{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Mike Ellsworth
You can use MIME (Multipurpose Internet Mail Extensions) to set up your server to deliver multimedia features such as audio and video via CGI scripts. MIME is an important part of the conversation between a Web browser and a server during which the capabilities of the browser to handle different media types is revealed.
In this chapter, you learn about
For your reference, I list the MIME types approved by the Internet Assigned Numbers Authority (IANA), as well as unapproved types supported by popular servers and browsers in Appendix B, "Commonly Used MIME Media Types." I also provide several CGI script fragments that you can use to code your own MIME headers.
MIME is a technical specification, originally developed for Internet mail, that is used to define the type of content a Web server sends a browser, and what the browser can accept. MIME isn't rocket science, but is more like high school science: If you can understand a few basic concepts and follow directions, you can pass the course. However, if you're truly into it, you can proceed to graduate-level usage, involving content-negotiation between server and browser.
In fact, you're already an expert in using MIME. You've used MIME without knowing it since the first time you browsed the Web. It's the underlying mechanism that enables a browser to know what a Web server is sending it, and how to handle it.
MIME is often erroneously defined as an acronym for Multimedia Internet Mail Extensions. This is an understandable mistake, since MIME on the World Wide Web is often used for multimedia applications. However, MIME really stands for Multipurpose Internet Mail Extensions, which is significantly different. Not all MIME types deal with non-text media types, as you'll see later in this chapter.
What, you ask, does a mail standard have to do with the Web? Certainly, HTML documents bear little resemblance to e-mail. How is it that an e-mail standard was incorporated into the HTTP specification?
To get the answer to these questions, first look at the origin
of the MIME standard in Request For Comments (RFC) 1341, which
was written back in the dark ages-1992. For your convenience,
the RFC is included on the CD-ROM that accompanies this book.
| NOTE |
RFCs are working notes of the Internet research and development community that often have the force of standards on the Internet. They may concern any aspect of computer communications and may represent anything from meeting notes, to Frequently Asked Questions (FAQs), to a proposed specification for a standard. Unless specified otherwise, RFCs are considered to be public domain. While most Internet standards are RFCs, not all RFCs specify standards. Because the Internet runs on rough consensus and working code, whether an RFC is adopted widely depends a lot on how well it works in practice |
The Internet standard for e-mail was established by RFC 822 (included on the CD), released in 1982. This standard proposed a way for machines to exchange mail documents that were almost exclusively text. Because so many different e-mail systems needed to interoperate, each with different addressing schemes and transmission methods, the RFC established a lowest common denominator for mail interchange.
In June 1992, Network Working Group members Nathaniel S. Borenstein and Ned Freed published RFC 1341 (included on the CD). In it they defined a method for e-mail to contain not only non-textual components such as audio, video, or graphics files, but alternate text formats such as PostScript or Standard Generalized Markup Language (SGML).
Because Internet mail gateways are notoriously finicky about non-text mail, MIME represents a significant extension to the capability of e-mail to transfer information. Before MIME, the only way to include audio, video, or other binary files in e-mail was to first run the file through a program to UUEncode it, or convert the binary file to an ASCII (text) representation. You could then include the ASCII code in your e-mail and send it. Your recipient had to reverse the process (UUDecode) on receipt.
RFC 1341 proposed a way to automatically encode with mail software material that wasn't compliant with the original RFC 822 standard. It also proposed a way to include more than one attachment (known as multipart ttachments), possibly with more than one type of encoding. Because the sending and receiving mail software had to know what kind of file it was dealing with, the RFC established several standard MIME types and subtypes. The seven MIME types defined by the RFC are as follows:
Each type is defined further in the section "What Are the Standard MIME Types?"
The authors of RFC 1341 intended these types to be exhaustive, and discouraged adding to them. They also intended that subtypes be used to provide support for various implementations of a type-for example, different types of text. To illustrate this usage and to provide a common starting point, they defined several subtypes for each type. The type and subtype are combined with a slash and serve to describe the object. The combination of a type and subtype is commonly referred to as a media type. For example, text/plain, video/quicktime, audio/basic, and application/sgml are all valid MIME media type/subtype combinations.
The inclusion of the SGML subtype is important historically because, as you may know, HTML is an implementation within the SGML standard. (Many would argue this point, but it's clear that was the intention of the authors of the HTML standard.) Because the MIME standard supported SGML as well as many other media types people wanted to deliver over the Web, MIME was a natural inclusion in the HTML and HTTP standards developed by Tim Berners-Lee, Dan Connolly, and the group at CERN.
