a name="southasiasrilankatimes" href="http://www.is.lk/is/ times/index.html">Sunday Times</a></b><br> <b><a name="southasiasrilankaisland"href="http://www.is.lk/is/ island/index.html">Sunday Island</a></b><br> <b><a name="southasiasrilankainside" href="http://www.powertech.no/ ~jeyaramk/insrep/">Inside Report: Tamil Eelam News Review</a> </b><i> - monthly</i><br>
The next listing illustrates some difficulties with adding consistent search keywords to plain text. Repeating the keywords on several lines can be awkward in lists like this one. For example, there's no good way to repeat South Asia on each line here.
<b><a href="http://www.lanka.net/lakehouse/anclweb/dailynew/ select.html">Sri Lanka Daily News</a></b><br> <b><a href="http://www.is.lk/is/times/index.html">Sri Lanka Sunday Times</a></b><br> <b><a href="http://www.is.lk/is/island/index.html">Sri Lanka Sunday Island</a></b><br> <b><a href="http://www.powertech.no/~jeyaramk/insrep/">Inside Report: Tamil Eelam News Review, Sri Lanka </a></b><i> - monthly </i><br>
The search results from the file with the keywords added in HTML comments (see fig. 11.5) are more consistent than the search results from the unkeyed file (refer to fig. 11.4).
You can scan a file (which can be an HTML page) and display all the matches found in it. The web-grep.cgi script, shown in listing 11.1, is a simple tool that you can use to do this. If the file being searched contains hypertext links that are each written on one line (rather than spread over several lines), each line on web-grep's search results page will contain a valid link that the user can click.
Listing 11.1 web-grep.cgi: UNIX Shell Script Using grep
#! /bin/sh echo Content-type: text/html echo if [ $# = 0 ] then echo "<HTML>" echo "<HEAD>" echo "<TITLE>Search the News Page</TITLE>" echo "</HEAD>" echo "<BODY background=\"http://www.aa.net/~rclark/ivory.gif\">" echo "<b><a href=\"http://www.aa.net/~rclark/\">Home</a></b><br>" echo "<b><a href=\"http://www.aa.net/~rclark/news.html\">News Page</a></b><br>" echo "<b><a href=\"http://www.aa.net/~rclark/search.html\">Search the Web</a></b><br>" echo "<hr>" echo "<H2>Search the News Page</H2>" echo "<ISINDEX>" echo "<p>" echo "<dl><dt><dd>" echo "The search program looks for the exact phrase you echo "<p>" echo "You can search for <b>a phrase</b>, a whole <b>word</b> or <b>sub</b>string.<br>" echo "UPPER and lower case are equivalent.<br>" echo "<p>" echo "This program searches only the news listings page itself.<BR>" echo "Matches may be in publication names, URLs or section headings.<br>" echo "<p>" echo "To search the Web in general, use <b>Search the Web</b> in the menu above.<br>" echo "<p>" echo "</dd></dl>" echo "<hr>" echo "</BODY>" echo "</HTML>" else echo "<HTML>" echo "<HEAD>" echo "<TITLE>Result of Search for \"$*\".</TITLE>" echo "</HEAD>" echo "<BODY background=\"http://www.aa.net/~rclark/ivory.gif\">" echo "<b><a href=\"http://www.aa.net/~rclark/\">Home</a></b><br>" echo "<hr>" echo "<H2> Search Results: $*</H2>" grep -i "$*" /home/rclark/public_html/news.html echo "<p>" echo "<hr>" echo "<b><a href=\"http://www.aa.net/cgi-bin/rclark/ isindex.cgi\">Return to Searching the News Page</a></b><br>" echo "</BODY>" echo "</HTML>" fi
web-grep is a UNIX shell script that uses the UNIX grep utility. A script like this, or a version of it in Perl or C or any another language, is a handy tool if you have Web pages with long lists of links in them.
This script uses the <ISINDEX> tag, because some browsers still don't support forms. Using an <ISINDEX> interface instead of a forms interface lets users whose browsers lack forms capability conduct this particular search.
You can edit the script to include your own menu at the top of
the page and your own return link to the page that the script
searches. If the script doesn't produce the expected results after
you edit it, you can find some debugging help in Chapter 25, "Testing
and Debugging CGI Scripts."
| Troubleshooting |
When I edit and run this script, I get the message Document contains no data. Look for syntax errors in the parts you edited. Missing double quotation marks at the ends of the lines can cause this. |
Most people with Web sites are customers of commercial Internet providers. Most of those providers, especially the big ones, run UNIX. The following sections discuss some simple search tools for personal and small business sites hosted at commercial service providers.
Business users who have their own Web servers and need more powerful search tools can skip to the section "An Overview of Search Engines for Business Sites." The following sections discuss the ICE, SWISH, Hukilau 2, and GLIMPSE search engines.
Christian Neuss' ICE search engine is the easiest to install of the programs mentioned here. ICE produces relevance ranked results, and it lists how many search keywords it finds in each file. It's written in Perl.
There are two scripts. The indexing script, ice-idx.pl, creates an index file that ICE can later search. The indexing script runs from the UNIX shell prompt. It builds a plain ASCII index file, unlike the binary index files that most other search engines use.
The search script, ice-form.pl, is a CGI script that searches the index built by ice-idx.pl and displays the results on a Web page.
