{kind=link}
{kind=link}




by Bob Breedlove
Masses of people worldwide are tapping into the World Wide Web (abbreviated WWW or simply the Web), lured by graphic interfaces and relatively inexpensive access to unlimited information. Many companies see these Web residents as a ready-made pool of potential customers and are turning to the Web as the next great untapped market.
The Web can be an excellent infrastructure for your application. By infrastructure, I mean that the Internet can provide a common transport mechanism and, through the Web browser interface, provide a well-known and familiar interface to your application. This is especially true if you need to build an application that can do the following:
Any of these requirements need telecommunications to achieve their goals. Most require that you program a graphical user interface (GUI). And some, like online catalogs, require that you display pictures of your products. Before jumping on the Web just because it's the hottest thing going, you might examine traditional alternatives for your application, such as the following:
The Internet and the capabilities that it supports, such as the Web, offer advantages in ease of use, cost savings, and immediacy of information. But before you rush off to get your company a set of Web pages, read on.
The public Internet can be a good choice for the infrastructure for all or part of your application, but when you program for the public Internet, you face design issues beyond those for an application on a single computer or a dedicated network. This chapter discusses these design issues and offers some guidance to help you produce viable Internet applications, whether you're performing custom programming or programming for commercial Web browsers.
Designing applications for the Internet is challenging, first of all because you are designing client/server applications. These types of applications are always challenging, but using the public Internet adds to this challenge primarily because you don't control most of the infrastructure over which your application runs. To understand this issue, review the following sections for a brief look at the Internet.
The Internet as we know it today is more a concept than a reality. Strictly speaking, the Internet really doesn't exist. This statement might sound radical; after all, for something that's more concept than reality, a tremendous amount of activity exists on it. To understand this statement, you have to look at what the Internet is-or, more precisely, what it isn't.
The Internet is not a centrally owned or managed resource. There is no "Internet Committee," "Internet Administrator," or "Internet Help Desk." As you see later in this chapter, naming and addressing are centrally controlled of necessity, but that's about the extent of central control. So, if the Internet doesn't exist, how are all these people doing business on it? What is it?
The Internet (with a capital I ) is a network of networks (an internetwork, or internet-small i ). In the most simple terms, the Internet is a router-based TCP/IP wide area network (WAN) formed by the cooperation of independent organizations. These organizations include
These entities cooperate with each other by allowing "public" TCP/IP packets to pass through their resources (cables, routers, bridges, computers) for the benefit of all concerned. These packets carry the information for your application across the Internet. The whole thing is held together by router tables, as described in the following section.
Routers and bridges (generally called gateways) make an internetwork function. These devices are specialized computers that use tables of addresses ("router tables") to tell how to get packets of information from one network to another. These tables are maintained by some automatic processes (caching) and by human beings. Invalid router tables can be one of the causes of failed transactions. Look at an example of how they work to get information around the Internet.
My workstation is located on the local area network (LAN) at our building. When my company decided to become linked to the Internet, the company's network naming group contacted the Network Information Center (NIC) to request a block of addresses. They were assigned the address 198.132.0.0. Later, when our LAN was installed, we requested a TCP/IP address from the corporate naming group and were assigned the address 198.132.57.0. When my machine was added to the LAN, it was assigned this address: 198.142.57.4. TCP addresses are defined by a set of 4 numbers separated by periods. Each number can have a value between 0 and 254. There are various classes of addresses that define the meaning of the numbers. For your address class, the first three nodes of the address define the network. (That is, given the address 111.222.333.444, 111.222.333 defines the network. The last number, 444, identifies the particular device on that network.)
When my Web browser needs to communicate with another computer, it uses the address of the computer to establish a connection (socket) for communication. Suppose that I want to talk to a computer at 144.44.44.4. Because the address isn't on my LAN, the request is routed to the LAN "gateway." This "router" has tables listing LANs about which it knows. If it doesn't know about the specified LAN, it sends it to a default "gateway," and so it goes until it finds the address. After the packets reach the gateway on 144.44.44.0, the router there routes the packets to the machine whose address is 144.44.44.4.
The Internet could operate entirely from these addresses; however, for humans, it's better to use names that are meaningful. (It's the same reason that companies try for phone numbers that can be rendered as meaningful words.) For example, www.microsoft.com is much easier and more meaningful than 198.105.232.6. These names are often referred to as domain names. Internet addresses are divided into domains. For example, this address is in the com (commercial) domain.
It's also easier on network administrators to use names. If the administrator has to physically move the machine hosting your Web pages to another network or has to relocate the Web server to another machine, all he has to do is change the name mapping after the machine or service has been relocated, and the machine is logically moved. Incidentally, if you look up www.microsoft.com, you'll actually get three addresses-another benefit of domain names. Domain name servers (DNS) provide these services based on naming standards and protocols that make this possible.
In simplified terms, when you type in an address like this, the browser extracts the www.microsoft.com portion of the address and formats a name request for the designated name server:
http://www.microsoft.com
The request causes the name server to return the correct dot-notation address (xxx.xxx.xxx.xxx) for Microsoft's Web server. The browser then contacts the server on the designated port using the HTTP protocol and establishes a socket connection to pass information. (Even www is probably an alias for the actual machine name. This system enables the administrator to change the machine or map the name to additional machines-without having to notify millions of Net residents that the name has changed.)