The effort that lead to the World Wide Web began two years before the MIME standard was issued, in 1990. By October 1992, four months after the proposed MIME specification in RFC 1341, Connolly's thoughts were turning toward a convergence of MIME and SGML that not only could form the basis of the World Wide Web, but also could create a platform for other services such as Gopher and WAIS. In a posting to an e-mail discussion list (http://www.eit.com/goodies/lists/www.lists/www-talk.1992/0215.html), he proposed just such a thing, and Borenstein enthusiastically agreed. Connolly asserted that MIME was a good standard for identifying content types in general, not just for e-mail.
The rest, as they say, is history. MIME was adopted into the HTML 2.0 standard and formed an important mechanism by which the Web client and the Web server understand each other's capabilities.
MIME is the primary way a Web server tells a Web client about the document or file it's sending. The Web browser also communicates information about its capabilities to the server using MIME types. There's more on this topic later in the sections "Mapping MIME Types to Browser Helper Applications" and "Configuring a Server to Recognize MIME Types."
Any file received without a MIME header is generally assumed by the Web browser to be an HTML text document (MIME type text/html). This can lead to distressing results-generally, a string of sentences undisturbed by tabs or paragraph marks. If, on the other hand, a text document is preceded by a MIME header declaring it as text/plain, it's much easier to read. Such documents are displayed without formatting controls such as fonts and heading styles but with paragraph breaks and tabs. Many such documents are on the Web, ranging from converted e-mail messages to RFCs and other Internet standards documents.
All that's necessary for you to do to make a plain text document display nicely, albeit plainly, in a Web browser is to append a MIME header to the top that declares it as the MIME type text/plain. There's more on this in the next section.
Although any document received without a MIME header is assumed to be text/html by most browsers, to be certain your Web browser displays a Web page as an HTML document, the Web server must identify the document as type text/html by first sending the client a MIME header. (Interestingly, text/html isn't one of the official media types registered with the IANA. Go figure.)
By the same token, the only way to make sure that any other media type will have a chance of being displayed or handled properly is to inform the browser of its type by using a MIME header. Thus, MIME allows browsers to distinguish audio clips from video clips from VRML worlds from HTML pages. Being able to understand and manipulate this key metadata will equip you to fully exploit the multimedia potential of the World Wide Web.
So what's this thing called a MIME header, and how do you use it? The answer depends on whether you're using e-mail or the Web. First, look at the full MIME specification, which applies to e-mail. The next section describes the elements of the MIME spec that are used on the Web.
As defined in RFC 1341 and subsequently revised in RFC 1521 (included on the CD), a MIME header consists of the following parts:
Keep in mind that these are the requirements for e-mail headers. As you'll see in the next section, using MIME headers for HTTP transfers can be much simpler.
The following example demonstrates a typical MIME header for e-mail:
Mime-Version: 1.0 Content-Type: multipart/mixed; boundary="IMA.Boundary.750407228" --IMA.Boundary.750407228 Content-Type: text/plain; charset=US-ASCII Content-Transfer-Encoding: 7bit Content-Description: cc:Mail note part
In this header, the MIME version is declared as 1.0, and the content type is multipart/mixed, meaning the document contains more than one type separated by a boundary, the boundary being an arbitrary text string. Each content type is then declared after each boundary. In this case, the content after the first boundary is text/plain. The content transfer encoding for the first part of the message is the standard Internet mail 7 bit. The content description can be used by the client to determine either a file name to use to store the section or other information.
All this may be more than you need if all you want to do is use MIME on the Web. Most Web clients don't require all the detailed information expected by e-mail clients. Web browsers have the advantage of being able to communicate their capability to handle MIME types to the server ahead of time. Let's look at the minimum MIME header requirements for Web usage.
Every time you access a Web page, a dialog occurs between your browser and the Web server. As part of the request for the page, your browser sends a description of the MIME types it understands. It may, for example, tell the server that in addition to the standard text/html, it can understand image/gif and audio/basic. Most servers do nothing with this information, as you'll see later in the section "Content Negotiation Based on MIME."
However, it's possible for a server to give you back a different document based on what your browser says it can handle. Say that the server has two versions of the page you request: a standard HTML version and a PostScript file. By doing some CGI programming on the server, you can make the server send the PostScript version to those browsers that can accept PostScript, and the HTML version to PostScript-challenged browsers. Of course, this assumes that the document in question is served by a Web server that does something with the MIME information sent to it by the client. For a look at reality, see the section "Content Negotiation Based on MIME" later in this chapter.