The user input form for an ICE search includes a check box for an optional external thesaurus (see fig. 11.6). Christian Neuss notes that ICE has worked well with small thesauri of a few hundred technical terms, but that anyone who wants to use a large thesaurus should contact him for more information.
You can find the current version of ICE on the Net at the following two distribution sites:
http://www.informatik.th-darmstadt.de/~neuss/ice/ice.html
http://ice.cornell-iowa.edu/
ICE searches the directories that you specify in the script's configuration section. When ICE indexes a given directory, it also indexes all its subdirectories (see fig. 11.7).
Five configuration items are at the top of the indexer script. You'll need to edit three of them, as shown in the following code.
@SEARCHDIRS=( "/home/user/somedir/subdir/", "/home/user/thisis/another/", "/home/user/andyet/more_stuff/" ); $INDEXFILE="/user/home/somedir/index.idx"; # Minimum length of word to be indexed $MINLEN=3;
The first directory path in @SEARCHDIRS is the default
that will appear on the search form. You can add more directory
lines in the style of the existing ones; or you can include only
one directory, if you want to limit what others can see of your
files.
| NOTE |
Remember that ICE automatically indexes and searches all the subdirectories of the directories you specify. You might want to move test, backup, and non-public files to a directory that ICE doesn't search. |
After you set the configuration variables, run the script from the command line to create the index. Whenever you want to update the index, run the ice-idx.pl script again. It will overwrite the existing index with the new one.
The search form presents a choice of directories in a drop-down selection box (see listing 11.2). You can specify these directories in the script.
Listing 11.2 ICE Configuration Variables
# Title or name of your server:
Now you can install the script in your cgi-bin directory and call it from your Web browser. ICE's search results page lists the keywords it finds in each file (refer to fig. 11.7).
SWISH is easy to set up and offers fast, reliable searching for Web sites. Kevin Hughes wrote the program in C. It's available from EIT, at
http://www.eit.com/goodies/software/swish/swish.html
You can download SWISH's source code from EIT's FTP site, at the following URL, and compile it on your own UNIX system.
ftp.eit.com/pub/web.software/swish/
Installing SWISH is straightforward. After you decompress and untar the source files, edit the src/config.h file and compile SWISH for your system.
To link SWISH to the Web, you can use the WWWWAIS gateway (see fig. 11.8), also available from EIT:
http://www.eit.com/software/wwwwais/
Another way to link the SWISH search engine to the Web is with Swish-Web, a gateway written in Perl that's included on the CD. Unlike WWWWAIS, Swish-Web's user input form (see fig. 11.9) and its search results page (see fig. 11.10) are separate. You can change the defaults for all the options on the user input form without editing the CGI script. Several different user input forms, each tailored to search a different set of indexes and to use different search options, can call the same script.
Figure 11.10 : This is the SWISH search engine's output, as seen through the Swish-Web gateway.
You can control the entire indexing process with configuration options in the swish.conf file. Listing 11.3 shows a working example of a swish.conf file. You can compare it with the sample included in the SWISH file distribution.
Listing 11.3 swishcon.txt: SWISH Configuration Variables
# SWISH configuration file IndexDir /home/rclark/public_html/ # This is a space-separated list of files and directories you # want indexed. You can specify more than one of these directives. IndexFile index.swish # This is what the generated index file will be. IndexName "Index of Small Hours files" IndexDescription "General index of the Small Hours web site" IndexPointer "http://www.aa.net/~rclark/" IndexAdmin "Rod Clark (rclark@aa.net)" # Extra information you can include in the index file. IndexOnly .html .txt .gif .xbm .jpg # Only files with these suffixes will be indexed. IndexReport 3 # This is how detailed you want reporting. You can specify numbers # 0 to 3 - 0 is totally silent, 3 is the most verbose. FollowSymLinks yes # Put "yes" to follow symbolic links in indexing, else "no". NoContents .gif .xbm .jpg # Files with these suffixes will not have their contents indexed - # only their file names will be indexed. ReplaceRules replace "/home/rclark/public_html/" "http://www.aa.net/~rclark/" # ReplaceRules allow you to make changes to file pathnames # before they're indexed. FileRules pathname contains test newsmap FileRules filename is index.html rename chk lst bit FileRules filename contains ~ .bak .orig .000 .001 .old old. .map .cgi .bit .test test log- .log FileRules title contains test Test FileRules directory contains .htaccess # Files matching the above criteria will *not* be indexed. IgnoreLimit 80 50 # This automatically omits words that appear too often in the files # (these words are called stopwords). Specify a whole percentage # and a number, such as "80 256". This omits words that occur in # over 80% of the files and appear in over 256 files. Comment out # to turn of auto-stopwording. IgnoreWords SwishDefault # The IgnoreWords option allows you to specify words to ignore. # Comment out for no stopwords; the word "SwishDefault" will # include a list of default stopwords. Words should be separated # by spaces and may span multiple directives.
| NOTE |
If you plan to use Swish-Web, be sure to set ReplaceRules in swish.conf to change the system file paths to URLs in SWISH's output. Unlike WWWWAIS, Swish-Web doesn't duplicate this SWISH option. |
Now, to create an index, at the shell prompt type
% swish -c swish.conf
After you create an index, you can search it and look at the results on the command line. To search a SWISH index from a Web browser, you'll need a separate Web gateway. SWISH, unlike some others, doesn't include a direct link to the Web.
