{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



by Bill Anderson
Today, the Internet and intranets are exploding like wildfire. The article, "VISA Moves to Intranet System," in the January 29, 1996, issue of Information Week states that "two thirds of all large companies either have an internal Web server installed or are thinking about it, and industry analysts believe that soon internal Web servers will outnumber external servers by a margin of 10 to 1. Forrester Research predicts the intranet server business will hit $1 billion by the year 2000." The daily announcements about new venture agreements, new application products, and new technology validate this prediction. In the nearly 30 years that I have worked in the computer industry, I cannot remember such an explosive period.
With all the excitement, one tends to forget that individuals laid the foundation for today's events in the late 1960s. The next three sections of this chapter look at the history, future, and fundamentals of the Internet, networks, and intranets. Then we devote four sections to the basics of TCP/IP networking. The chapter ends with a brief discussion of various applications, plug-ins, and applets.
Most historical reviews of the Internet imply that networking
began with ARPAnet. In a sense, digital transmission of data began
when Samuel B. Morse publicly demonstrated the telegraph in 1844.
In 1874, Thomas Edison invented the idea of multiplexing two signals
in each direction over a single wire. With higher speeds and multiplexing,
Edison's teletype replaced Morse's manual system; and a few teletype
installations still exist today.
| NOTE |
In 1837 both Sir Charles Wheatstone in Great Britain and Samuel B. Morse in the United States announced their telegraphic inventions. |
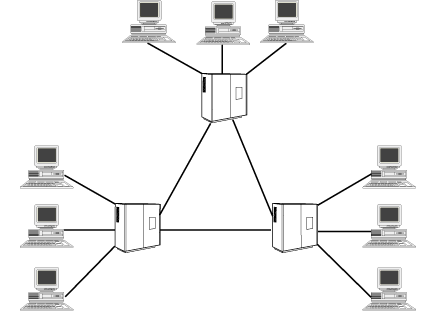
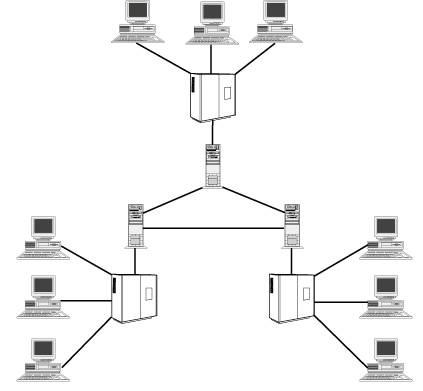
The early telegraph systems were, in modern terms, point-to-point links. As the industry grew, switching centers acted as relay stations and paper tape was the medium that the human routers used to relay information from one link to another. Figure 1.1 illustrates a simple single-layer telegraphic network configuration. Figure 1.2 shows a more complex multilayered network.
Figure 1.1 : A simple asynchronous network.
Figure 1.2 : A multilayered asynchronous network.
The links of these networks were point-to-point asynchronous serial connections. For a paper tape network, the incoming information was punched on paper tape by high-speed paper tape punches and was then manually loaded on an outgoing paper tape reader.
Although this activity might seem like ancient history to younger readers, let us put this story into a more understandable framework. In early 1962, I built my first "computer"-a vacuum tube calculator-and spent the following summer reading the latest book on designing transistorized computers. At the same time, Paul Baran and his colleagues at the Rand Corporation were tackling the problem of how to build a computer network that would survive a nuclear war. Yet when I joined the United States Air Force in 1968, I became an Automatic Digital Network (AUTODIN) programmer. At that time, the network was only a few years old. In essence, AUTODIN replaced the human routers with computers without changing the network model of the paper tape network.
The year 1969 was a year of milestones. Not only did NASA place the first astronauts on the moon but also, and with much less fanfare, Department of Defense's Advanced Research Projects Agency (ARPA) contracted with Bolt, Baranek, and Newman (BBN) to develop a packet-switched network based on Paul Baran's ideas. The initial project linked computers at the University of California at Los Angeles (UCLA), Stanford Research Institute (SRI) in Menlo Park, California, and University of Utah in Salt Lake City, Nevada. The birth of ARPA is permanently engraved in my mind, because, as a young second lieutenant, I presented a briefing on the future of the ARPAnet to a group of colonels and generals. Looking back, my briefing was definitely short on vision. On the other side of the continent from the ARPAnet action, Brian W. Kernighan and Dennis M. Ritchie brought UNIX to life at Bell Labs (now Lucent Technologies) in Murray Hills, New Jersey.
Even though message switching was well known, the original ARPAnet provided only three services: remote login (telnet), file transfer, and remote printing. In 1972, when ARPAnet consisted of 37 sites, e-mail joined the ranks of ARPAnet services. In October 1972 ARPAnet was demonstrated to the public at the International Conference on Computer Communications in Washington, D.C. In the following year, TCP/IP was proposed as a standard for ARPAnet.
The amount of military-related traffic continued to increase on ARPAnet. In 1975 the Defense Communications Agency (DCA) changed its name to DARPA (Defense Advanced Research Projects Agency) and took control of ARPAnet. Many non-government organizations wanted to connect to ARPAnet, but DARPA limited private sector connections to defense-related organizations. This policy led to the formation of other networks such as BBN's commercial network Telenet.
The year 1975 marked the beginning of the personal computer industry's rapid growth. In February 1975, about seven months after Altair announced its microcomputer, I purchased an IMSAI 8080 (serial number 25). In those days when you bought a microcomputer, you received bags of parts that you then assembled. Assembling a computer was a lot of work, for a simple 8KB memory card required over 1,000 solder connections. Only serious electronic hobbyists, such as those who attended the Home Brew computer club meetings at the Stanford Linear Accelerator Laboratories on Wednesday nights, built computers. (I saw a demonstration of Apple I at one of those meetings.) Since that first computer, which still works, I have changed microcomputers more often than I have changed cars. From their experiences with the Altair, Paul Allen and Bill Gates founded Microsoft to develop BASIC for the new PC world.
In 1976, four years after the initial public announcement that ARPAnet would use packet-switching technology, telephone companies from around the world through the auspices of CCITT (Consultative Committee for International Telegraphy and Telephony) announced the X.25 standard. Although both ARPAnet and X.25 used packet switching, there was a crucial difference in the implementations. As the precursor of TCP/IP, the ARPAnet protocol was based on the end-to-end principle; that is, only the ends are trusted and the carrier is considered unreliable (the section on TCP/IP later in this chapter covers this technology in more detail).
On the other hand, the telephone companies preferred a more controllable protocol. They wanted to build packet-switched networks that used a trusted carrier, and they (the phone companies) wanted to control the input of network traffic. Therefore, CCITT based the X.25 protocol on the hop-to-hop principle in which each hop verified that it received the packet correctly. CCITT also reduced the packet size by creating virtual circuits.
In contrast to ARPAnet, in which every packet contained enough information to take its own path, with the X.25 protocol the first packet contains the path information and establishes a virtual circuit. After the initial packet, every other packet follows the same virtual circuit. Although this optimizes the flow of traffic over slow links, it means that the connection depends on the continued existence of the virtual circuit.
CCITT regulated input into the network by enabling transmission only when the sender received a credit packet, thereby controlling the overall traffic throughout the network. Although X.25 is now a dying protocol, it played a very important role in the development of enterprise networks.