But how does your browser know which document is coming down the communications pipe? By reading the MIME header, that's how. Every file a Web server sends to a browser begins with a line announcing the content type. For a Web page, the line looks like this:
Content-type: text/html
| CAUTION |
Don't forget to include a blank line following any MIME header information you send from a server to a browser. If you fail to do this, your header is ignored, and the header text appears at the beginning of the Web document |
| NOTE |
If you try to make your CGI script send text of any kind to the browser, and you forget to first send a MIME header, the server will report a 500 error. You'll tear your hair out trying to find a problem with the script, which will run just fine in a Telnet debugging session, but fail when you use a browser. Have your script send a MIME header, and the problem disappears |
When a Web server sends a GIF image, it sends a header such as the following:
Content-type: image/gif Content-transfer-encoding: BINARY
The content transfer encoding indicates to the browser that binary data follows. The header, as always, must be followed by a blank line.
As long as you stay with the traditional MIME content type/subtypes of text/html, image/gif, and image/jpeg, life is good. Virtually all browsers understand these types and can render them without the assistance of helper applications. But what if you have some PostScript files or Microsoft Word files that you'd like to make available to your users through your Web server? If you just make up new content types to fit your whim-text/postscript, for example-your users will at best be presented with a browser dialog box asking if they want to save the file, and at worst be staring at garbage binary data rendered in their browser.
Use of other content types requires coordination between what you say you're sending and what the browser knows it can handle. In the following section, I discuss the standard MIME types. Refer to Appendix B, "Commonly Used MIME Media Types," for a pretty exhaustive list of the officially sanctioned content types as well as commonly accepted non-standard content types. Later in the section "Mapping MIME Types to Browser Helper Applications," I discuss mapping content types to browser helper applications.
As a result of RFC 1521, which updated the original MIME specification, the IANA was established as the certifying authority for new MIME media types. It was the expressed intention of the original RFC that the number of MIME types be limited to the seven proposed in the RFC, as follows:
Each MIME type has a variety of subtypes, and, in practice, you almost never use a type without a corresponding subtype. One exception is NCSA Mosaic's support for the "telnet" type with no subtype.
In addition to the 12 content type/subtype pairs proposed in RFC 1521, the IANA has recognized an additional 45 pairs. With the Internet being a functioning anarchy, other types have become popular, if not sanctioned, by being incorporated into popular servers and browsers.
The RFCs state that local type definitions are allowed, but that they should be prefixed with x- to distinguish experimental from recognized standards. It's possible for such standards to gain support from major browser and server developers and thus become de facto standards. Examples of widely supported x- media types include video/x-msvideo and application/x-rtf (which makes little sense, given the existence of application/rtf).
Refer to Appendix B, "Commonly Used MIME Media Types," for a list of recognized and generally accepted MIME media types.
The RFCs defined several MIME media types and subtypes, and the IANA has registered many more. But what if the type you want to use-MacroMedia's Shockwave, for example-is neither registered nor in common use? Before you consider adding a new type to your server, you should first see whether an existing type can serve your purpose. You can do this by checking out the tables listed in Appendix B, "Commonly Used MIME Media Types," or by visiting the anonymous FTP site ftp://ftp.isi.edu/in-notes/iana/assignments/media-types, which lists all official types. The MIME media types accepted by the IANA as of early 1996 also appear on the CD-ROM that accompanies this book.
Say that no existing types fit your application. You have a couple of choices: defining and using your own type without registration, or registering the new type with IANA.
If you're sure that you can control both sides of the equation (what your server says and what your users' browsers support), you can create your own MIME type. I did this for a report delivery service my company developed. All the users were using browsers preconfigured by my company's staff, and so I could make up new types with impunity. However, to my chagrin, I found out that not only were some of these types already defined under slightly different names (for example, application/msword), but I was breaking Internet tradition by not naming my types with the prefix x-. Now I'm stuck supporting my hastily conceived MIME types.
Creating your own MIME type involves configuring your server to
recognize the type, and making sure that your users' browsers
are configured with a helper application (or plug-in, for newer
browsers) that can deal with the type. There's more information
on this process later in the sections "Mapping MIME Types
to Browser Helper Applications" and "Configuring a Server
to Recognize MIME Types."
| NOTE |
If you operate a Web site that's visited by the general public, to prevent problems you shouldn't arbitrarily create your own MIME types, no matter how tempting it is. Either adapt an existing type, or submit your new type to IANA for approval |
The best thing to do if you want a broad range of browsers and servers to support your new MIME type is to register the type with IANA. While the process looks quite easy, in practice you must be prepared to argue in favor of the new type with a variety of often opinionated people on the Internet Engineering Task Force's ietf-types mailing list, which was established for discussion of new types.