When most of us think of the Internet, what we really think about are the tools that we use over the Internet-Web browsers, Telnet programs, File Transfer Protocol (FTP) modules, news and mail readers, and others. As you will see, these tools are client/server tools. That is, they consist of a piece of software on your workstation that requests services of another piece of software on a computer in another location. These tools are made possible by wide adoption of standards and protocols including the following:
Thus, when you "surf the Net," you really aren't connecting with some monolithic "Internet program." What you're really doing is using a set of client/server programs to return pages of information from a server (the HTTP daemon) to a client (the Web browser).
When you design an application for use over the Internet, you design a client/server application. Your custom software can provide both the client and server portions of the application, or you can choose to use standard software for either or both ends of the application. For example, you can choose to write the host (server) portion of the application to be a Web server that can take advantage of any commercial Web browser available on the market. On the other hand, you can choose to implement the host portion of your application as a Common Gateway Interface (CGI) module, and use a commercial Web server to provide the routing to a commercial Web browser. In another example, you can design an application using Java or another plug-in scripting language that utilizes commercial Web browsers and hosts.
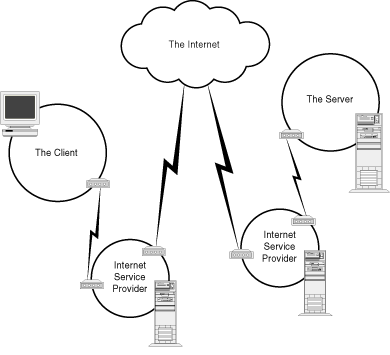
Whatever your application, you must be connected to the Internet to make it work. Figure 2.1 illustrates some typical Internet connections.
Figure 2.1 : Typical Internet connections.
Many variations on this theme exist but, to simplify matters for discussion, assume that the client has a connection to the Internet through an Internet service provider (ISP) from a local area network (LAN). The server (host) also has a direct connection from its LAN to its ISP.
The most typical variation on this setup is for the client to have a dial-up connection over asynchronous modem to the ISP. In essence, once connected, this variation is the same as the dedicated connection. However, it's usually much slower than the dedicated connection-typically 9,600 to 28,800 baud versus 56Kb and up.
Whatever the connection, when you fire up your Web browser to access some information on the host, here-in simplified form-is what happens.
You enter a particular address (a Universal Resource Locator or URL) into your Web browser. Your browser makes a connection to your domain name service (DNS) to request a translation of the human-readable URL to a dot-notation IP address for the host. Your DNS might have to request the address from other domain name servers to fulfill your request, but assume that it returns the address successfully. (Of course, if this is your application and not a Web browser, it has to deal with the case in which the address is not returned successfully.)
Your browser "client" requests a socket connection to the HTTP "host." This request passes through your router to the ISP, and through its router(s) onto the Internet. Here it can pass through several other machines before it reaches the host's ISP and eventually the host. Assuming that the host has the capacity, the socket connection is established between your browser and the HTTP daemon running on the host. (A daemon is a program that runs continually on a host. In the case of an HTTP daemon, it's looking for socket requests on a particular port-typically port 80).
Your browser then communicates with the host, using the HyperText Transport Protocol (HTTP). The actual requests and pages are created using the Hypertext Markup Language (HTML). The browser requests the particular page, which is returned by the daemon. After the page has been returned, the socket connection is broken, and your browser translates the HTML into the page layout that you see.
It is important to note that the connection is broken. That is,
unless some mechanism is designed to retain information either
at the client (Web browser) or the server (Web server), the information
is lost. The next time your client application communicates with
the server, it will be as if it had never communicated with that
server before. Designers often use cookies, which are stored
on the client machine, or database records, which
are stored on the server and keyed by some information passed
by the client, to track necessary information.
| TIP |
The fact that the socket connection isn't maintained throughout the "conversation" is an important consideration in programming for the Web. |
Because Internet protocol (IP) addresses are used in the packet
routing process that is at the heart of the Internet, they can't
be allocated in a random fashion. Network naming and addressing
is controlled by the Network Information Center (NIC), but it's
really the only thing that is centrally controlled.
| NOTE |
The NIC is currently managed by Network Solutions, Inc., located in Chantilly, Virginia. To download information, access ftp://rs.internic.net/ via anonymous FTP. |
Each segment of the Internet is controlled by the organization that owns the resources. That organization makes the rules for that segment. Each organization makes bandwidth available to pass IP packets through their routers and along their network. They can place restrictions on the use of these resources. Your packets will potentially pass through several machines, routers, and other devices that are owned and controlled by someone else.
As stated earlier, you don't own most of the resources over which your application will operate. Because you don't own the resources, you don't make the rules. This means that you have to abide by the rules established by others-for completely different reasons than the objectives of your application. This situation can result in such unwanted results as finding that the user's ISP restricts the size of messages it forwards, or that your customers can't reach your home page because a name server is down for maintenance.
The point is that, when you run your application over the Internet, you can't complain to some central authority when something goes wrong. Of course, you can complain to your network administrator about your local resources or to your ISP about your Internet connection. But, aside from that, you have to take what you get.
In fact, sometimes the problem is finding out what the rules are. When a transaction fails, often there is no indication of the reason. Luckily, organizations supporting the Internet operate within broad guidelines and standards.
Despite this problem, the whole thing seems to operate pretty well for the most part. However, you should keep in mind the points in the following sections as you design your application.
You might design, develop, and test your application over one path that exists because of some organization's resources. The application runs great. Then you find out that the organization has gone out of business or decided not to carry Internet traffic, and your path to your end user suddenly changes-with negative results for your application.