Therefore, the end-to-end principle of TCP/IP and the hop-to-hop principle of X.25 represent opposing views of the data transfer process between the source and destination. TCP/IP assumes that the carrier is unreliable and that every packet takes a different route to the destination, and does not worry about the amount of traffic flowing through the various paths to the destination. On the other hand, X.25 corrects errors at every hop to the destination, creates a single virtual path for all packets, and regulates the amount of traffic a device sends to the X.25 network.
The year 1979 was another milestone year for the future of the Internet. Computer scientists from all over the world met to establish a research computer network called Usenet. Usenet was a dial-up network using UUCP (UNIX-to-UNIX copy). It offered Usenet News and mail servers. The mail service required a user to enter the entire path to the destination machine using the UUCP bang addressing wherein the names of the different machines were separated by exclamation marks (bangs). Even though I sent mail on a regular basis, I always had problems getting the address right. Only a few UUCP networks are left today, but Usenet News continues as NetNews. Also in 1979, Onyx Systems released the first commercial version of UNIX on a microcomputer. As one of the consultants who worked with Onyx, I received one of the first machines off the production line, and thus began my UNIX career. I learned UNIX from a programmer who held to the old-time UNIX rule that if you don't know the answer, look it up in the source code. The only problem was that the UNIX source code lacked comments, which meant that I had to become a master at reading sometimes cryptic C code.
The traveler in me took me to a project in Nigeria for the next three years. I met many wonderful people there, but moving to Nigeria was a major technology shock. I went from delivering messages by e-mail to delivering messages via a human messenger, because that was the only reliable way to deliver messages from one site to another. When I had to make one particularly dangerous trip, the local priest sacrificed a goat in order to protect me from evil spirits. Upon returning to the United States in 1983, I warped back into a world of BITNET (But It's Time Network), CSNET (Computer Science Network), and many others.
The most crucial event for TCP/IP occurred on January 1, 1983, when TCP/IP became the standard protocol for ARPAnet, which provided connections to 500 sites. On that day the Internet was born. Since the late 1970s, many government, research, and academic networks had been using TCP/IP; but with the final conversion of ARPAnet, the various TCP/IP networks had a protocol that facilitated internetworking. In the same year, the military part of ARPAnet split off to form MILNET. As the result of funding from DARPA, the University of California's Berkeley Software Distribution released BSD 4.2 UNIX with a TCP/IP stack. In addition, Novell released NetWare based on the XNS protocol developed at Xerox Park, Proteon shipped a software base router using the PDP-11, and C++ was transformed from an idea to a viable language.
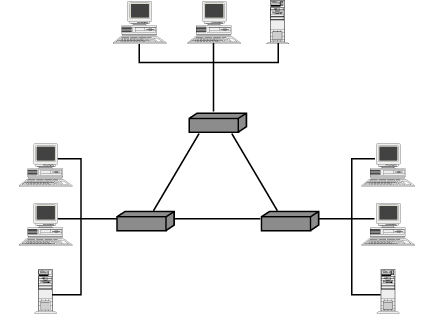
During this period, I took a job with a new company called DESTEK to develop the drivers for its new Ethernet card. As an employee of a true leading-edge company, I finished making some patches to the drivers in my hotel room the night before the 1983 Comdex show opened. That was the year in which the idea of building local-area networks (LANs) was new and hot. With the introduction of LANs, the topology of networks changed from the representation shown in Figure 1.2, which ties legacy systems together, to that shown in Figure 1.3, which ties LANs together.
Figure 1.3 : A LAN-based model for internetworks.
With the growth in number of organizations connecting to ARPAnet and the increasing number of LANs connected to ARPAnet, another problem surfaced. TCP/IP routes traffic according to the destination's IP address. The IP address is a 32-bit number divided into four octets for the sake of human readability. Whereas computers work with numbers, humans remember names better than numbers. When ARPAnet was small, systems used the host file (in UNIX the file is /etc/hosts) to resolve names to Internet Protocol (IP) addresses. The Network Information Center (NIC) maintained the master file, and individual sites periodically downloaded the file. As the size of the ARPAnet grew, this arrangement became unmanageable in a fast-growing and dynamic network.
In 1984 the domain name system (DNS) replaced downloading the host file from NIC (the section "IP Addresses and Domain Names" discusses the relationship between the two in more detail). With the implementation of DNS, the management of mapping names to addresses moved out to the sites themselves. During this time I moved to Fortune Systems and took over the project management of a new token ring product. Part of this new product included adding the Berkeley sockets technology to ForPro (Fortune's version of UNIX). With the introduction of Sun Microsystem's UNIX-based workstations in the same year, all the pieces of the technology needed to develop the Internet of today were in place.
For the next seven years, the Internet entered a growth phase. In 1987 the National Science Foundation created NFSNET to link super-computing centers via a high-speed backbone (56Kbps). Although NFSNET was strictly noncommercial, it enabled organizations to obtain an Internet connection without having to meet ARPAnet's defense-oriented policy. By 1990 organizations connected to ARPAnet completed their move to NSFNET, and ARPAnet ceased to exist. NSFNET closed its doors five years later, and commercial providers took over the Internet world.
Until 1990 the primary Internet applications were e-mail, listserv, telnet, and FTP. In 1990, McGill University introduced Archie, an FTP search tool for the Internet. In 1991, the University of Minnesota released Gopher. Gopher's hierarchical menu structure helped users organize documents for presentation over the Internet. Gopher servers became so popular that by 1993 thousands of Gopher servers contained over a million documents. To find these documents, a person used the Gopher search tool Veronica (very easy rodent-oriented netwide index to computerized archives). These search tools are important, but they are not the ones that sparked the Internet explosion.
In 1992 Tim Berners-Lee, a physicist at CERN in Geneva, Switzerland, developed the protocols for the World Wide Web (WWW). Seeking a way to link scientific documents together, he created the Hypertext Markup Language (HTML), which is a subset of the Standard Generalized Markup Language (SGML). In developing the WWW, he drew from the 1965 work of Ted Nelson, who coined the word hypertext. However, the event that really fueled the Internet explosion was the release of Mosaic by the National Center for Supercomputing (NCSA) in 1993.
From a standard for textual documents, HTML now includes images, sound, video, and interactive screens via the common gateway interface (CGI), Microsoft's ActiveX (previously called control OLE), and Sun Microsystem's Java. The changes occur so fast that the standards lag behind the market.
How large is the Internet today? That is a good question. We could measure the size of the Internet by the number of network addresses granted by InterNIC, but these addresses can be "subnetted," so the number of networks is much larger than InterNIC figures suggest. We could measure the size of the Internet by the number of domain names, yet some of these names are vanity names (a domain name assigned to an organization, but supported by servers that support multiple domain names) and other aliases. Vanity names and aliases result in a higher name count than the number of IP addresses, because multiple names point to the same IP address. Ultimately, the only way to measure the size of the Internet is by the number of accounts. In my opinion, a reliable study on the number of accounts does not exist. On the other hand, one change indicates an important perceptual change by the general public. Starting in the fall of 1995, companies and organizations began to include their uniform resources locator (URL), along with their street address, telephone number, and fax number, in television ads, newspaper ads, and consumer newsletters. Therefore, a company's presence on the Internet, as represent by its Web address (the URL), reached a new level of general acceptance. The Internet emerged from academia to become a household word. Even those not connected to the Internet now know of its existence.