Submitting your new type for registration is the right thing to do for a couple of reasons. First, it's the only way you have a chance for the major browsers to support your type. If the type is unregistered, it's less likely that browser and server developers will support it. Unless you want upset users complaining to you that your server sent them garbage, this is an important consideration.
Second, chances are good that you're not the only person in the world who wants to use the proposed type. And I'm sure you want the world to experience the brilliance of your new MIME type!
The RFCs specify the process for adding content types. The following is adapted from RFC 1590 (available on the CD and at http://ds.internic.net/rfc/rfc1590.txt):
The media type registrations are posted in the anonymous FTP directory ftp.isi.edu/in-notes/iana/assignments/media-types. Media types are listed in the periodically issued "Assigned Numbers" RFC.
Be prepared to offer the following two pieces of information about your proposed MIME type:
When registering a new type, keep in mind the following:
If this looks like a daunting process, well, it can be. The ietf-types community is aware of and concerned with the proliferation of MIME types. They're perfectly willing to allow dozens of x- types to exist, and are equally willing to limit the number of officially blessed media types.
Nonetheless, registration is really the only way you can hope to have wide adoption of your new media type. And without browser support, it will be hard, if not impossible, to have the type accepted.
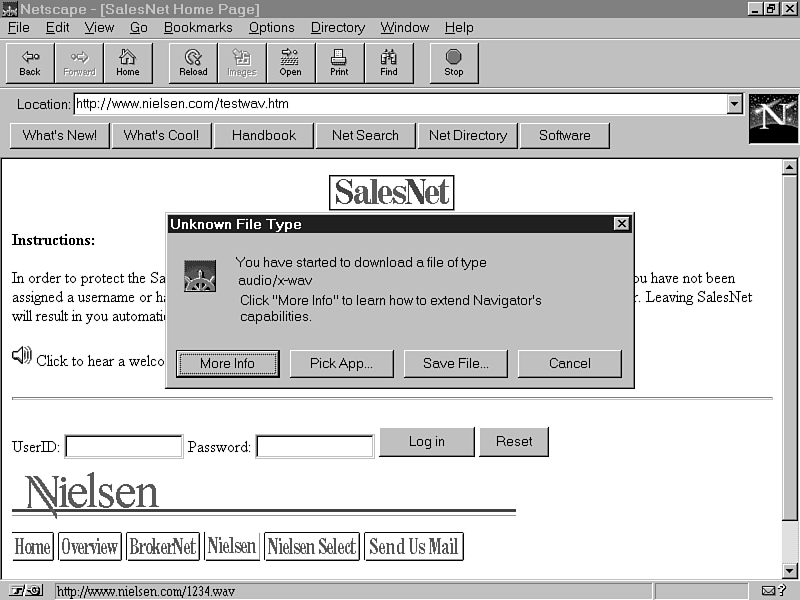
It's probably happened to you before-you click a cool link, and Netscape presents you with a dialog box similar to the one shown in figure 10.1.
The problem: Your browser doesn't recognize the MIME type the server says it wants to send you. The server has sent a MIME header-in this case, Content-type: audio/x-wav-that isn't supported by the built-in capabilities of your browser. The typical way such MIME types are supported is by obtaining an application to play or display the type and configuring your browser to start this helper application when it sees that particular MIME type.