You might also find that resources are temporarily unavailable. A domain name server might be unavailable during a critical period of time for your business, like month end, because the host machine is undergoing maintenance during that period. A particular host can be overloaded on Fridays or at the end of the month because it's carrying traffic from its organization's month-end processing.
It's critical to remember that the owners of resources can do anything they want with their resources. They can change their maintenance schedules, move domain name servers, modify bandwidth, and more-all without consideration for your application. After all, they run their systems primarily for their benefit. They make decisions based on their business plan and system designs, not yours. Later in this chapter, you see how to design your application to take all of these factors into account.
Because you can't control the resources on the Internet, you can't
guarantee the timing of your transactions. An interaction that
completes in a matter of seconds one time can take several minutes
the next time-the next day, your application might not even be
able to make the connection. For this reason, timing-critical
transactions should not be placed on the public Internet.
| CAUTION |
Don't place timing-critical applications on the Internet. |
To this point, this chapter has discussed several issues facing
applications intended for the public Internet. It probably seems
that you're at the mercy of other organizations and the whole
thing is unreliable enough that you might as well give up. Perhaps
you are and perhaps it is, but applications are running successfully
on the Internet. And the capability to reach a whole world of
potential customers is driving Internet development at a staggering
pace.
| TIP |
Good system design and development techniques still hold for Internet applications. Planning is the key to a successful application. |
The key is to plan for the Internet environment just as you would if you were designing this application for your own network or private TCP/IP network (intranet). As you see later in this chapter, good system design and development techniques still hold for Internet applications. You just have to plan for some of the idiosyncrasies of the medium. The remainder of this chapter examines what you can do to design your application for the Internet.
Following a good system development methodology is still the best way to design for the Internet. Starting with requirements definition, through business design and into detailed technical design, construction, and testing, the Internet portion of your application must be designed just as you would design any other modules in your application.
The decision to use the public Internet for your application must be made based on business reasons. After all, alternatives to the Internet do exist:
Each of these options has advantages and disadvantages that must be considered. Private networks are reliable and secure, but very expensive. Direct dial-up access provides an alternative for users who don't require full-time access to your application. Online services can provide easy access for users who might already be members of the service, but they can be expensive for your users and are not as secure as private networks.
And, of course, some applications aren't appropriate for the Internet, or simply won't run over the Internet. For example, applications requiring results in real time aren't appropriate, and applications requiring extra security (such as personnel applications) are probably inappropriate because of security concerns.
If you consider the use of the public Internet from the beginning of your project, you won't be caught by the surprises that can result from use of the public Internet. Many of these considerations can be complex and can take a good deal of planning or preparation to integrate into your application.
For example, if you plan to have a special domain name for the public to access your application, you must request it from the NIC. This process can take some time. You might have to reconfigure your routing tables to accommodate the machines on which your application will run. You might have to deal with corporate firewalls (special-purpose computers that isolate corporate networks from the general Internet) and other corporate standards to implement your application. The time that these issues take needs to be integrated into your development plan. (See Chapter 4 "Developing Intranet Applications," for more details about dealing with intranet considerations.)
Not all components of your application can be Internet-based. Early in your application design, you need to determine which modules of your application will be Internet-based. Because the timing and security are major issues of using the Internet, modules requiring strict security or where timing is critical should not be implemented on the Internet.
The remainder of this section examines modules that might be considered for Internet implementation.
Modules of your application permitting public access are natural candidates for the Internet, for several reasons.
By designing an interface that enables your users to take advantage of tools they already know, you can avoid the training issues that could result from requiring users to learn proprietary programs and new interfaces. The users of your system probably already know how to access the Internet by using their Web browsers, mail and news readers, and File Transfer Protocol (FTP) clients. Introducing your new screens, new addresses, and new filenames is an incremental change in known procedures for your potential users. This setup can make your system less intimidating for potential users and can be especially important if you are designing an online ordering or customer service application.
Applications are often implemented into existing infrastructures. To avoid excessive costs, you might have to accommodate existing end-user platforms. In many companies, this is a mix of PC, Macintosh, and UNIX workstations. You also might want to accommodate customers' equipment and software. Internet tools enable you to reach a wide variety of customers using any type of equipment.
For example, a Web browser is an excellent choice for a client/server application over the Internet. When you write for Web browsers, you can eliminate the need to consider the hardware platforms on which they're located. The Netscape browser, for example, runs on PCs running Microsoft Windows, on the Apple Macintosh, and on various UNIX platforms running X-Windows. Other Web browsers are also available, such as lynx, a text-based browser, the Microsoft Internet Explorer, and browsers supplied by online services such as CompuServe and America Online (AOL).
Writing applications that create Web pages (generate HTML) is relatively simple. Formatting forms (screens) is also relatively simple. However, you need to take the points in the following sections into account.
Hypertext Markup Language (HTML) is derived from Standard Generalized Markup Language (SGML, formally called ISO 88791) used in the publishing industry. HTML, together with URLs (Universal Resource Locators) and HTTP, is one of the foundations of the World Wide Web. There have been two revisions of the HTML standard (1.0 and 2.0). However, two major players in the Web browser marketplace-Netscape and Microsoft-have defined extensions to this standard that have become very popular. Netscape's version 2.0 browser, in particular, implemented several very desirable features that other browsers don't support. Since then, Microsoft and Netscape have both released version 3.0 of their respective browsers, which have further diverged from each other. Because of the installed bases of these browsers, the extensions they have implemented are a de facto standard when writing HTML.