The question arises as to where all this technology is going. Because my crystal ball is broken, please don't hold me to what I say. The one technology that I have not mentioned yet is virtual reality. The documents and images seen on the Web are only two-dimensional and have limited interaction. The Virtual Reality Modeling Language (VRML) attempts to bring a three-dimensional image to our two-dimensional systems. One of these days, we will have three-dimensional devices and will be able to enter a three-dimensional virtual world. In his 1984 science fiction novel Neuromancer, William Gibson coined the words cyperspace and cyperpunk. He defined cyperspace as a "consensual hallucination experienced daily by legitimate operators." How the future plays out depends on you, the reader, who develops the software of the future.
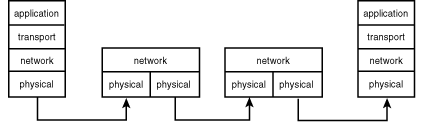
Many works on TCP/IP networking begin with a discussion of the seven-layer Open Systems Interconnection (OSI) model and then map the TCP/IP model to the OSI model. This approach fails because TCP/IP does not neatly map into the OSI model and because many application models do not map to the OSI application layers. If the OSI model fails to correctly reflect the nature of TCP/IP, what is the best model? Over the years, different authors have described TCP/IP with three-, four-, and five-layer models. Because it most accurately reflects the nature of TCP/IP, the following discussion of TCP/IP uses the four-layer model as depicted in Figure 1.4.
Figure 1.4 : The four-layer TCP/IP model.
The TCP/IP protocols have their roots in the Network Control Program (NCP) protocol of the early ARPAnet. In the early 1970s, the Transmission Control Protocol (TCP) emerged without the IP layer. Thus the three-layer model, consisting of the physical layer, transport layer, and application layer, was created. By the time OSI published its seven-layer model in 1977, IP was a separate layer, the Network layer. Some publications add a Data Link layer between the Network layer and Physical layer. However, such an expansion is not necessary because the TCP/IP model treats the Physical and Application layers as open-ended, thereby enabling each layer to have several different models. The following sections explore the layers of the TCP/IP model in more depth.
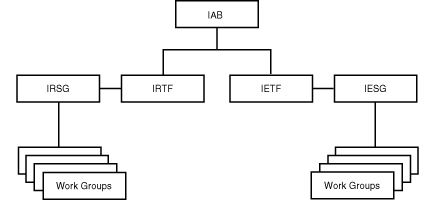
In addition to describing the flow of information, the four-layer model (physical, network, transport, and application) also organizes the large number of protocols into a structure that makes them easier to understand. In Internet jargon, the Request For Comment (RFC) describes a protocol. Today, more than 1,900 RFCs describe protocols, provide information, or are tutorials. In part, the success of the Internet is a result of the open nature of its organization. The Internet Activities Board (IAB) provides overall direction and management (see Figure 1.5 for the organizational chart), and task forces manage the development of new protocols. The Internet Research Task Force (IRTF) deals with the long-term direction of the Internet, and the Internet Engineering Task Force (IETF) handles implementation and engineering problems. The Internet Engineering Steering Group (IESG) coordinates the activities of the many working groups. Membership is not controlled by any organization; instead, anyone who so desires can participate. Anyone can submit an RFC, and anyone can participate in a workgroup. In many ways, the Internet is a grassroots organization that is beyond the control of any organization or government.
Figure 1.5 : The organization of the Internet Activities Board.
To get the latest status of the Internet or to obtain a copy of an RFC, the fastest route is via http://www.internic.net. In particular, RFC 1920 (or its replacement) describes the organization of the IAB in more detail, provides the status of RFCs, and gives instructions on how to submit an RFC.
As the lowest layer in the stack, the Physical layer has the task of transmitting the IP datagram over the physical media. Unlike the other layers, this layer has specific knowledge of the underlying network. As a result, detailed models of this layer depend on the transmission protocol being used. The sections "LAN Topologies" and "Internetworking-Linking LANs Together" explain these protocols in more detail.
In general, the Physical layer
The Network layer is sometimes called the Internetworking layer, which is a more descriptive term for this layer's main function. Three protocols are defined in this layer: the Internet Protocol, Internet Control Message Protocol (ICMP), and the Address Resolution Protocol (ARP). Of these, IP is the most important protocol.
RFC 791 defines IP as a connectionless and unreliable protocol. It is connectionless because a connection to the destination host does not have to be made prior to sending an IP datagram. The header of the IP datagram contains sufficient information for it to be transported to its destination over either connectionless or connection-oriented transmission protocols. It is an unreliable protocol because it does not perform any error checking. All error checking, if required, is the responsibility of a higher layer protocol.
What then is the purpose of IP? As the heart of the Internet, the functions of IP include
By creating a virtual network, IP hides the Physical layer and its underlying subnetwork from the end user. The user application needs to know only the destination IP address; IP hides the mechanics of delivery. It does this by fragmenting the packet received from the Transport layer to fit the Protocol Data Unit (PDU) of the transmission protocol. For example, the PDU for Ethernet is 1,500 octets; for SNAP, it is 1,492 octets; for X.25, it is 128 to 256 octets. For each transmission protocol encountered on a datagram's journey to the destination host, IP makes the fragmentation decision until IP reassembles the packet for the Transport layer at its final destination.
IP also handles routing of the datagram to its destination. IP accomplishes this by passing to the Physical layer the IP address of the next hop, where a hop is the distance between a device and a gateway or the distance between two gateways. The following are the rules IP uses for determining the next hop:
A gateway is any device that connects to two or more networks. The gateway then follows the same rules to make a routing decision. Because gateways make the routing decisions, the movement of the datagram from source to destination is independent of any transmission protocol. In addition, each datagram contains sufficient information to enable it to follow a separate path to the destination.
ICMP (RFC 792) performs the error reporting, flow control, and informational functions for IP. Following are the major characteristics of ICMP:
ICMP reports the following types of messages:
Address Resolution Protocol (ARP) and Reverse Address Resolution Protocol (RARP) present an interesting problem regarding which layer to assign these protocols to. Because they are used only by the multinode transmission protocols (Ethernet, token ring, and FDDI), ARP and RARP belong to the Physical layer. However, because the transmission protocol encapsulates their packets, they belong to the Network layer. To keep the encapsulation boundary clear, I have included them in the discussion on the Network layer.
ARP (RFC 826) resolves IP addresses to MAC addresses (the "Ethernet LANs" section provides additional information about the MAC address) by broadcasting an ARP request to the attached LAN. The device that recognizes the IP address as its own returns an ARP reply along with its MAC address. The result is stored in the ARP cache. On subsequent requests, the transmission protocol needs to check only the ARP cache. To allow for the dynamic nature of networks, the system removes any ARP entry in the cache that has not been used in the last 20 minutes.
RARP (RFC 903) performs a totally different function. If a device does not know its IP address (such as a diskless workstation), it broadcasts a RARP request asking for an IP address. A RARP server responds with the IP address.