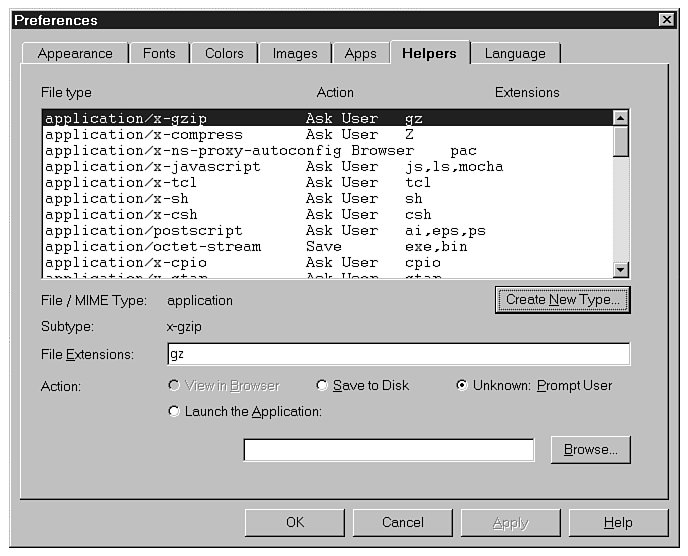
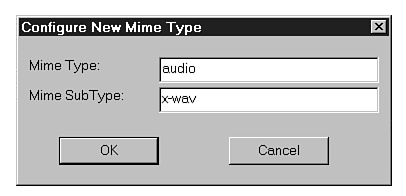
In this example, if you have a Windows PC with a sound card, you can configure the MPLAYER.EXE application to play the .WAV sound for you. To do this with Netscape 2.0, use the following procedure (see your browser's manual for information on other Web browsers):
Figure 10.2 : Use the Helpers page in the Preferences dialog box to configure
Figure 10.3 : Use the Configure New Mime Type dialog box in Netscape to create a new MIME type.
If you have a UNIX-based browser, chances are that it supports the mailcap standard proposed in RFC 1524 (which you can find on the book's CD-ROM). The process of configuring a MIME type is similar to that described earlier. Refer to your browser's documentation for instructions on configuring MIME types, or refer to the text of the RFC. You can also check out sample mailcap files on Web sites such as http://www.informatik.uni-bremen.de/docs_mosaic/mailcap.html or http://www.eecs.nwu.edu/~jmyers/.mailcap.
If you're using Mac Mosaic or another browser, refer to your browser's documentation to configure a MIME media type. The process is similar to that described earlier.
So you've added the appropriate MIME type to your browser and it works fine on someone else's site. Now you've added a cool .WAV file to a page on your site. But when you click it, Netscape complains about a completely different MIME type, something like application/x-httpd-cgi, or perhaps application/octet-stream. What gives? What happened to audio/x-wav?
The problem here is that you can't arbitrarily add files with new MIME types to your site and expect your server software to recognize them. Your Web server must be configured to recognize all the MIME types you want to use. Unless you specifically tell it otherwise by means of a CGI script, a Web server generally assigns MIME types based on the file-name extension (the characters following the dot) or last few characters of the name of the file in question. If the server doesn't recognize a file, it assigns a default MIME type, generally based on whether the file appears to be ASCII (application/text) or binary (application/octet-stream), or whether it's the result of a CGI script (application/x-httpd-cgi).
It's easy to add new MIME type support to your Web server if you have access to your server's configuration files, and if you can take the server down and start it back up. If you don't have such access, it can be an exercise in social engineering-you must convince your site manager to add the type for you. Depending on his or her mood, you may be forced to grovel a little first. Be prepared to give reasons why you can't live without this support.
If you have access to the Web server, adding your new MIME type is usually a matter of editing one or more configuration files. I provide instructions for two popular UNIX servers, the NCSA and the W3/CERN, in the next sections. See your server documentation for instructions on adding a MIME type to other Web servers.
The NCSA server-and derivative servers such as Apache-references several configuration files that control its operation. These files are usually located in a directory called conf under the directory that contains the httpd, or server daemon, file. You can add a MIME type to this server in one of two ways: by editing the server resources map, srm.conf, or by editing the mime.types file. To avoid problems if you ever reinstall the server (and thus accidentally overwrite mime.types), the preferred method is to edit srm.conf.
Use the following procedure to set up a new MIME type in the server resources map file for the NCSA server:
| TIP |
If you want to have HTML files on your site that don't end in the traditional .html extension, edit srm.conf and add the line AddType text/html newextension, where newextension is the file ending you want the server to recognize as HTML. For example, to make your server recognize files ending in .htm as HTML documents, add the following line to srm.conf: AddType text/html ht |
| CAUTION |
Make sure that the server resources map file is saved as plain ASCII text. This is especially important if you download the file to a PC for editing and then transfer it back up. The NCSA server is very finicky about the file format, and if you transfer a PC-edited file as binary, your server won't work correctly |
Suppose that you want to add the media type audio/x-wav to your NCSA server's configuration. Your existing configuration file looks, in part, like the following:
AddType text/html htm AddType application/x-msexcel xls
To add the .WAV type, insert the following line:
AddType audio/x-wav wav WAV
After you restart the server, any files the server delivers that have the names ending in wav or WAV are identified as audio/x-wav. Also, any CGI scripts you create that reference this type will be understood by the server.