Other browsers used on alternative platforms and through various online services might not implement these extensions. Still other browsers are text-based, and don't support many of the graphics that have become so popular on the Internet. Lynx is one of these browsers, implemented for UNIX shell accounts for many Internet service providers, because they provide only a text interface for the user.
To use browsers at the desktop (client), you are faced with a choice in designing your application: You can write for a particular browser, such as the Netscape or Microsoft browser, or a set of browsers that implements a particular standard or pseudo-standard. Or you can write your application so that a wide range of browsers can take advantage of the application. These are the issues involved in making the choice:
<IMG SRC="..." ALT="[INDEX]"> <IMG SRC="..." ALT="[NEXT]"> <IMG SRC="..." ALT="[PREVIOUS]">
WYSYMNG stands for What you see, you might not get. Programming for a Web browser is much like programming for X-Windows. That is, you can "suggest" what the screen will look like by programming HTML directives such as bold (<B>) or heading 1 (<H1>), but you really don't have control over the total look of the final product on a particular user's browser.
You can spend a lot of time on page design to make your application user-friendly and appealing to your clients, but differing equipment and software can cause the best page to look ugly and sometimes become just barely usable.
Also, remember that the Internet is a public medium. If your application will be used by consumers, they have a lot of really "cool" pages with which to compare it. You have a lot of competition; your pages have to look their best to attract and keep the attention of the customer.
Your pages might not turn out as you planned, for several reasons:
Testing is the key. Test your pages on a reasonable number of configurations. If you're writing for commercial Web browsers at the client end, test for the major programs, at least. This means that you will probably test with Netscape Navigator and Microsoft Internet Explorer. Also test with the various hardware platforms that you anticipate.
A good pilot or beta program can help you flush out any difficulties resulting from the differences in equipment and software. Encourage your testers to go a little wild with their settings and get as many varied looks at your final product as you can.
You should also design your pages so that they appear reasonable on a large number of screens. Choose a standard aspect ratio and design for that. For example, you might choose 640´480 as your typical screen size. This is a reasonable setting if your application will be accessed by the general public, because it's the smallest of the ratios you need to consider.
If your application sends graphics-and what self-respecting Web page doesn't?-don't use graphics that span the full screen width. Remember, you also need to contend with scrollbars and the fact that your user might not run his or her browser on the full screen. A general rule of thumb is to keep graphics to 480 wide (about 75 percent of the screen width) at the most. Of course, if you're programming for standard, known equipment and software, you'll know a set number of screen sizes.
Another problem with large graphics is their transmission time. The old adage "a picture is worth a thousand words" applies here. In the English language 1,000 words is about 6,000 characters. At 14,400 baud, these words would take a little more than four seconds to transmit. If you substitute a graphic that is, say, 24,000 bytes, it could take about 17 seconds. This length of time can turn off some potential customers. You might want to consider the value of the graphic and, perhaps, reduce its size or substitute words.
Text paragraphs are relatively unaffected by the size of the screen. However, remember that HTML paragraphs wrap at the borders of the browser screen or the table. You have no control over that aspect of your application. Also, text positioned by graphics using the LEFT, RIGHT, and CENTER directives can appear different (or wrong) with some screen sizes. Be sure to check the graphics on different screens to make sure that your layout isn't affected.
One important aspect of writing for the Web is that information about total transaction between the client and host-the "conversation"-isn't maintained across parts of the conversation. In a client/server application across a dedicated network, a socket connection is established at the beginning of the conversation and continues until the work is completed. The client and host track the information (often in memory) while the connection is in progress, because they're dealing with a known entity at the other end of the socket connection the entire time.
This isn't the case for Web transactions. Socket connections are maintained only for the length of a single send/receive exchange (transaction). That is, when the client sends information to the server (say a URL) and the server responds with information (a Web page), a socket connection is established and then broken. Information regarding the transaction is not maintained for the next send/receive transaction unless you specifically program for it.
This process is a lot like having a conversation with someone with a very short memory. You say something to him and he responds, but the next time you say something to him, he doesn't remember your first exchange. You have to keep filling in the details from previous exchanges to keep your partner up to date. In addition to this problem, the host might be carrying on thousands of transactions with other clients simultaneously. The point to remember is that you have to carry all information about the conversation with you. A couple of methods are available.
First, you can hide information on the screen (page) sent to the client. HTML provides an input type for this-hidden. Hidden information doesn't appear on the page, but is returned like any other input field. You might want to hide sequence information or other identifying information that will be used by your application to retrieve data records. Hiding information on-screen is risky, especially if it's confidential. Most browsers support the capability to examine the source code for the page. Any user taking advantage of this feature can see your hidden information. You might want to encrypt sensitive hidden information.
An alternative is to save the conversation information at the server. Send a "key" to the client, either as a display element on your page or as hidden text. When the client returns the form, use the key to retrieve information about the conversation. This alternative is more secure, but has the disadvantage of leaving information on the server for transactions that aren't completed. For this reason, you might need to devise a cleanup routine that can run periodically to eliminate these incomplete transaction segments.
Some Web browsers implement information packets called cookies as a mechanism to store information about a host directory tree. Cookies can be used to store key information that can later be used to retrieve information stored on the host. See the later section called "Security" for details about cookies.
As mentioned, timing can be a problem on the Internet. You don't know from one time to the next whether completing the transaction will take several seconds or much, much longer. For this reason, timing-critical portions of your application should not be Internet-based.