The Transport layer provides two protocols that link the Application
layer with the IP layer. The TCP provides reliable data delivery
service with end-to-end error detection and correction. The User
Datagram Protocol (UDP), on the other hand, provides an application
with a connectionless datagram delivery service.
| NOTE |
Applications can use TCP, UDP, or both. The needs of the application determine the choice of protocols. |
For both TCP and UDP, the port number defines the interface between the Transport layer and the Application layer. The port number is a 16-bit value that identifies a particular application. The services file, in UNIX /etc/services, connects application names with the port numbers and the associated protocol. Following is a sample of the contents of the services file:
# Format: # # <service name> <port number>/<protocol> # echo 7/udp echo 7/tcp systat 11/tcp netstat 15/tcp ftp-data 20/tcp fdp 21/tcp telnet 23/tcp smtp 25/tcp time 37/tcp time 37/udp
Port numbers between 1 and 255 are the "well-known services," which represent the port numbers to common application protocols. The Internet Assigned Numbers Authority assigns the numbers for the well-known services, and RFC 1700 contains the current list of assigned numbers. Port numbers between 256 and 1024 previously referred to UNIX applications, although a number of these now exist on other platforms. BSD UNIX specifies that the numbers below 1024 require root permission. The remaining numbers are assigned to experimental applications and to user-developed applications. The packets sent by TCP and UDP contain both the source port number and the destination port number in the packet header. The section "Sockets and Socket APIs" covers the use of port numbers in more detail.
The Transport layer is stream-oriented and not block-oriented. The Applications layer sends data to the Transport layer byte-by-byte. The Transport layer assembles the bytes into segments and then passes the segments to the Network layer. TCP and UDP use different methods to determine the segment size as explained in the following sections.
The key to understanding TCP lies in the end-to-end principle.
In a nutshell, the principle says that only the ends can be trusted
because the carrier is unreliable. The ends, in this case, are
the TCP protocol of the source and the destination hosts. Thus
any error checking performed by the Physical layer is redundant.
| NOTE |
Use TCP when an application must have reliable data delivery. |
TCP uses a technique called positive acknowledgment and re-transmission
(PAR) to ensure reliability. After waiting for a time-out, the
sending host (or source host) retransmits a segment (the name
for a TCP packet) unless it receives an acknowledgment from the
destination host. The destination host acknowledges only segments
that are error free and discards any segments that contain errors.
Because an acknowledgment can arrive after the host resends the
segment, the receiving host must discard duplicate segments. Also,
because segments can arrive out of sequence (because each IP datagram
can take a different route between the sending host and destination
host) the destination host must resequence the segments.
| NOTE |
The stream-oriented nature of TCP means that the responsibility for management of blocks, frames, or records lies in the application. |
TCP sequentially numbers each byte in the input data stream and uses this sequence number to track the acknowledgments of data received by the destination host. To initiate the connection and establish the initial sequence number, the source host sends a sync packet to the destination host. The destination host responds with a sync acknowledgment that also contains the initial window size and, optionally, the maximum segment size. The window size represents the maximum amount of data that can be sent before receiving an acknowledgment. Because each acknowledgment contains the window size, the destination controls the flow of information. This form of flow control is separate from the flow control mentioned in the ICMP section. ICMP refers to IP buffers, whereas window size refers to TCP buffers. ICMP flow control affects the device one hop away (which may be a gateway or the source host); window size affects only the source host.
The acknowledgment message contains the highest consecutive octet received as well as the new window size. The destination host does not acknowledge out-of-sequence segments until it receives the intervening segments. After the time-out period elapses, the source host retransmits the unacknowledged portion of the window. This sliding window provides for end-to-end flow control and minimizes IP traffic by acknowledging more than one segment.
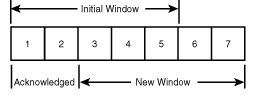
Figure 1.6 illustrates the principle of the sliding window. For the sake of simplicity, the segment size used in Figure 1.6 is 1,000 octets. The initial window size is 5,000 octets, as specified in the sync acknowledgment message. The source host transmits segments until the window size is reached. The destination host acknowledges receiving 2,000 contiguous octets and returns a new window size of 5,000, which enables the source host to send another 2,000 octets. Should the time-out period expire before the source host receives another acknowledgment, the source host retransmits the entire 5,000 octets remaining in the window. Upon receiving the duplicate segments, the destination host trashes these duplicates.
Figure 1.6 : TCP sliding window.
Upon receiving segments, the destination host passes the acknowledged segments to the receiving port number as a stream of octets. The application on the receiving host has the job of turning this stream into a format required by the application.
Just as the process to open a connection involves a three-way handshake, the closing process (fin) uses a three-way handshake. Upon receiving a close request from the application, the source host sends a fin request to the destination host, with the sequence number set to that of the next segment. To actually close the connection requires the acknowledgment of all segments sent and a fin acknowledgment from the destination host. The source host acknowledges the fin acknowledgment and notifies the application of the closure.
As I explained, the PAR method used by TCP minimizes the IP traffic over the connection. Furthermore, it does not depend on the reliability of the carrier. On the contrary, a carrier that spends too much time achieving reliability causes TCP to time out segments. For TCP/IP, a well-behaved transmission protocol trashes, rather than corrects, bad datagrams.
UDP (RFC 768) provides an application interface for connectionless,
unreliable datagram protocol. As mentioned at the beginning of
"The Transport Layer" section, the protocol does not
provide a mechanism for determining if the destination received
the datagram or if it contained errors.
| NOTE |
Because UDP has very little overhead, applications not requiring a connection-oriented, reliable delivery service should use UDP instead of TCP. Such applications include those that are message oriented. |
The UDP packet reflects its simplicity as a protocol. The UDP packet contains only the beginning and destination port number, the length of the packet, a checksum, and the data. It needs nothing else because UDP treats every packet as an individual entity.
Applications that use UDP include applications that
For each type of application, UDP eliminates unnecessary overhead.
The Application layer is the richest layer in terms of the number of protocols. This section covers the most popular protocols. The "Routing in an Internetwork" section covers the routing protocols, and "The Client/Server Model" section examines various models for application protocols. Despite this broad coverage, this chapter considers only a sampling of the many application protocols that have an RFC. An even greater number of intranet applications do not have an RFC. Applications need only follow the rules for interfacing to the Transport layer, and the socket APIs (covered in the "Sockets and Socket APIs" section) hide from the programmer the details of this interface.
It is important to remember that every TCP/IP application is a client/server application. When it comes to the well-known applications discussed in the following sections, the server side exists on every major hardware platform. Except for revisions to old application protocols and the development of new application protocols, much of the work in software development for the well-known protocols centers around the client side of the equation. This situation applies even to the wild world of HTTP. The once light Web browser now performs many tasks that once required the support of the server. Client-side image mapping, Java applets, and scripting languages such as JavaScript and Visual Basic make the Web browser the work horse. This transfer of processing to the client side leaves the server free to respond to more requests.
Telnet is one of the oldest and most complicated of the application protocols. Telnet provides network terminal emulation capabilities. Although telnet standards support a wide variety of terminals, the most common emulation used in the Internet is the vt100 emulation. Besides terminal emulation, telnet includes standards for a remote login protocol, which is not the same as the Berkeley rlogin protocol. The full telnet specification encompasses 40 separate RFCs. The Internet Official Protocol Standards RFC (RFC 1920 as of this writing) contains a separate section that lists all current telnet RFCs. However, telnet clients usually implement a subset of these RFCs.
Telnet remains the primary protocol for remotely logging into a host. Although the terminal emulation features are important, other protocols use the remote login portion of the standard to provide authentication services to the remote host. In addition to the traditional remote login standard, some telnet clients and servers support Kerberos (the security method developed by the MIT Athena Project and used in DCE) to provide a secure login capability.
FTP (RFC 959) is another old-time protocol. It is unusual in that it maintains two simultaneous connections. The first connection uses the telnet remote login protocol to log the client into an account and process commands via the protocol interpreter. The second connection is used for the data transfer process. Whereas the first connection is maintained throughout the FTP session, the second connection is opened and closed for each file transfer. The FTP protocol also enables an FTP client to establish connections with two servers and to act as the third-party agent in transferring files between the two servers.