The W3, or CERN server, and derivative servers use a single configuration file that controls their operation. This file can be located anywhere on the server. If the file isn't /etc/httpd.conf, you must start the server with a parameter indicating the file's name and location. This can make it difficult to locate the file. See http://www.w3.org/pub/WWW/Daemon/User/Installation/Installation.html for more information.
The best way to find the proper configuration file is to use the command ps -ax | grep httpd (or ps -ef | grep httpd for System V-based systems such as Solaris). This finds all instances of the server daemon, usually httpd or some variation, now running on the UNIX machine. (If you've renamed your server something else, grep for that name instead.) This command prints the command line used to start the server. Look for the parameter -r. On BSD-style UNIX systems, the command output looks like this:
%: ps -ax | grep httpd 128 ? IW 0:19 httpd -r /web/program/webstart.conf %: ps 128 PID TT STAT TIME COMMAND 128 ? IW 0:19 httpd -r /web/program/webstart.conf
What follows is the location and name of the configuration file. If you can't see the entire line, try running ps processnumber, where processnumber is the number of the process.
After you locate the server file, follow these steps to add the MIME type:
| TIP |
If you're using the W3 (CERN) server and you want to have HTML files on your site that don't end in the traditional .html, add the line AddType .newextension text/html ascii, where newextension is the file ending you want the server to recognize as HTML. For example, to make your server recognize files ending in .htm as HTML documents, add the following line to your configuration file: AddType .htm text/html asci |
Now add the media type audio/x-wav to the W3 server's configuration. The existing configuration file looks, in part, like the following:
AddType .xls application/x-msexcel binary AddType .avi video/msvideo binary
To add the .wav type, insert the following line:
AddType .wav audio/x-wav binary
After you restart or HUP the server, any files the server delivers that have the .wav extension are identified as audio/x-wav. Also, any CGI scripts you create that reference this type will be understood by the server.
As you can see, adding a new MIME media type to the browser and the server is a simple process. The browser and the server can now understand each other's capabilities. However, before you use a helper application with any MIME object, you need to be aware of the security implications.
The Internet is a wild and woolly place. As the old saw goes, on the Internet, nobody knows you're a dog. Or a hacker. Because you don't always (or even usually) know who the person is behind that cool Web server you've accessed, you need to be very careful when defining new MIME types for your browser to accept. Even seemingly innocuous media types such as application/postscript or application/msword can potentially wreak havoc on your system.
The danger lies in the concept of the helper application. Usually, such applications are merely tools to display or play files. One might play an audio file; another might display a video movie. It's hard to imagine these media types damaging an unsuspecting client system.
However, when you define a helper application that's a more full-featured program-perhaps one with its own scripting language, such as Microsoft Word or Excel-you're opening yourself up to a lot of potential damage. Word, just as an example, allows a macro to delete files and directories. The recent Word Prank (also known as Concept) virus is a good demonstration of the security problems inherent in distributing Word documents. If you haven't run into this nasty little critter yet, chances are good that you will.
The Prank virus is based in a Word macro. It infects the default document template, NORMAL.DOT, and every subsequent document you open. It does so by installing several macros, one of which is an auto-open, or self-running, macro that runs each time you open a Word document. Fortunately, the Prank virus is benign. All it does is display a dialog box each time you open a document. Prank was probably created simply to prove a point. And the point is clear: Defining programs with powerful scripting capabilities as helper applications is a risky business.
In the specific case of the Prank virus, you can inoculate your Word installation using files available on the Microsoft Web site.
Where possible, the best solution is to use viewers with limited features, such as the Word viewer available from Microsoft, when dealing with documents of unknown origin. Where this isn't possible, you need to practice safecomputing: Don't load strange programs or display strange files on your computer.
Netscape and other browsers allow you to configure a MIME media type in order to have the browser prompt the user each time that type is downloaded. The user can then decide whether he wants to start a helper application to display or play the file.
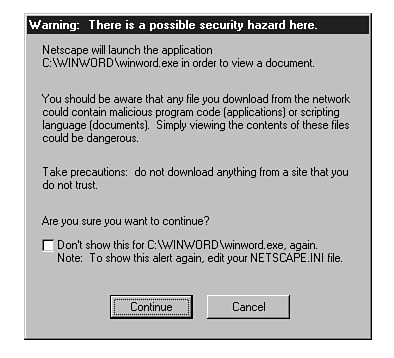
Because of security issues, major browsers such as Netscape display warnings when a known type with a potential for security issues is downloaded. Such a message is displayed in figure 10.5.