Consider timing not only in terms of programs, but also in terms of the tolerance of human beings to timing issues. For example, you might not want to rely on the Internet for a customer service system where your customer service personnel are on the phone with disgruntled customers. The response time of the Internet is, at best, unreliable. A Web page can take one second to display one time and several minutes another time. You don't want your disgruntled customer hanging on the phone while your customer service personnel are waiting for the page in the later case.
If your Web browser doesn't receive a response from the Web server in a specified length of time, it will time out and notify you that the server is unavailable. Timeouts are difficult to manage in client/server applications across your own infrastructure; they're more difficult when you are dealing with the Internet. You must include code to determine that the transaction has failed and recover from this condition. Because of the unpredictability of transaction durations over the Internet, you can't reliably test the expected duration of a particular exchange. The question is, how much time is too much time? When can you determine that your application has failed?
The design of your application affects the way in which you determine timeouts. If your custom programs run each end of the client/server connection, you can control timeouts and recovery more precisely. If you are using commercial products for one or both ends of the connection, however, things are more difficult.
Commercial Web browsers have timeout settings built in. If your client is using one of these programs, it will time out after a length of time, but it will time out on the basis of the manufacturer's standards-not yours.
One problem you face related to timeouts is the use of the "Back" button and retransmission of the same transaction to the host. If your client is using a browser, you can't control this occurrence. The user can go back to your screen and resubmit it as many times as he wants. He really doesn't intend to submit multiple transactions; if he's impatient or doesn't receive a "reasonable" response, he just feels that the transaction has somehow failed and attempts to resubmit it.
You help prevent the problems caused by these multiple transactions in several ways. First, provide meaningful feedback to your client. Make sure that the screen you return contains enough meaningful information to assure the client that he has successfully completed the transaction. Also, give the client a button to take him somewhere, such as to your home page or to another logical page. This option gives him an alternative to the Back button and can go a long way to mitigating this problem. Some browsers now support page refresh generated by the server. Using this option can be effective for a long-running transaction, but it limits the choice of target browsers.
Also, you can serialize your forms by using the TYPE=HIDDEN parameter of the INPUT field type. As the server program receives a transaction, it records the serial number and prevents another transaction with the same serial number from being posted. If the client submits a second transaction with the same serial number, use a gentle reminder screen to tell him that you've already received and posted the original transaction.
Some protocols are unreliable. A major example of this is e-mail. E-mail is ubiquitous, and is thus an excellent choice for some types of applications where universal access to your customers, employees, and other resources is a consideration.
With very few exceptions, everyone who is on the Internet has e-mail. And through connections to other networks, the use of uucp (Unix-to-UNIX Copy), and interfaces to other mail systems such as corporate mail systems, you can reach even people who are not on the Internet.
There are many examples of the use of e-mail in applications:
But there is one major consideration in the use of e-mail. Because e-mail is a "store and forward" protocol, you aren't guaranteed delivery. Here's how it works. You send e-mail to a customer. The message is stored on your computer. The mail system examines the address and determines that it is not local. The message is then forwarded to another computer indicated as a mail forwarder in the local mail configuration. That machine repeats the process and passes on the message if it is not for its local mail system. The process continues from machine to machine until the message is delivered or some "fatal" error is encountered. This process can take seconds or days. In some instances, the mail cannot be delivered and it is returned to you.
Your application must be able to deal with this returned mail. First, it must be able to identify it, and then it must be able to do something with it. One consideration is that this mail can take several days to return to the system. Because handling this mail can be tricky, the most typical action is to forward the mail to some human's mailbox for him or her to deal with.
One problem can be a loop created in automated mailing lists when a message is returned to the list mailbox and interpreted as a new request, to which the original information is returned, which is then rejected and returned to the mailbox and interpreted again, and so on. You get the idea. This can be avoided by adding a return address that is not the address of the mailing list. For example, make the return address some human's mailbox and let that person deal with the complexities of this situation.
A program designed for a single computer or for use on a local area network (LAN) or dedicated wide area network (WAN) is guaranteed some specific set of resources (bandwidth, central processor usage, and so on), which results in reliable operation. With some certainty, in these situations, your application will operate much the same in terms of response time from day to day.
This is not necessarily the case with the Internet. Because there is no central control of the public Internet, it can be unreliable. Machines can be pulled out of service, networks can be reconfigured, addresses can be changed, and more, without notice. In addition, the number of people "surfing" the Net is increasing exponentially, causing delays and even failures of some parts of the Net. The time of day and day of the week can be a factor. Also, the use of automated programs such as "spiders," which search the Net in a much more intense way than humans, and the introduction of poorly designed programs that consume way too much network resources add to the situation.
How do you predict what the impact of Internet use will be on your application? Of course, the best way is to test a prototype of your application at all the times you expect it to be used. A wide area, public beta test can tell you something about timing and reliability, but predicting all the problems you will face is probably impossible. Short of this, here are some thoughts.
Make sure that your application is hosted on a machine that won't be overburdened. Also, make sure that the connection between the machine and the Internet is sufficiently fast to permit reasonable access and response times. For most commercial applications permitting public access, a T1 connection is recommended. Note, however, that T1 connections might be prohibitively expensive for many small businesses. In this case, you might want to consider renting space for your Web application on a machine at an Internet service provider (ISP) with adequate bandwidth to support your application. Depending on your area, you might also have access to ISDN phone lines. These can be a viable alternative to the faster T1 connections. However, even these can be expensive.