FTP servers rarely change, but new FTP clients appear on a regular basis. These clients vary widely in the number of FTP commands they implement. Very few clients implement the third-party transfer feature, and most of the PC clients implement only a small subset of the FTP commands. Although FTP is a command-line oriented protocol, the new generation of FTP clients hides this orientation under a GUI environment.
The trivial part of the name refers not to the protocol itself, but to the small amount of code required to implement the protocol. Because TFTP does not include an authentication procedure, it is limited to reading and writing publicly accessible files. Consequently, TFTP is a security risk and must never be used to transfer data through a firewall.
TFTP uses the flip-flop protocol to transfer data. In other words, it sends a block of data and then waits for an acknowledgment before sending the next block. It uses UDP and therefore performs its own integrity checks and establishes a very minimal connection. In contrast to the richness of FTP, TFTP defines only five types of packets: read request, write request, data, acknowledgment, and error. Because TFTP is so limited, only a few applications (such as router management software and X-terminal software) use it.
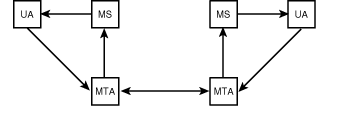
The word simple in Simple Mail Transfer Protocol refers to the protocol and definitely not to the software required to implement the protocol. Like telnet, many RFCs define SMTP. The two core RFCs are 821 and 822. RFC 821 defines the protocol for transfer of mail between two machines. RFC 822 defines the structure of the mail message. The mail handling system (MHS) model describes the components needed to support e-mail. As shown in Figure 1.7, the MHS consists of the mail transfer agent (MTA), the mail store (MS or mailbox), and the user agent (UA).
Figure 1.7 : Components of a mail handling system.
The MTA (such as sendmail) receives mail from the UA and forwards it to another MTA. Because the MTA for SMTP receives all mail through port number 25, it makes no distinction between mail arriving from another MTA or from a UA. The MS stores all mail destined for the MTA. The UA reads mail from the MS and sends mail to the MTA.
A UA executing on the MTA host needs only to read the MS as a regular file. However, the network UA requires a protocol to read and manage the MS. The most popular protocol for reading remote mail is the post office protocol version 3 (POP-3) as defined by RFC 1725, which makes RFC 1460 obsolete. So as to enhance the security of POP-3, RFC 1734 describes an optional authentication extension to POP-3. POP-3 transfers all of the mail to the UA and enables the mailbox to be kept or cleared. Because keeping the mail in the MS means that it is downloaded every time, most users choose the clear mailbox option. This option works when you have only one client workstation that always reads the mail. Users who need a more sophisticated approach to mail management should consider the Internet Mail Access Protocol (IMAP). RFC 1732 describes the specifications for version 4 of IMAP. With IMAP, the mail server becomes the mail database manager. This method enables a user to read mail from various workstations and still see one mail database that is maintained on the mail server.
In 1986, the year that Brian Kantor and Phil Lapsley wrote the Network News Transfer Protocol (NNTP) standard (RFC 977), ARPAnet used list servers for news distributions, and Usenet was still a separate UUCP network. With this standard, the door opened to establish Usenet news groups on ARPAnet. The NNTP standard provides for a new server that maintains a news database. The news clients use NNTP to read and send mail to the news server. In addition, the news server communicates with other news servers via NNTP.
The popularity of the Gopher protocol is without question. Because it provides a simple mechanism for presenting textual documents on the Internet, Gopher servers provide access to over one million documents. Nevertheless, RFC 1436, the only Gopher protocol RFC, is an informational RFC.
Gopher uses a hierarchical menu system, which resembles a UNIX file system, to store documents. The Gopher client enables the user to negotiate this menu system and to display or download stored documents. Before the popularity of the Web browser, Gopher clients, as separate applications, were popular. Today, the Web browser is the most common client used to display Gopher documents.
Although HTTP dates back to 1990, it still doesn't have an RFC. However, several Internet drafts reflect the "work in progress." Although the Web uses HTTP, HTTP's potential uses include name servers and distributed object management systems. HTTP achieves this flexibility by being a generic, stateless, object-oriented protocol. It is generic because it merely transfers data according to the URL and handles different Multipurpose Internet Mail Extension (MIME) types (see the following section for details about MIME types). Because it treats every request as an isolated event, HTTP is stateless.
Although an HTTP server is small and efficient, the client bears the burden of the work. The client processes the HTML-encoded document and manages all the tasks involved in retrieval and presentation of the retrieved objects. The URL and MIME open the doors to a degree of flexibility not found in any other document retrieval protocol.
The original MIME standard set out to resolve the limitations of the ASCII text messages defined in RFC 822. Using the content header standard (RFC 1049), the MIME standard defines the general content type with a subtype to define a particular message format. MIME is an extensible standard, and RFC 1896 describes the latest extensions. Once again, the client (the UA for an MHS) must take care of building and displaying MIME attachments to mail messages.
The simplicity and extensibility of the MIME standard led it to being used to extend the content of other protocols beyond the limits of ASCII text. The notable uses are in the Gopher protocol and HTTP.
Although serial and parallel links between computers had existed for some time, multinode networks did not become a serious commercial presence until the early 1980s. The growth of LANs came from two different directions. On the one hand, the corporate need to share files and resources (printers, plotters, and so on) among their PCs encouraged companies such as Novell, Banyan, and Microsoft to develop PC networks. On the other hand, the development of workstations meant that part of the workload could be moved from the server to the workstation. These contrasting developments led to the distinction between server-based LANs and peer-to-peer LANs. (See "The Client/Server Model" section for more details.)
The physical topology of a LAN refers to the networking cabling layout of which there are three types: bus (see Figure 1.8), ring (see Figure 1.9), and star (see Figure 1.10). However, there are only two types of logical topologies: bus (Ethernet) and ring (token ring).
Figure 1.8 : An example of a bus topology.
Figure 1.9 : An example of a ring topology.
Figure 1.10 : An example of a star topology.
The key difference between Ethernet and token ring is the method used to control access to the cable in a multinode network. Ethernet uses Carrier Sense Multiple Access/Collision Detection (CSMA/CD), which translates to "listen first, then send, and monitor for collisions." When a packet is placed on the cable, every node listens to determine whether the packet is addressed to it. If a collision occurs, the packet on the cable appears as garbage. The first node to hear the collision sends a jam packet, which forces the transmitting nodes to randomly set a delay before attempting to transmit again. As the amount of network traffic increases, the probability of a collision increases. In general, a traffic load between 20 and 40 percent of the bandwidth brings the network to a halt as it tries to resolve collisions.
The address used at this level is the MAC address and is not the same as the IP address. The MAC address is a 48-bit address that the manufacturer programs into each network card. To ensure against duplicates, each manufacturer is assigned a block of address by IEEE. As a media address, the MAC address applies only to LAN addressing. On the other hand, the IP address is a logical address that is independent of the media used in a particular network.
The multiplicity of Ethernet protocols confuses many newcomers trying to understand Ethernet LANs. Two Ethernet protocols are in use today: Ethernet (also called Ethernet II or DIX Ethernet) and IEEE 802.3. Although IEEE made many changes to the Ethernet II format, its change of the type field to the length field created a problem for TCP/IP, which uses the type field to define the type of IP packet. To get around this problem, IEEE 802.2 defines the Sub Network Access Protocol (SNAP), which once again includes the type field. Figure 1.11 illustrates the difference between Ethernet II and SNAP.