This warning can be disabled, however, and probably will be by most users due to the inconvenience of having to approve each download.
A more subtle threat is posed by PostScript. Although many people don't know it, PostScript is a full-featured programming language, not just a page description language. Many of its operators allow access to disks and other system resources. To quote RFC 1521,
The execution of general-purpose PostScript interpreters entails serious security risks, and implementors are discouraged from simply sending PostScript email bodies to "off-the-shelf" interpreters.
Various specific features of the PostScript language are considered security risks, such as the setsystemparams, setdevparams, deletefile, renamefile, and filenameforall operators, as well as facilities for exiting the normal interpreter, or server, loop such as the exitserver and startjob operators.
One of the most popular helper applications for viewing PostScript files is Ghostscript (available in two versions: GNU, from ftp://ftp.cs.wisc.edu/ghost/gnu, and Aladdin, from ftp://ftp.cs.wisc.edu/ghost/aladdin). Since GNU version 2.6.1, Ghostscript runs in secure mode by default, meaning that it doesn't allow potentially harmful actions.
If you or your users want to view PostScript documents, be sure to run the latest version of Ghostscript and its companion viewers, Ghostview and GSview.
For a couple of basic reasons, there are security concerns regarding MIME media types. By enabling a helper application, you're no longer passively browsing the Web. You're instead taking code of various types and running it or playing it by using your computer's processor. This isn't dangerous in and of itself. You run code from other sources each time you buy a commercial software package. There's a big difference between commercial code and code from the Internet, however. You have reason to trust commercial software developers. Code you run off the Internet usually comes from an unknown, essentially untrusted, source.
To trust the code, you must be able to trust the originator of the code, and the first step toward that trust is making sure that the originator is who he says he is. The concepts of a digital signature and digital certification have been proposed to help solve this problem.
Various authentication and security schemes have been proposed and implemented on the Internet. For example, a major proposed e-mail standard, Internet Privacy-Enhanced Mail protocols (PEM), is described in RFCs 1421-1424 (available on the CD-ROM that comes with this book). Most security discussions have centered on securing the data stream between point A and point B, and on the ability to ensure that the sender of a message is who he says he is. Less widely discussed are the security problems inherent in MIME. One proposed standard that's closely related to MIME has been proposed by RSA Data Security, Inc., creators of the popular RSA public-key encryption scheme.
RSA's Secure MIME (S/MIME) standard is intended, like MIME before it, primarily for use in e-mail. RSA proposes a "digital envelope" technology that could be used to contain e-mail. According to RSA's documents (at http://www.rsa.com/rsa/S-MIME/smimeqa.htm), this methodology uses a symmetric cipher utilizing DES, Triple-DES, or RC2 for message encryption, and a public-key algorithm is used for key exchange and digital signatures.
As far back as 1991, RSA proposed a set of Public-Key Cryptography Standards (PKCS) dealing with various aspects of security. PKCS #7 deals with secure message bodies, and PKCS #10 is a message syntax for certification requests. They proposed two MIME types, application/x-pkcs7-mime, which specifies that a MIME body part has been cryptographically encoded, and application/x-pkcs10 for use in submitting a certification request.
If S/MIME becomes an Internet standard, and it's not at all clear that it will, it seems reasonable to assume that aspects of it will, like MIME itself, become part of the World Wide Web. However, many major software vendors have expressed support for S/MIME, including Microsoft, Lotus, Banyan, VeriSign, ConnectSoft, QUALCOMM, Frontier Technologies, Network Computing Devices, FTP Software, Wollongong, and SecureWare.
The digital certification technology in particular would be useful in resolving some of the security concerns embodied by the use of MIME. According to an RSA white paper,
Digital certification is an application in which a certification authority "signs" a special message m containing the name of some user, say "Alice," and her public key in such a way that anyone can "verify" that the message was signed by no one other than the certification authority and thereby develop trust in Alice's public key.
If you can trust that whoever is sending you a MIME object is
who he says he is, you can better assess the potential danger
of running or playing that object. Obviously the infrastructure
necessary for massive digital certification on the Internet has
yet to be built, and the trusted entities who will do the certifying
have yet to be identified. So for the time being, be careful out
there!
| NOTE |
If you're interested in the S/MIME standard, you can join the S/MIME Developer's List by sending e-mail to smime-dev-request@rsa.com. Include your company, product, and contact information in the body |
Another secure MIME standard was proposed in October 1995 in RFC 1847 (available on the CD). Two MIME media types were defined: multipart/signed and multipart/encrypted.