If you're placing part of your business on the Internet, designing an alternative to your Internet-based application can be critical. This factor can be especially important if the application is designed to secure sales for your business. When you place a sales application on the Internet, you place at least a part of your profits at risk of the unreliable nature of the transport medium. Here are a couple of considerations:
To avoid losing sales from these situations, design alternative methods for your customers and field staff to access information, place orders, or obtain customer service response. Here are some ideas:
In short, don't leave your customers with no way to place an order or get support except the Internet. Because you don't control the Internet resources, you can't guarantee delivery.
So when does your application decide that a particular transaction has failed? This depends a great deal on whether you control both ends of the transaction. Let's look at a typical situation.
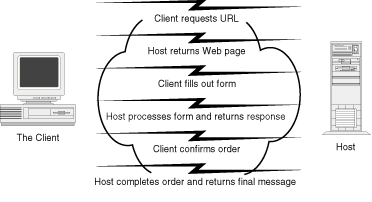
Figure 2.2 depicts a scenario in which you don't control the timeout at the client (browser) end. The browser will implement some timeout function and will usually return some standard error to your user, but how does the host determine that a transaction has failed? In addition, your host application might never respond to the customer. This can be for one of many reasons, including failure of your application, failure of the network, or an error on the part of your customer in operating his browser. To your customer, these errors all appear the same-as a failure of your application. Whatever the reason for the timeout, you need to deal with the consequences in your application. You do not want to compound the problem by sending the customer something he did not want. For this reason, you might want to implement some confirmation into your application as shown in Figure 2.2.
Figure 2.2 : Your host program with output to a Web browser.
In this example, your customer is ordering online. To make sure that the transaction has completed successfully, you might want to have one final confirmation after the order has been placed. That is, your customer fills out the order form and transmits it to the host. The host processes the order and sends a confirmation back to the client with total cost and a confirmation number. The client is required to confirm the order. When the host receives this confirmation, the transaction is complete and the customer is sent one final message.
This scenario will vary when you have custom programs at each end of the transaction or create a transaction using Java applets. However, the principle of confirming that a transaction was received still applies.
All systems need disaster recovery plans, but when you design a system for the Internet, the fact that you don't have control over most of the Internet's resources makes recovery more difficult. Disasters can range from simple power outages to parts of the Internet being out of service due to natural disasters such as floods, hurricanes, and so on. Your disaster recovery plan must deal with the fact that you might have no control over the recovery of Internet resources. Your application is completely dependent on some other organization, and while that organization is dealing with the problem, you can be out of business.
Of course, if your resources are the ones that are involved in the disaster, you need to have plans for an alternative infrastructure. Here are a couple of ideas for designing your application that can help when you lose all or part of your local infrastructure:
| NOTE |
Machine "nicknames" can also be a good technique to enable you to switch your application to a new machine or run it on multiple machines during standard operation. |
Security is a major issue with the Internet because it is public domain. The public nature of the Internet can cause security concerns that don't exist for private intranet or dial-up applications. Because packets pass through machines over which you have no control, someone can potentially see confidential information. Any hacker with a network datascope can get credit card numbers, Social Security numbers, and other confidential information from your transmissions. You need to design for these potential security leaks.
Your transactions have the potential to pass through many computers and other devices on their way between the client and the host. On most UNIX systems, you can issue the traceroute command to see this routing. Most of these machines are acting only as routers, but they're points where your signal can be intercepted and decoded. Here's a look at the number of "jumps" that it takes to get from my account on Netcom to another computer run by the Channel 1 BBS. (The command issued was traceroute user1.channel1.com.)
traceroute to user1.channel1.com (199.1.13.9), 30 hops max, 40 byte packets 1 netcomgw.netcom.com (192.100.81.254) 2 f0-0.netcomgw.netcom.net (163.179.1.1) 3 t3-1.scl-ca-gw3.netcom.net (163.179.220.194) 4 sl-mae-w-F0/0.sprintlink.net (198.32.136.11) 5 sl-stk-6-H3/0-T3.sprintlink.net (144.228.10.45) 6 sl-ana-2-H4/0-T3.sprintlink.net (144.228.10.26) 7 sl-ana-1-F0/0.sprintlink.net (144.228.70.1) 8 sl-fw-6-H2/0-T3.sprintlink.net (144.228.10.29) 9 sl-fw-3-F0/0.sprintlink.net (144.228.30.3) 10 sl-channel1-1-S0-T1.sprintlink.net (144.228.33.34) 11 user1.channel1.com (199.1.13.9)
Don't worry about the format of this display. The important point is not the details, but the fact that my information passed through ten devices other than the originating machine (not shown on this route printout) and the destination machine (user1.channel1.com). If you are at all concerned about security in your application, this situation should concern you.
Anyone with a scope on any of the devices through which your information passes can trap that information. Things like Social Security numbers (999-99-9999) and credit card numbers have patterns that can be detected by automated search programs. An unscrupulous person can place one of these programs on a device routing packets along the Internet, let it work for a period of time, and then take a leisurely look at the data that it traps.