The Web gateway lets a Web user send commands to and receive output from the program from a remote computer (the Web browser) rather than from the server's console. Because anyone in the world can run the program remotely from the Web gateway, the gateway typically implements only a limited, safe subset of the program's commands. The Swish-Web gateway, for example, doesn't allow users to create new indexes from its Web page.
Swish-Web includes two sample forms: a simple form that runs a search on a single index, and a more detailed form that lets the user choose among multiple indexes and set a variety of search options.
First, edit the sample forms to include your home page URL, your e-mail address, and the URL where you'll put swish-web.cgi. Then edit the script's user configuration section (see listing 11.4). The script includes detailed explanations of all these variables.
Listing 11.4 Swish-Web Configuration Variables
$SwishLocation = "/home/rclark/public_html/swish"; $DefaultIndexLocation = "/home/rclark/public_html/index.swish"; @MultiIndexLocation = ( "/home/rclark/public_html/index.swish", "/home/rclark/public_html/index2.swish" ); $ShowIndexFilenames = 0; $ShowSwishVersion = 0; $PrintBoldLinks = 1; $GoofyKeyword = "oQiTb2lkCv"; $SimpleFormURL = "http://www.aa.net/~rclark/ swish-simple.html"; $SimpleFormPrompt = "Simple Search Form"; $DetailedFormURL = "http://www.aa.net/~rclark/ swish-web.html"; $DetailedFormPrompt = "Detailed Search Form"; $HomePageURL = "http://www.aa.net/~rclark/"; $HomePagePrompt = "Home Page"; $MailtoAddress = "rclark@aa.net"; $MailtoPrompt = "E-mail: "; $MailtoName = "Rod Clark";
After you edit the appropriate settings, install the swish-web.cgi script in the usual way for your system. Then you can search the SWISH index with your Web browser (refer to fig. 11.10).
The complete Perl source code for the Swish-Web gateway is on the CD, and is in the public domain. (Thanks go to Tim Hewitt, whose code is at the core of the script.)
Swish-Web is an example of a Web gateway for a UNIX command-line program. If you'd like to practice a little programming on it, here are a few ideas for additions to the script.
SWISH provides relevance ranking, but the ranking algorithm seems to favor small files with little text, among which keywords loom large. Because SWISH reports file sizes, it would be possible to add a routine to Swish-Web to sort SWISH's output by file size.
Another useful addition would be a second relevance ranking option that weights file size more heavily. A selection box on the form to limit the results to the first 10, 25, 50, 100, or 250 (or all) results might be another useful addition.
The routines shown in listing 11.5 display some information on-screen about the SWISH index file that's being read.
Listing 11.5 Sample Code from swish-web.cgi
#------------------------------------------------------------------
# PRINT INDEX DATA
sub PrintIndexData {
# If entry field is blank, index isn't searched, hence no index
#data.
# In that case, search the index to retrieve indexing data.
if (!$Keywords) {
&SearchFileForIndexData;
}
print "<hr>";
print "<dl><dt><dd>";
print "Index name: <b>$iname</b><br>\n";
print "Description: <b>$idesc</b><br>\n";
print "Index contains: <b>$icounts</b><br>\n";
if ($ShowIndexFilenames) {
print "Location: <b>$IndexLocation</b><br>\n";
print "Saved as (internal name): <b>$ifilename</b><br>\n";
}
print "SWISH Format: <b>$iformat</b><br>\n";
print "Maintained by: <b>$imaintby</b><br>\n";
print "Indexed on: (day/month/year): <b>$idate</b><br>\n";
if ($ShowSwishVersion) {
if (open (SWISHOUT, "-|") || exec $SwishLocation, "-V") {
$SwishVersion = <SWISHOUT>;
close (SWISHOUT);
}
print "Searched with: <b>$SwishVersion</b><br>\n";
}
print "</dd></dl>";
}
#----------------------------------------------------------------
# SEARCH FILE FOR INDEX DATA
# If the form's input field is blank, ordinarily no search is made,
# which prevents reading the index file for the index data. In that
# case, the following subroutine is called.
sub SearchFileForIndexData {
# use a keyword that definitely won't be found
$Keywords = $GoofyKeyword;
if (open (SWISHOUT, "-|")
|| exec $SwishLocation, "-f", $IndexLocation, "-w", $Keywords) {
while ($LINE=<SWISHOUT>) {
chop ($LINE);
&ScanLineForIndexData;
}
close (SWISHOUT);
}
}
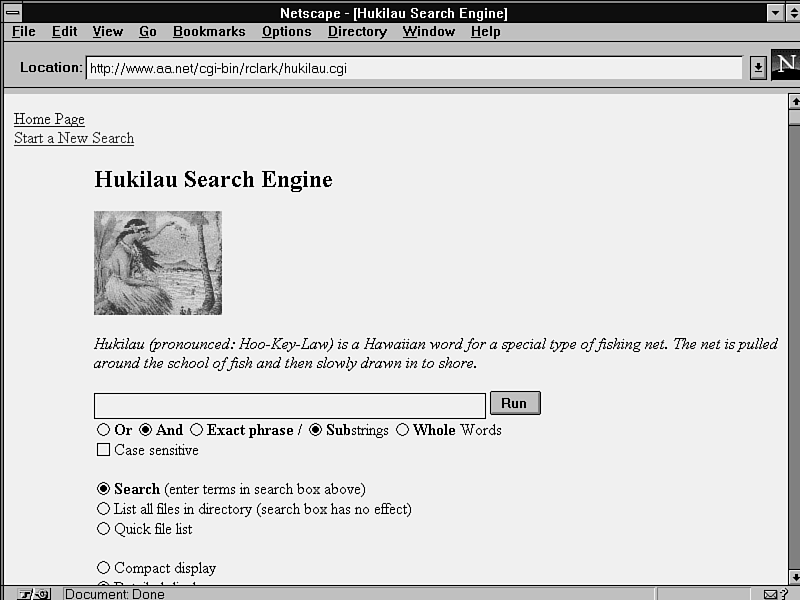
The Hukilau search script searches through all the files in a directory (see fig. 11.11). This can be very slow, so it's not practical for every site. Hukilau is slow because it doesn't use a stored index, but instead searches live files in the specified directory. By doing this, it always returns current results.