Figure 1.11 : Comparison of Ethernet II and SNAP protocols.
| NOTE |
DIX is an acronym for the three companies that defined the standard-Digital, Intel, and Xerox. |
Although Ethernet LANs support mixing these variations on a single network, two nodes must use the same protocol to communicate with each other. Therefore, every node on a TCP/IP network uses either Ethernet II or SNAP, but not both on the same network.
The 10Mbps bandwidth of Ethernet was fast 12 years ago; but with the increased use of multimedia in user interfaces, it no longer meets the demands of modern LANs. Fast Ethernet (100Mbps) offers one alternative, but a number of new hubs use a full-duplex technology to increase the effective utilization of bandwidth.
Instead of CSMA/CD, the token ring network passes a token from node to node. A node transmits only when it has the token. The transmitting node marks the token as in use and then transmits a data packet with the token attached. The receiving node acknowledges the receipt and passes the token back to the sender, which then marks the token as free and passes to the next node. This deterministic process ensures that each node receives equal access to the network under all load conditions.
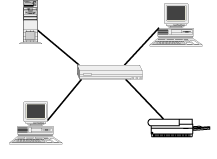
Although the IEEE 802.5 standard defines the token ring architecture, IBM developed a revised standard to which most token ring networks adhere. Although the topology defined by the standards is a physical star, the logical topology is still a ring topology. The multistation access unit (MAU) acts much like an Ethernet hub except that the MAUs are connected in a ring (refer to Figure 1.9).
Throughout the 1980s, token ring topology seemed poised to replace Ethernet. However, several factors prevented this from happening. The token ring hardware and software were more expensive than Ethernet components, but token ring cabling was cheaper. (Token ring uses unshielded telephone cable.) The introduction of the Ethernet hub in the late 1980s erased token ring's price advantage. In addition, even though token ring offered a 16-Mbps bandwidth (older versions used 4Mbps), the lack of standards for cabling led to vendor-dependent solutions.
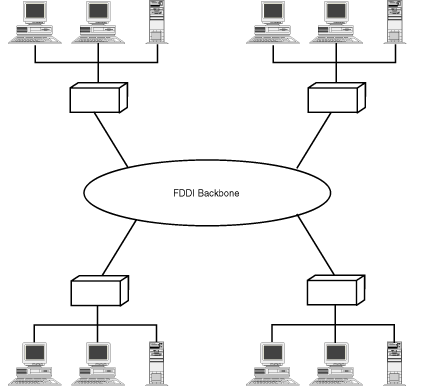
Fiber Distributed Data Interface (FDDI) also uses the token ring topology. Although the ANSI X3T9.5 committee started to define the FDDI standard in 1984, the standard did not stabilize until 1990. The frame format is similar to IEEE 802.5 standard for token rings, but operates at 100Mbps. Because of the high cost of fiber, FDDI networks often form the backbone to connect lower-speed networks (see Figure 1.12).
Figure 1.12 : Example of LANs connected by an FDDI backbone.
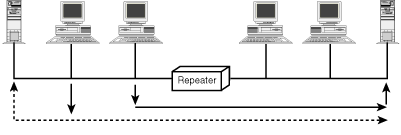
Repeaters, bridges, and routers perform their own unique functions in networking. The simplest device is the repeater, which sole function is to link LAN segments to form a longer cable. It passes on everything that it receives so that all the packets seen on one side of the repeater are repeated on the second side. Figure 1.13 illustrates the operation of a repeater.
Figure 1.13 : Illustration of a repeater in a LAN.
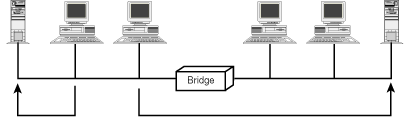
Bridges are, in a sense, intelligent repeaters. Instead of passing all traffic from one side to the other, bridges pass only traffic that is addressed to a node on the other side. The bridge accomplishes this task by looking at the MAC address of the frame in question. Because the bridge does not alter the frame, the LAN segments must use the same topology (Ethernet to Ethernet; token ring to token ring) on both sides of the bridge. Figure 1.14 shows a transparent bridge in an Ethernet network.
Figure 1.14 : A transparent Ethernet bridge.
The transparent bridge looks at the frame, but does not modify it. On the other hand, a translation bridge removes the frame encapsulation and then encapsulates the datagram with the frame protocol of the destination network. Multiport bridges route traffic according to the MAC addresses on each LAN segment. Yet even these more exotic bridges tie together only segments of a single network.
A router, on the other hand, routes traffic between separate networks. This capability earns a router the title of gateway, which is any device with two or more network interfaces. To accomplish its task, the router extracts the IP datagram from the frame, looks at the destination IP address, determines where to route the packet, and then encapsulates the packet with the frame of the next transmission protocol. Figure 1.15 illustrates the actions of a router.
Figure 1.15 : A model for routing IP datagrams.
The routing decision rules are the same as the Internet Protocol rules described earlier in the chapter. If the MTU of the next transmission protocol is smaller than the size of the IP datagram, the router fragments the IP datagram to fit the new MTU. Therefore, the destination host can receive many more IP datagrams than the originating host created. The end of the next section covers the routing protocols used to build the routing table.
The original ARPAnet was a wide-area network (WAN), but it was not an internetwork, at least in today's understanding of this term-LANs as we know them did not become popular until the 1980s. The connection of LANs marked the true birth of internetworking, for then individual LANs could connect to form an even larger network-an intranet. When LANs connect to the global network, they form the Internet. This section looks at the technology that makes this connection happen.
The most basic link between two networks is a point-to-point line between them. The telephone companies in the United States and Japan market these lines as T1, fractional T1, T3, and T4. A T1 line consists of 24 channels, each with a 64Kbps bandwidth (actually 56Kbps, because 8Kbps of the channel is for control signals) for a total bandwidth of 1.544Mbps. This scheme derives not from the needs of digital signals, but from the need to stretch copper wire by multiplexing voice channels. Thus, a fraction T1 line consists of one or more channels from a full T1 line. Going in the other direction, multiplexing 28 T1 lines forms a T3 (44.736Mbps) and six T3s make up a T4 (274.276Mpbs). In the rest of the world, the E1 line contains 32 channels with a bandwidth of 64Kbps for a total bandwidth of 2.048Mbps.
As delivered by a telephone company, these lines are devoid of any Physical layer protocol. Companies use three methods to transfer data between two routers:
To avoid depending on a single vendor for all your equipment, the preferred protocol is PPP. If PPP is not available, SLIP becomes a good second choice.
SLIP (RFC 1055) is an IP datagram encapsulation protocol that enables IP datagrams to be transmitted over an asynchronous serial line. SLIP works on both dial-up lines or leased lines. SLIP is a simple but crude protocol that works well with TCP. However, for protocols such as NFS that use UDP without having an error correction mechanism, SLIP is a poor choice.
Originally, serial links were synchronous links using the high-level data link control (HDLC) protocol. What PPP provides is an HDLC format over asynchronous serial lines. PPP offers many advantages over SLIP in that PPP
PPP establishes a connection in two stages:
PPP encapsulates the datagrams using a modified HDLC format. On a periodic basis, the two sides exchange LQM packets to monitor the line quality. The network administrator configures the acceptable quality levels. Because of its strengths, PPP is superior to SLIP or other proprietary protocols.