E-mail can be even more vulnerable to this type of piracy, because mail travels as plain text in a format that's easy to read, and the full messages are stored and forwarded by post office machines. Although most of us don't like to look at them, and many mail readers filter them, mail headers can tell you a lot about the machines on which your mail rests. Take a look at a message header:
Received: from ns2.eds.com by mail5.netcom.com (8.6.12/Netcom)
id NAA01582; Wed, 24 Jan 1996 13:21:17 -0800
Received: by ns2.eds.com (hello)
id QAA07685; Wed, 24 Jan 1996 16:21:40 -0500
Received: by nnsp.eds.com (hello)
id QAA26247; Wed, 24 Jan 1996 16:19:58 -0500
Received: from target2.sssc.slg.eds.com by dsscsun1.dssc.slg.eds.com
(5.0/SMI-SVR4)
id AA00143; Wed, 24 Jan 1996 15:18:57 -0600
Received: from rfbpc (rfbpc.sssc.slg.eds.com [198.132.57.4])
by target2.sssc.slg.eds.com
Like the traceroute information presented earlier, the details of this heading information isn't important for this discussion. The important thing is the fact that this piece of mail rested on four machines not under our control. At each of these points, your message is simply part of a larger text file. Anyone with the proper security clearance (or anyone who can hack into that machine and obtain that clearance) can read your message. The headings are read from the bottom to the top:
Incidentally, the mail passed through several machines that aren't listed in this heading. Remember that traceroute? Mail packets have to pass through several machines on which they don't rest, making them vulnerable to snooping.
What does this mean to your application? If you're passing sensitive, private, or confidential information, consider encryption for your application.
Many types of encryption can be used to protect your transactions. Several Web browsers and hosts are "secure" in that they encrypt information passing between them. The extent to which you want to use encryption in your application will depend on the sensitivity of the information and the cost of encryption.
Of course, if you are writing your own application in which you
will provide both the client and server modules, you can provide
your own custom encryption schemes.
| CAUTION |
One caution about using encryption such as that used by products like Pretty Good Privacy. These schemes are controlled by the U.S. Federal Government, which has some restrictions against exporting encryption technology overseas. Be sure to check out this issue before committing your application to specific technology or standards. |
If you are designing an application that will be hosted by a Web server, consider placing the application on a secure Web server. These servers establish a secure connection with the client browser and encrypt all information that passes between them. The Netscape Commerce Server, for example, uses Secure Sockets Layer (SSL) to encrypt pages during transmission.
Even if you choose not to encrypt entire transmissions, never send an unencrypted password, Social Security number, credit card number, or other sensitive information over the Internet. This data can be encrypted easily by the host CGI interface program, even if you implement your program using a commercial Web hosting program. Implementing encryption at the client end of the application is more difficult if you don't rely on the encryption capabilities of the commercial server/client. Java or some other plug-in application needs to be used to encrypt the sensitive information prior to transmission.
If you are going to transmit documents over the Internet, such as word processing documents, you can use the capabilities of the applications that create the documents to encrypt or password-protect the documents. For example, both Microsoft Word for Windows and Microsoft Excel can provide file-sharing passwords that must be entered before a document can be accessed.
You might also want to use the capacity of compression programs such as PKZIP to password-protect files they have compressed. With this system, even if some hacker manages to intercept a file, she will have to work hard to read it.
Following are some thoughts about using passwords:
In the case of especially sensitive information, you can allow requests to come to your application via the public Internet. However, you might want to return the requested information via a secure medium. For example, you could allow customers to request information via the Internet and then use fax-back facilities to fax the information to their machines.
Another difficulty in dealing with connectionless protocols is that you might need to verify that the client you are talking to is the one you think it is. Luckily, some techniques are available, as described in the following sections.
Your application might accept socket connections only from "trusted" TCP/IP addresses. Web browsers send the name of the machine in the SERVER_NAME field and the address of the remote in the REMOTE_ADDRESS field. Be aware that these fields can be faked, but they can be used in combination with user IDs and passwords to provide additional security.
Your application might ask the client for a user ID and password. For applications with custom clients, the user ID can be programmed into the client before distribution and the user can be required to enter a specific password to verify her identity. In addition, you can limit user IDs to specific TCP/IP addresses and refuse to serve ID/address pairs that don't match.
If your application uses commercial browsers, you can take advantage of the capacity of some browsers-for example, Netscape or Microsoft's Internet Explorer-to store information on the client machine; that information can be returned to the server when a specific host path is requested.
CGI scripts can set data at the client's browser; this information is called a magic cookie. When a browser makes a request for a page, it sends its cookie (if it has one set) to the server along with the request. If this is the first time that this particular machine has been used to access your application, it will need to set default configurations or provide a form on which the customer can provide required information.
A magic cookie is made up of several parts:
| TIP |
Cookies can also be a convenient way to customize your application for a particular client; for example, when you are transmitting a page in a foreign language for international clients. Once a customer has visited your site, you can recognize the customer from his cookie, and automatically customize the page returned to him. |
Using this capability, you could transmit a user ID to the client and then retrieve it on subsequent visits by this client. You can match the returned cookie to security information entered by the human being on-screen as an additional security precaution.
When you place your application on the Internet, the potential audience for your application becomes an international one. You must consider the implications of this fact, especially if you are designing an application for public access.
Your audience might speak a different language and come from a different culture. Even if you program your application in English, if the application will be used by someone in another country, you will have some linguistic and cultural considerations. The title of this section is a good example. For anyone who has seen the movie The Wizard of Oz, the meaning of the phrase "I don't think we're in Kansas anymore" is evident. For those who have never seen the movie, the meaning is blurred. In this case, the heading means that you can't assume that the rest of the world operates by the same conventions that you do in your part of the world. Be careful and always consider that the Internet is an international medium, especially if you are expecting business from international clients.