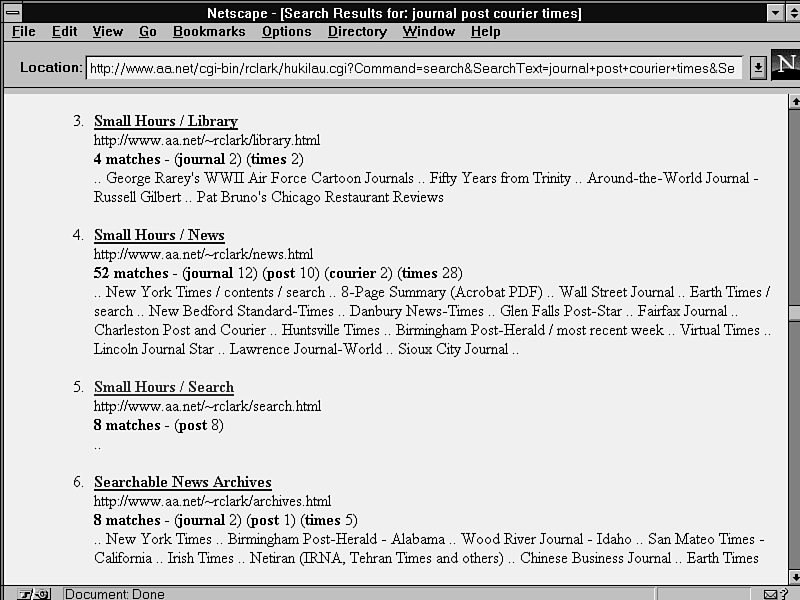
Hukilau searches only one directory, which you specify in the script. (The registered version lets you choose other directories from the search form.) Its search results page includes file names and context abstracts (see fig. 11.12). The files on the search results page aren't ranked by relevance, but instead appear in directory order.
The results include matches found in visible page titles and in URLs. This can be helpful. But in the search.html file, the script also found eight instances of the word post as used in HTML forms. This isn't as helpful to most users.
There's also an option to show text abstracts from all the files in a directory, sorted alphabetically by file name. This is useful when you're looking for something that you can't define well with a few keywords, or when you need a broad overview of what's in the directory.
A quick file list feature lists all the files in the directory alphabetically by file name. It's fast, but it shows only file names, not page titles or context abstracts.
The Hukilau 2 search form uses radio buttons and check boxes to set the search options. This makes it easy to use. But unlike SWISH, Hukilau doesn't allow you to group some of the query words together with parentheses so that certain operators affect only the words inside the parentheses and not the rest of the query words.
Listing 11.6 shows the section of hukilau.cgi that contains the configuration variables. The script includes more detailed explanations of all of these. After you edit these settings, install the script in the usual way for your system. The script is self-contained and prints its own form.
Listing 11.6 Hukilau Configuration Variables
$FileEnding = ".html"; $DirectoryPath = "/home/rclark/public_html/"; $DirectoryURL = "http://www.aa.net/~rclark/"; $HukilauCGI = "http://www.aa.net/cgi-bin/rclark/hukilau.cgi"; $HukilauImage = "http://www.aa.net/~rclark/hukilau.gif"; $BackgroundImage = "http://www.aa.net/~rclark/ivory.gif"; $Copyright = "Copyright 1995 Adams Communications. All rights reserved."; $HomePageURL = "http://www.aa.net/~rclark/"; $HomePageName = "Home Page"; # You must place the "\" before the "@" sign in the e-mail address: $MailAddress = "rclark\@aa.net";
The defaults are to AND all the words together, to search for substrings rather than whole words, and to conduct a case-insensitive search. If you'd like to change these defaults, you can edit the search form that the script generates. Listing 11.7 shows the part of the search form that applies to the radio button and check box settings, edited a bit here for clarity.
Listing 11.7 Hukilau Radio Buttons and Check Boxes
sub PrintBlankSearchForm
{
...