Although ARPAnet publicly demonstrated the effectiveness of packet-switched networks in 1972, CCITT did not define the X.25 standard until 1976. The X.25 standard takes a different approach to reliability. Instead of depending on higher level protocols, X.25 uses hop-to-hop verification of a packet. The standard's intent was to provide reliable delivery over lines with high error rates.
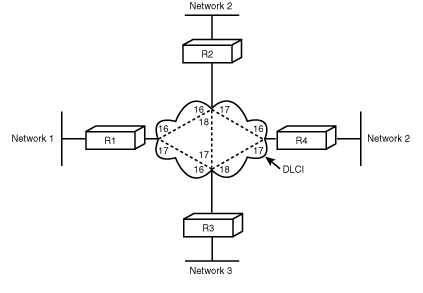
X.25 is connection oriented in that the sending party must initiate a connection to the receiving party. This connection establishes a virtual circuit that remains throughout the session. Because the virtual circuit is established at the time of connection, it is a switched virtual circuit (SVC). X.25 allows up to a maximum of 32 SVCs at the same time, of which four can be to the same destination gateway. Figure 1.16 illustrates the workings of an X.25 "cloud."
As Figure 1.16 illustrates, a WAN consists of a line, usually 56Kbps for IP, to the cloud, the SVC within the cloud, and another line to the destination gateway. Because multiple users share the lines within the cloud, X.25 regulates traffic via a credit mechanism. The sender cannot send data unless it has a credit. X.25 is not an ideal WAN protocol for TCP/IP networks for the following reasons:
In 1990, frame relay was the hottest new WAN protocol. Instead of an SVC, frame relay uses a permanent virtual circuit (PVC). To identify each PVC, frame relay uses a data link connection identifier (DLCI). As with X.25, frame relay requires a line to the cloud. The PVC exists within the cloud itself. Figure 1.17 shows a typical frame relay setup.
Figure 1.17 : Example of a WAN using frame relay.
Two factors determine the speed of frame relay connections: the bandwidth of the line into the cloud and the committed information rate (CIR). The bandwidth of the line into the cloud sets the maximum total bandwidth for all PVCs assigned to the line. The CIR sets the guaranteed bandwidth within the cloud. If the rate of transmission for a PVC exceeds the CIR, the excess frames are subject to being trashed if the cloud needs the extra bandwidth to meet its committed rates, which is how frame relay regulates traffic in the cloud. This method fits with TCP's end-to-end principle. In addition, frame relay supports an MTU of 4,500 octets, which eliminates fragmentation.
After years of standards and more standards, ISDN is hot news. But despite all the media attention, is ISDN really a viable technology for building intranets or connecting to the Internet? Telephone companies offer ISDN as either a basic rate interface (BRI) or a primary rate interface (PRI). BRI consist of two 64Kbps channels (referred to as B channels) and one control channel (called a D channel) or 2B+D. The rarely used PRI consisted of 23 B channels plus a control channel (23B+D). ISDN is a dial-up service that enables one site to connect to another ISDN site. However, because it has only one D channel, the B channels cannot be connected to different sites.
Normally, the consumer pays a low monthly fee plus, in some states, a connect time charge. The cost of an ISDN connection is lower than the packet charges for X.25. However, when compared to the fixed monthly charge for frame relay, the cost for a heavily used ISDN connection is higher.
Although the number of ISDN equipment providers is increasing, ISDN still suffers from problems with interoperability. Problems of interoperability apply not only to the equipment but also to the transmission protocols used to carry the IP datagrams. Some vendors push asynchronous transfer mode (ATM) as the best protocol, while others use PPP. In general, ISDN is not the best solution for primary WAN connections, but is an alternative for backup lines and for high-speed dial-up connections.
Media announcements bill ATM as the technology of the future. Does it really deserve such intense hype or is it on the road to becoming another ISDN? While the development of ATM standards proceeds toward a full definition of ATM, manufacturers are busy producing ATM equipment. At this point in time, we face conflicting protocols for defining IP over ATM. RFC 1932 discusses this problem and summarizes the issues facing the ATM Working Group. Yet, IP over ATM is only the first step. Standards for ATM as a transport protocol are still in the works.
Following along the lines of X.25, ATM networks are connection-oriented, SVC networks. By using a small packet (called a cell in ATM terminology), ATM evenly multiplexes cells that contain data, voice, or video information. However, the small cell size increases the overhead and increases fragmentation. Until ATM standards stabilize, the question of the viability of ATM remains open.
The previous section on routers covered how routers direct IP datagrams between networks and how routers connect networks that use different transmission protocols. This section deals with building the routing table that IP uses to make routing decisions.
The network administrator has the option to manually define static routes. However, in a large and dynamic network, this process is both tedious and prone to error. On the other hand, routing protocols automatically discover networks and the paths to the networks. However, like everything else in the Internet, routing protocols evolved over the years to meet new network demands.
Routing Information Protocol (RIP) was the first route discovery protocol defined by IETF. Because part of the job of a route discovery protocol is to find alternative paths between networks, RIP uses the distance-vector method to accomplish this task. In brief, the distance-vector method determines the "cost" of a path by the number of hops required to reach a network. The path with the lowest cost is stored in the routing table. Periodically, RIP rediscovers the network to find any changes. One problem with RIP is that the lowest cost path might not be the fastest path. Although many routing protocols exist, the open shortest path first (OSPF) protocol is the best solution to route discovery. Instead of using the distance-vector method, OSPF uses the link-state metric approach. OSPF adapts more quickly to changes in the network than does RIP.
As the size of the Internet increased, route discovery protocols created two problems: the routing tables became massive, and route discovery protocols consumed too much of the network bandwidth. The solution was to divide the Internet into autonomous systems (AS). Within an AS, the interior gateway protocols (IGPs), such as RIP and OSPF, dynamically discovered the network. Between autonomous systems, an exterior gateway protocol (EGP), such as the exterior gateway protocol (EGP) or the border gateway protocol (BGP), shared information between neighboring autonomous systems. Today, BGP version 4 (BGP-4) is the standard Internet EGP. However, as the number of routers connecting to the Internet continue to increase, the IETF continues to work on ways to reduce the amount of route discovery traffic. In the early 1990s, InterNIC began distributing class C addresses in classless interdomain routing (CIDR) blocks. CIDR permits the routing of class C addresses as a block rather than as individual networks. However, even CIDR is but a short-term fix to a growing problem.
Internetworking routes IP datagrams according to the IP address, but humans find names easier to remember. This section briefly reviews the principles of IP addresses and provides an overview of how names are resolved to addresses.
Perhaps the easiest way to understand IP addresses is to look at the Internet as a global network. All networks that comprise the global network are just subnets. InterNIC provides the first level of subnetworking by dividing the global address space into classes that are assigned to organizations. The organizations are then responsible for subdividing their assigned address space to meet their network needs.
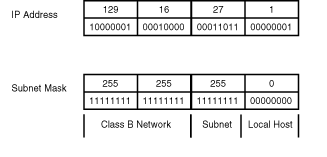
The IP address is a 32-bit number. To simplify the notation of addresses, divide this number into four octets and write the octets in a dotted-decimal format. Three types of IP addresses exist: network address, host address, and broadcast address. Because every host is part of a network, you divide the IP address into a network portion and a local host portion. When the local host portion is all zeros, it is a network address; all ones is a broadcast address. Anything else is a host address. However, the IP address itself contains no information about what constitutes the network portion versus the local host portion. The subnet mask provides this information. By convention, binary ones define the network portion, and zeros define the local host portion. Again, by convention, the ones must be contiguous to the left, and the remainder is zeros. Figure 1.18 illustrates this scheme.