English has become the international language of business, but
your application is likely to be visited by potential customers
who don't speak English or speak it as a second language. In designing
your pages, avoid idioms that are likely to be misunderstood by
foreign English speakers.
| NOTE |
Pages in a foreign language can be important if you are targeting your application to a specific country or culture. Be sure to use a standard form of the language and avoid idioms that can be confusing in a different country. |
| NOTE |
If you expect a large number of customers, you might want to provide alternative language versions of your pages. When you do, remember that some languages are more wordy than others to express the same thought. Here's an example from my wristwatch instructions: |
| English | Spanish |
| The alarm time is set on a 12-hour basis and indicated by the alarm hour and minute hands that move independently of the main time hands. | La hora de alarma se fija en la indicacin de 12 horas y es indicada por las manecillas de horario y minutero de alarma que se nueven independientemente de las manecillas de hora principal. |
These differences in the number of words required to express the same idea can affect formatting of your carefully designed screens. Be sure to account for this problem if you choose to support multiple languages.
Also, make sure that you have your pages translated by a professional
translator or, at the very least, a native speaker of the language.
Don't rely on automated translation programs. Often, the direct
word-for-word translations aren't accurate and will not be understood.
| TIP |
Remember the discussion of magic cookies in the "Security" section? Cookies can also be used to store language information. That way, when a customer returns to your pages, he is automatically routed to the correct language version. |
Languages vary by country. For example, the Spanish spoken in Mexico varies somewhat from the Spanish spoken in Spain. They use different words, tenses, and idioms to express the same thoughts. Spelling also differs from country to country, even in English. Meter and civilization in the USA are metre and civilisation in England. So what should you do?
When you are dealing with an international audience, you can't assume that they will have the same frame of reference as you do in your country. Even if they speak your language, they might not understand local references or idioms that might be common in your county-or even your part of the country.
Something else to consider is your use of graphics, icons, and colors. In Islamic cultures, it's inappropriate to depict human figures in certain ways, so be careful with your representations of the human form. In a number of cultures, the left hand symbolizes vulgar functions, so depicting a left hand on a button could be insulting. In some cultures, white is the color of mourning after death. The list goes on.
Be cognizant of and try to avoid these situations. Watch for them as you design your pages.
Always use the area code and perhaps include the country code for all phone numbers. Also, don't assume that the visitor knows where you are located. Always include the full address for your company if you choose to give it. Include the country. It's arrogant to assume that all your visitors will know which country you are in by the use of a state or province.
Even things as simple as the address and phone number differ from country to country. If you will be capturing this information in your application, you need to provide forms with fields that will accommodate the differences.
Also consider edits. For example, U.S. ZIP codes are all numeric, but, if you edit for this, your customers in Canada will not be able to enter their postal codes, which include letters.
On the Internet, you are addressing an international audience. Remember that numbers and dates aren't formatted the same way in all cultures. For example, 11/12/96 is November 11, 1996, in the United States and December 11, 1996 in many countries of Europe. To avoid confusion, format dates as "dd-mon-yy," for example, 11-Dec-96.
Most countries support a.m. for times before noon and p.m. for times after noon. However, you might want to use a 24-hour time reference just to be safe. Thus, 1:30 in the afternoon could be displayed as 1:30 p.m. (13:30) or just 13:30.
Numbers also have different formats in different countries. In the U.S., one million is 1,000,000.00, while in Spain it's 1.000.000,00. But digits aren't the only problem. One billion in the United States is one-thousand million (1,000,000,000), while one billion in England is one million million (1,000,000,000,000). So you have to be careful even if you use the words and not the numbers.
And speaking of numbers, your prices are important. If you are quoting prices, be sure that your audience knows what currency you are using. For example, both Canada and the United States use the dollar, but $50.00 (Canadian) is less than $50.00 (US). Be sure to specify that amounts be sent in the currency that you want.
The Internet has expanded the concept of the 24-hour/7-day application. When you write an application for the Internet, you need to be aware that while you are sleeping in the U.S., someone in Spain is starting their workday and people in Australia are already worried about tomorrow. If you're going to serve an international audience, the day really starts by convention at the International Dateline, not in your particular time zone.
This consideration can be especially crucial for applications that have to do things for the customer based on time of day, or that rely on information from other processes that run periodically (typically mainframe batch processing cycles). In the latter case, the question to answer is this: Can your application be unavailable during the period when the information is being processed?
To illustrate the former situation, let's look at a small application that will mail reminders daily to customers. You'd like to have these reminders arrive in their mailboxes for the start of the workday, so you decide to send them out at midnight-but midnight where?
Assume that you're in the U.S. Pacific time zone, say in California. That's -8 hours from Greenwich Mean Time (GMT). By the time it's midnight in California, it's 11 a.m. the next day in Australia. If you send out the notices at midnight California time, you will certainly miss the notice to your customers down under.
The answer, of course, is to keep time zone information with the messages. Then arrange your programs to execute once per hour and process the messages for the appropriate time zone. Thus, you would process those messages for Australia at about 1 p.m. the previous day, Pacific Time, so that they arrive in Australia in time for the start of the correct business day.
Given the discussions in this chapter, you might be discouraged about writing your application for the Internet. Designing an application for the Internet does add challenges to the basic client/server application, but none are insurmountable.
New solutions are coming to the market every day. Design your application for the Internet from the start. Rely on solid programming design methodologies and practices. Be aware of the pitfalls and provide solutions for them, and test your application thoroughly under all conditions. If you do this, you will create a successful application and join the thousands who are taking advantage of this marvelous medium.
This chapter covered issues related to writing an application for the Internet. You learned that you do not have control over the infrastructure and resources upon which your application will depend. You saw techniques that can be used in your application to deal with problems of the unreliable nature of the Internet, security and confidentiality issues, and the international nature of the Internet.