<INPUT TYPE="RADIO" NAME="SearchMethod" value="or"><b>Or</b>
<INPUT TYPE="RADIO" NAME="SearchMethod" value="and" CHECKED><b>And
</b>
<INPUT TYPE="RADIO" NAME="SearchMethod" value="exact phrase"><b>Exact phrase</b> /
<INPUT TYPE="RADIO" NAME="WholeWords" value="no" CHECKED><b>Sub
</b>strings
<INPUT TYPE="RADIO" NAME="WholeWords" value="yes"><b>Whole</b> Words<br>
<INPUT TYPE="CHECKBOX" NAME="CaseSensitive" value="yes">Case sensitive<BR>
<INPUT TYPE="RADIO" NAME="ListAllFiles" value="no" CHECKED><b>Search</b>
(enter terms in search box above) <br>
<INPUT TYPE="RADIO" NAME="ListAllFiles" value="yes">List all files in directory
(search box has no effect)<br>
<INPUT TYPE="RADIO" NAME="ListAllFiles" value="quick">Quick file list<br>
<INPUT TYPE="RADIO" NAME="Compact" value="yes">Compact display<br>
<INPUT TYPE="RADIO" NAME="Compact" value="no" CHECKED>Detailed display<br>
<INPUT TYPE="CHECKBOX" NAME="ShowURL" value="yes">URLs<br>
<INPUT TYPE="CHECKBOX" NAME="ShowScore" value="yes" CHECKED>Scores<br>
<INPUT TYPE="CHECKBOX" NAME="ShowSampleText" value="yes" CHECKED>Sample text<br>
...
For example, to change the default from AND to OR, move the word CHECKED from the "and" to the "or" radio button, on these two lines:
<INPUT TYPE="RADIO" NAME="SearchMethod" value="or"><b>Or</b> <INPUT TYPE="RADIO" NAME="SearchMethod" value="and" CHECKED><b>And</b>
The result should look like this:
<INPUT TYPE="RADIO" NAME="SearchMethod" value="or" CHECKED><b>Or </b> <INPUT TYPE="RADIO" NAME="SearchMethod" value="and"><b>And</b>
Changing the value of a check box is a little different. For example, to make searching case-sensitive by default, add the word CHECKED to the statement that creates the check box. The original line is as follows:
<INPUT TYPE="CHECKBOX" NAME="CaseSensitive" value="yes">Case sensitive<BR>
The following is the same line, but set to display a checked box:
<INPUT TYPE="CHECKBOX" NAME="CaseSensitive" value="yes" CHECKED>Case sensitive<BR>
An unchecked box sends no value to the CGI program. It doesn't matter if you change yes to no, or for that matter to blue elephants, as long as the box remains unchecked. Only if the box is checked does the quoted value ever get passed to the program. In other words, an unchecked box is as good as a box that's not on the form at all, as far as the cgi program is concerned.
This is what's behind the choice of values for the defaults. If you remove all the radio button and check box fields from the form, the program sets a range of reasonable, often used defaults.
This makes it practical to use simple hidden Hukilau forms as drop-in search forms on your pages, as mentioned earlier in the chapter. To change the defaults and still use a hidden form, you can include the appropriate extra fields but hide them. Listing 11.8 is an example that includes a hidden field that forces a search for whole words instead of substrings.
Listing 11.8 hukiword.txt: Drop-in Hukilau Search Form (Whole Words)
<FORM METHOD="POST" ACTION="http://www.substitute_your.com/cgi-bin/hukilau.cgi"> <INPUT TYPE="HIDDEN" NAME="Command" VALUE="search"> <INPUT TYPE="TEXT" NAME="SearchText" SIZE="48"> <INPUT TYPE="SUBMIT" VALUE=" Search "><br> <INPUT TYPE="HIDDEN" NAME="SearchMethod" value="and"> <INPUT TYPE="HIDDEN" NAME="WholeWords" value="yes"> <INPUT TYPE="HIDDEN" NAME="ShowURL" value="yes"> </FORM>
The current version of the Hukilau Search Engine is available from Adams Communications, at http://www.adams1.com/pub/russadam/. Updates about possible new features that may be in testing can be found at the Small Hours site at http://www.aa.net/~rclark/scripts/.
The complete Perl source code for the Hukilau Search Engine is included on the CD. Russ Adams, the program's author, has kindly let me include my experimental Hukilau 2 version of the script, which adds some extra routines that were written as examples for this chapter.
The sample code shown in listing 11.9 is from some new routines I've added to Hukilau 2. These routines are from the part of the script that alphabetically lists all the files in the directory. Shown here is a routine that displays a text abstract from each file, and another that gives a quick directory list of file names.