Figure 1.18 : IP addresses and subnet masks.
As mentioned previously, InterNIC splits the global address space
into classes and then assigns the network address according to
these divisions. Table 1.1 shows the breakdown of the address
space.
| Table Class | Network Address | Subnet Mask | No. of Networks |
| table A | 1-126 | 255.0.0.0 | 126 |
| table B | 128-191 | 255.255.0.0 | 16,384 |
| table C | 192-223 | 255.255.255.0 | 2,097,152 |
| table D | 224-254 | 255.255.255.0 | (experimental) |
As mentioned before, the designations shown in Table 1.1 represent assigned network addresses. The network manager for an organization is then responsible for additional subnetting, according to the requirements of their individual networks.
Several special IP addresses also exist. For an Internet programmer, the most important special addresses are the local loopback address and the broadcast address. For the network administrator, the most important special addresses are those set aside for networks not connected to the Internet.
The local loopback address (127.0.0.1) enables a client application to address a server on the same machine without knowing the address of the host. This address is often called the local host address. In terms of the TCP/IP protocol stack, the flow of information goes to the Network layer, where the IP protocol routes it back up through the stack. This procedure hides the distinction between local and remote connections.
Broadcast addresses enable an application to send a datagram to more than one host. The special address 255.255.255.255 sends a "limited broadcast" to all hosts on this network. A "direct broadcast" uses the address form A.255.255.255, B.B.255.255, or C.C.C.255 to send messages to all hosts on a particular class A, B, or C network. Finally, a broadcast to a particular subnet is to the address with all local host bits set to one.
RFC 1918 specifies an Internet "best current practice" for address allocation on private internets (intranets). For a network not connected to the Internet, or a network where all Internet traffic passes through a proxy server, the Internet Assigned Numbers Authority (IANA) reserved three blocks of IP address space: 10.0.0.0 to 10.255.255.255, 172.16.0.0 to 172.31.255.255, and 192.168.0.0 to 192.168.255.255. This block is equivalent to one class A address, 16 class B addresses, and 256 class C addresses.
In the early days of ARPAnet, a system resolved names to addresses using the hosts file. The Stanford Research International (SRI) maintained the hosts file, and each site periodically downloaded an updated copy of the file. As the number of sites connected to ARPAnet increased, this method proved too hard to maintain and placed an increasing burden on the network. In 1984 Paul Mockapetris, of University of Southern California's Information Sciences Institute, released RFCs (882 and 883) that describe the domain name system. Today, DNS is the standard for resolving names to addresses. However, the hosts file still plays a role in name resolution during the booting of a system and as a means to provide LAN resolution when DNS is down.
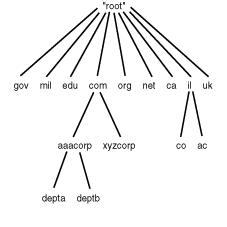
In a nutshell, DNS is a distributed database whose structure looks like the UNIX file system. DNS is a client/server system in which the resolvers query name servers to find an address record for a domain name. The query process begins with the root name servers. If the root name server does not know the answer, it returns the address of a name server that knows more details about the domain name. The resolver then queries the new name server. This iterative process continues until a name server responds with the address for the domain name. Figure 1.19 illustrates the structure of DNS.
Figure 1.19 : The hierarchical structure of DNS.
The resolver maintains the retrieved information in a cache until the designated time to live (TTL) for the record expires. This approach reduces the number of queries and, at the same time, responds to the dynamic nature of networks. By distributing the database across the Internet, the site responsible for the information maintains the information.
By definition, every TCP/IP application is a client/server application. In this scenario the client makes requests of a server. That request flows down the TCP/IP protocol stack, across the network, and up the stack on the destination host. Whether the server exists on the same host, another host of the same LAN, or on a host located on another network, the information always flows through the protocol stack.
From the information presented to this point, the client/server model has some general characteristics:
By specifying only the interface between the Application layer and the Transport layer, the TCP/IP Application layer permits various Application layer models. This open-ended approach to the Application layer makes it difficult to draw a single model that illustrates all TCP/IP applications. On one end of the scale, applications run as shell-level commands; on the other, applications run in various window environments. For example, the traditional telnet is run from the shell. Yet, some implementations of the telnet client take advantage of windows technology. To make life more complicated, telnet implementations are also available for the distributed computing environment (DCE). C++ client/server applications use the Object Management Group's (OMG) Common Object Request Broker Architecture (CORBA) model. Consequently, trying to define a universal Application layer model is an exercise in futility.
However, even with all the variations, the Web browser continues to grow as a popular Windows environment for the implementation of the client side of the equation. By using a common windowing environment, users access the Web, connect to remote with telnet, download files, read mail, and access Usenet through one interface. Although browsers implement this interface in a variety of ways, the direction is toward using the browser as an interface to Internet applications.
As mentioned earlier in the chapter, the port number is an application identifier that links the Application layer to the Transport layer. However, because multiple users can run the same application, the identification of a unique connection requires additional information. The Transport layer creates a unique connection via a socket, which is the port number plus the IP address. The combination of the sending socket plus the receiving socket provides a unique identification for every connection.
However, if both the sending host and receiving host use the port number defined in the services file, then multiple connections between two hosts for the same application (for example, two FTP connections) results in identical socket pairs. To solve this problem, the source port number is some unique number not related to the services file. This number depends on the particular implementation. For example, UNIX-based TCP/IP uses the process number for the source port number because the process number is always unique. This scheme guarantees the uniqueness of any socket pair. Figure 1.20 illustrates how sockets work.
Figure 1.20 : A session established using sockets.
The Transport layer keeps track of these socket pairs by storing them in a port table. Although this device solves the technical problems, the use of socket APIs hides the details of the interface from the programmer.
In 1981, BSD introduced UNIX BSD 4.2, which contained a generic socket interface for UNIX-to-UNIX communications over networks. In 1986, AT&T introduced the Transport Layer Interface (TLI), which provides a stack-independent interface. UNIX SVR4 provides both TLI and the Berkeley socket interface. For Microsoft Windows, the WinSock is the socket API and follows the Berkeley socket interface standard. Novell adopted TLI as the standard interface to the Transport layer, although NetWare also supports NetBIOS, Named Pipes, and sockets. As part of the revised SNA standard, IBM introduced the Common Programming Interface for Communications (CPI-C) as another API standard for network communications. With different APIs on different platforms, true portability of software is still an elusive goal. Nevertheless, using an API simplifies the task of writing network software.
Not too long ago, programmers developed applications; now they develop applications, plug-ins, and applets. Although a program is a program, the name attached to it tells us something about the nature of the program. Alas, there are more gray zones than black and white ones. In spite of this overlap, some well-defined characteristics separate applications, plug-ins, and applets.
Starting with an application, the common characteristics are that:
On the other hand, a plug-in's characteristics are that:
And then we have the Java applet. Is it a "small application," or is it something else? A Java applet
Whereas applications and plug-ins must be ported to each hardware platform, applets run on any platform that has a Java runtime. Thus, applets provide an object-oriented, multiplatform environment for the development of applications.
This chapter provided