Listing 11.9 Sample Code from hukilau.cgi
#----------------------------------------------------------------
# List Files
sub ListFiles {
opendir (HTMLDir, $DirectoryPath);
@FileList = grep (/$FileEnding$/, readdir (HTMLDir));
closedir (HTMLDir);
@FileList = sort (@FileList);
$LinesPrinted = 0;
foreach $FileName (@FileList) {
$FilePath = $DirectoryPath.$FileName;
$FileURL = $DirectoryURL.$FileName;
if ($ListAllFiles eq "quick") {
print "<li><b><a href=\"$FileURL\">$FileName</a></b><br>\n";
$LinesPrinted ++;
}
else {
if ($Compact eq "no") {
&ListDetailedFileInfo;
}
else {
&ListQuickFileInfo;
}
}
}
}
#----------------------------------------------------------------
# List Detailed File Info
sub ListDetailedFileInfo {
print "<li><b><a href=\"$FileURL\">$FileName</a>";
if (($ShowSampleText eq "yes") || ($Title ne $FileName)) {
&FindTitle;
print " - $Title";
}
print "</b><br>\n";
$LinesPrinted ++;
if ($ShowURL eq "yes") {
print "$FileURL<br>\n";
$LinesPrinted ++;
}
if ($ShowSampleText eq "yes") {
&BuildSampleForList;
$SampleText = substr ($SampleText, 0, $LongSampleLength);
print "$SampleText<br>\n";
print "<p>\n";
# this is an approximation, as sample lines will vary
$LinesPrinted = $LinesPrinted + $AvgLongSampleLines + 1;
}
}
#----------------------------------------------------------------
# List Quick File Info
sub ListQuickFileInfo {
print "<li><b><a href=\"$FileURL\">$FileName</a>";
if ($ShowSampleText eq "no") {
print "</b><br>\n";
$LinesPrinted ++;
}
else {
if ($Title ne $FileName) {
&FindTitle;
print " - $Title";
}
print "</b><br>\n";
$LinesPrinted ++;
&BuildSampleForList;
$SampleText = substr ($SampleText, 0, $ShortSampleLength);
print "$SampleText<br>\n";
print "<p>\n";
$LinesPrinted = LinesPrinted + AvgShortSampleLines + 1;
}
}
#----------------------------------------------------------------
# Find Title
sub FindTitle {
# find the file's <TITLE>, if it has one
# if not, put $FileName in $Title
open (FILE, "$FilePath");
# look for a <TITLE> tag
$HaveTitle = 0;
$ConcatLine = "";
foreach $IndivLine (<FILE>) {
$ConcatLine = $ConcatLine.$IndivLine;
if ($IndivLine =~ /<TITLE>/i) {
$HaveTitle = 1;
}
last if ($IndivLine =~ m#</TITLE>#i);
# last aborts loop when it finds </TITLE>
# use # instead of / as delimiter, because / is in string
# trailing i is for case insensitive match
}
close (FILE);
# if file has no <TITLE>, use filename instead
if (!$HaveTitle) {
$Title = $FileName;
}
# otherwise use string from <TITLE> tag
else {
# replace linefeeds with spaces
$ConcatLine =~ s/\n/ /g;
# collapse any extended whitespace to single spaces
$ConcatLine =~ s/\t / /g;
# replace possibly mixed-case <TiTle></tItLe> with fixed string
$ConcatLine =~ s#</[tT][iI][tT][lL][eE]>#<XX>#;
$ConcatLine =~ s#<[tT][iI][tT][lL][eE]>#<XX>#;
# concatenated line is now "junk XXPage TitleXX junk"
@TempLines = split (/<XX>/, $ConcatLine);
# part [0] is junk, part [1] is page title, part [2] is junk
$TempTitle = $TempLines[1];
# trim leading spaces
$TempTitle =~ s/^ +//;
# trim trailing spaces
$TempTitle =~ s/ +$//;
if ($TempTitle eq "") {
$Title = $FileName;
}
else {
$Title = $TempTitle;
}
undef @TempLines; # dispense with array, free a little memory
}
}
#----------------------------------------------------------------
# Build Sample for List
sub BuildSampleForList {
$SampleText = "";
open (FILE, "$FilePath");
foreach $Record (<FILE>) {
&BuildSampleText;
}
close (FILE);
}
#----------------------------------------------------------------
# Build Sample Text
sub BuildSampleText {
# remove linefeed at end of line
chop ($Record);
# collapse any extended whitespace to single space
$Record =~ s/\t / /g;
# remove separator at end of existing sample text, if one exists
$SampleText =~ s/$SampleSeparator$//;
# add sample from current line, separate former lines visually
$SampleText = $SampleText.$SampleSeparator.$Record;
# remove everything inside <tags> in sample
$SampleText =~ s/<[^>]*>//g;
}
Because Hukilau is written in Perl, it's easy to install and modify.
Perl is an appropriate language to use to write text-searching
tools because it includes a good set of text pattern matching
capabilities.
| Troubleshooting |
I made some changes in the script, and now it gives a server error when I bring up its URL on my Web browser. You can test your editing changes for syntax errors before installing the script in your cgi-bin directory. Give the script execute permission for your account, and then type its file name at the UNIX shell prompt. The output will be either the default search form (if the syntax is correct) or a Perl syntax error message that gives you the line number and probable reason for the error. How do I know the HTML that my script generates is correct when I'm editing the script, without installing it in cgi-bin first? From the UNIX shell prompt, you can run the script and capture its HTML output (for the default form) by redirecting the screen output to a file. Then you can run an HTML validation tool such as htmlchek on the file. To capture the script's on-the-fly output to a file, use the standard UNIX redirection character > to create the output file: % hukilau.cgi >htest.html The captured file contains exactly what the CGI script sends to a Web browser. The MIME header (Content type: text/html) that the CGI script sends before the HTML page is visible here as plain text at the top of the file. (The browser intercepts this and doesn't show it as visible text.) You can either delete the MIME header before running a validation tool on the captured file, or simply ignore the characteristic message that it produces at the beginning of the validation report. In the following example, the file check.out contains the validation report for the HTML page captured from the script: % htmlchek.pl htest.html >check.out |
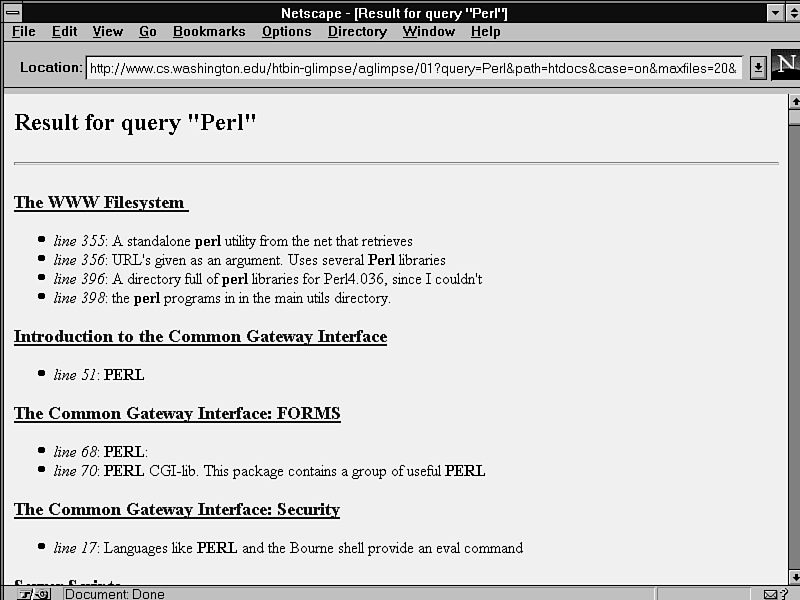
GLIMPSE isn't simple, and to include it in this section isn't quite right. But it's not a commercial product either. It's a project of the University of Arizona's Computer Science Department (see fig. 11.13).
| NOTE |
You can install GLIMPSE on a personal UNIX account, but it helps to have a couple of spare megabytes of file space available during installation. |
As the name GLIMPSE implies, the program displays context abstracts from the files. GLIMPSE presents abstracts from the actual text surrounding the matches, rather than display a fixed abstract of the file's contents. This makes it a particularly useful tool for some purposes, although it doesn't offer relevance ranking (see fig. 11.14).
GLIMPSE can build indexes of several sizes-from tiny (about 1 percent of the size of the source files) to large (up to 30 percent of the size of the source files). Even relatively small GLIMPSE indexes are practical and offer good performance.
GLIMPSE isn't particularly easy to install, unless you have fairly extensive experience with UNIX. It's more for UNIX administrators than for general users. The installation process can't be condensed well into a few paragraphs here, so you'll have to read the documentation, which isn't altogether friendly to beginners.
GLIMPSE's companion Web gateway is called Glimpse-HTTP. Current information is available from the GLIMPSE and Glimpse-HTTP home pages at the following URLs:
http://glimpse.cs.arizona.edu/
http://glimpse.cs.arizona.edu/ghttp/
Some small business sites are happy with a simple, quick tool like ICE or SWISH. Others, who want to offer more search capabilities to their users, might install a commercial search engine.
Some Web servers include their own built-in indexing and searching programs. These vary quite a bit in what they can do. I'll briefly mention a few of them, after a quick overview of some of the newer commercial search engines available.
Several of the big commercial search engines support large collections of files and indexes in distributed locations. With some of them, the program that builds the indexes, the query engine, and the actual indexes can all be on separate machines. Web crawlers can go out and bring back updated data from outside sources, and incremental indexing allows continuous automatic updating of the indexes.
With these search engines, it's possible to search indexes at multiple locations simultaneously and return the results to the user as a single seamless file.
Another advantage of some of the more complex, specialized search engines is that they can index many different file types in their native file formats. If your search engine can filter these files on the fly to create HTML output, you don't have to translate any of your original files in those formats into static HTML pages. That way, you can maintain only one set of files in the original formats. This is a considerable advantage.
There are a number of such commercial products. The following sections describe only a small sampling of the many good tools available.
Verity's Topic Server is a popular and expensive choice for complex business sites. It's available for Windows NT running on Intel platforms, and for SunOS, Solaris, HP-UX, and AIX.
Topic Server can index word processor, Adobe PDF, spreadsheet, CAD, database, and many other file types. It filters and presents these as HTML documents, or as graphics in a format viewable on a user's Web browser.
For all this to work, specific indexing and filtering modules for each native file format must first be available for Topic Server. There is a long and growing list of supported file formats. Programmers are working feverishly to create more, even as we speak.
Verity is located at http://www.verity.com/. You can see a working example of Verity's Topic Server at the U.S. News and World Report site at http://vws.agtnet.com/usn_find.html.
Architext's popular new search engine is available for SunOS, Solaris, HP-UX, SGI Irix, AIX, and BSDI UNIX. The company says that a Windows NT version may be released in the foreseeable future.
Excite lets users enter queries in ordinary language without using specialized query syntax. Users can choose either a concept-based search or a conventional keyword AND search. The results page presents relevance-ranked links with context abstracts. The software includes a query-by-example feature so that users viewing a page can click a hypertext link to start a new search for similar pages.
Excite doesn't need a thesaurus to do concept-based searching, but the company says that an external thesaurus can improve its results. Because thesauri aren't necessary, adding support for new languages supposedly isn't as difficult as with some other software. Architext claims that independent software developers can write modules to support additional data file formats, too, without facing too many obstacles.
Excite's index files take up only about 15 percent of the disk space occupied by the original documents that it indexes. This is much less space than some other search engines' indexes require.
Architext now offers the software at no charge and sells annual support contracts. Further information about Excite for Web servers can be found at http://www.excite.com/navigate/.
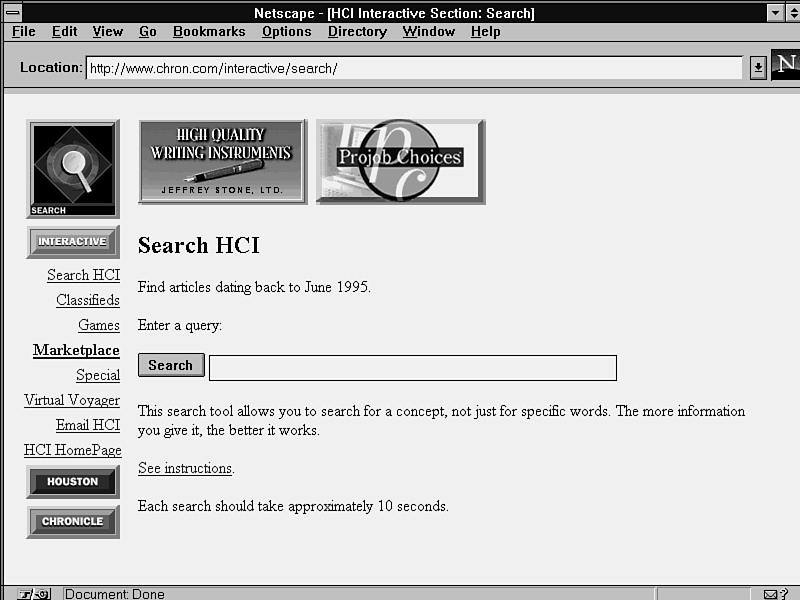
Quite a few sites are running the Excite search engine. One nicely done example is the Houston Chronicle search page (see fig. 11.15) at http://www.chron.com/interactive/search/.
LiveLink Search is a smaller search engine derived from OpenText's huge engine that indexes the entire Web. It includes many of the same capabilities.
It's part of a group of OpenText applications that are intended particularly for use over intranets (Web documents distributed over a LAN). An intranet is an alternative to other document-distribution systems such as Lotus Notes. LiveLink Search can also be used on the Web, and offers an optional continuous crawler to keep its indexes up-to-date.
The software includes bundled copies of Netscape's Commerce and Communications servers. It's available for Windows NT, SunOS, Solaris, HP-UX, AIX, SGI, and OSF/1. You can find out more about it at http://www.opentext.com/corp/otm_prod_search.html.
PLS' PLWeb search engine supports only HTML, ASCII, and (on some platforms) Adobe PDF documents. It automatically generates its own thesaurus from the documents it processes. PLWeb uses the thesaurus, along with stemming and fuzzy searching, to allow users some guesswork in their query wording. Users can also browse through the keywords in the index.
PLWeb updates its indexes online while the search engine is running. It's available for Solaris, HP-UX, AIX, SGI IRIX, and OSF/1. Further information is available at http://www.pls.com/. You can view a site using PLWeb at http://www.dialog.com/dialog/search.html.
Several Web servers for UNIX and Windows NT include built-in utilities to index and search the files at a site. Some of these tools have fewer capabilities than the search engines mentioned earlier.
Process Software's Purveyor Web server includes Verity's Topic Server search engine, or some core parts of it. Process notes that add-on modules are available for the Verity search tools that it bundles with its server. More information about Purveyor and its included version of Topic Server is available at http://www.process.com/.
Navisoft's Naviserver runs on Windows NT and UNIX. It includes Illustra's Text DataBlade search tool, which is an add-on module for Illustra's object database system. Text DataBlade's capabilities include both keyword and concept-based searching.
Current information about Naviserver is available at http://www.navisoft.com/. A search page at Illustra itself (see fig. 11.16) is at http://www.illustra.com/cgi-bin/Webdriver.
Open Market's two Web servers (one of them is a secure server) run on SunOS, Solaris, HP-UX, AIX, and SGI UNIX. Both servers are available with Personal Library Software's PLWeb Intro search engine, Architext's Excite search engine, or the Open Text Index engine. More information is available at http://www.openmarket.com/. Open Market's own search service is at http://www.directory.net/.
SPRY's SafetyWeb secure server for Windows NT supports publishing Web documents both on the Web and on intranets. SafetyWeb includes the Architext Excite search engine. SPRY offers further information at http://server.spry.com/.
O'Reilly's WebSite server for Windows NT includes built-in WebIndex indexing and WebFind searching tools. WebFind runs as a CGI program and is a conventional search tool. It's much simpler than the other search engines mentioned earlier. WebFind does keyword searches and supports AND and OR operators. Its search results page lists page titles.
You can find more information about the WebSite server in Chapter 21, "Tips and Techniques for Visual Basic." O'Reilly's own site is at http://www.ora.com/. A site that runs WebSite and uses the WebFind search utility to offer a search box on its home page is at http://www.gmpvt.com/.
To find more information about the current crop of Web servers and their capabilities, including built-in indexing and searching utilities, you can look at the Web Servers Comparison page. This is a useful site with a good deal of additional documentation. You'll find this site at http://www.webcompare.com/.