The multipart/signed media type defines a method for normal ASCII text to be digitally signed so that the receiver can verify that it originated with the sender and wasn't altered in transmission. The message text can be read in the clear. The RFC defines the format of control information used by the receiver to verify the signature.
The multipart/encrypted media type defines a method for encrypting a message so that it can't be read in the clear. The message is coded as application/octet-stream, and control information specifies how the receiver can decode the message.
It remains to be seen whether these new MIME media types are incorporated into the Web, but it's likely that if a secure e-mail standard emerges, it will be adapted for use by the Web.
As discussed earlier in this chapter, each time your browser requests a document from a Web server, it sends a message to the server informing it of the MIME types it understands. This allows you to do some fancy CGI scripting and deliver alternative versions of MIME objects to your users.
The designers of the HTML standard envisioned a heterogeneous Web in which servers and browsers would interact to decide which of several alternate versions of a document best fits the needs of the user. They imagined that an information provider would produce documents in multiple versions-for example, plain text, HTML, PostScript, SGML, LaTex, and so on. Or perhaps the document is available in alternative languages-English, French, German, and so on. By having many alternatives, and by receiving information from the browser of the accepted and desired types of documents, the server can decide which alternative is the best fit and send that. Thus, a client is much more likely to get a satisfactory result.
If you've used Lynx, the character-mode Web browser developed at the University of Kansas (http://kuhttp.cc.ukans.edu/about_lynx/about_lynx.html), you're well aware that we no longer live in a text-only environment. If you don't have a graphics-capable browser, your world is full of [IMAGE] tags and image maps you can't use. It was supposed to be different.
As presented in the specification document available on the CD and at http://www.w3.org/pub/WWW/Protocols/HTTP/Negotiation.html, content negotiation is enabled by the following three parameters that would be communicated by the browser to the server:
To see how these factors can interact, suppose that for a Web project you're doing you want to find a video (public domain, of course) of a nice spring day in a forest. You probably have specific parameters in mind-it should be in QuickTime, although you can accept Microsoft Video and perhaps a few other formats, and it must be under 5M, because most of your users use modems. For an MS Video file, you can accept up to 7M because you've got this dandy magic box converter that reduces the size of the file while converting it to QuickTime. Further, since you're pressed for time, you don't want to spend a lot of time viewing clips on bogged-down servers.
You can translate these requirements into a GET statement by using the Accept field. This field has two parts, as follows:
Among the optional parameters are the q, mxs, and mxb keywords. So the request for the forest video might look like this:
GET /somevideo HTTP/1.0 Accept: video/quicktime; q=.9, mxb = 5242880, mxs = 30, video/x-msvideo; q=.1 mxb = 7864320, mxs = 30
Rather than simply request the object somevideo and take your chances that it fits your requirements, append an Accept field to the request to narrow the range of choices the server has in filling the request.
By specifying a q, or quality, value of .9 for QuickTime and .1 for MS Video, you indicate that you'd like to have a QuickTime video if at all possible, but you'll accept an alternate format.
You tell the server to not even think of sending a QuickTime file that's larger than 5M or an MS Video file larger than 7M. You simply don't have time to spend viewing files that are too large.
Finally, you state that if the server can't come up with the goods within 30 seconds of the request, forget it.
That's the way content negotiation is supposed to work. The client specifies the request in a way that guides the server's decisions about what to provide. By setting the various parameters, the client indicates the appropriateness of the various responses. The server interprets the request without needing to resort to external programming, such as a CGI script.
Sounds like a rich, highly interactive world, doesn't it? Too bad it's not our world. In the world we live in, things aren't so simple. Although the Apache and W3 (CERN) servers do support negotiation, there's hardly a browser out there that does. And without at least two participants, you can't have a conversation.
However, as you'll see in the next section, with some luck and a bit of CGI programming, you can create your own form of content negotiation.
As mentioned earlier, during each request for a document, the browser sends a list of MIME types it can accept. The server captures this information and makes it available to CGI programs. So you should be able to use this information to do your own content negotiation, right? Well, there's a problem here, and its name is expediency.
Because the list of MIME types a browser can accept can be quite long, many browsers abbreviate the listing by sending a list of important types followed by a wild card-*/*. The wild card means, send anything you've got. I suppose the reasoning goes, why bore the server with all these MIME types when it's not going to do anything with them anyway? To speed up the process, suppress all but the most important types.
To make use of content negotiation using a CGI script, you must first determine what your target browser is sending the server. If it's sending a wild card, you're out of luck. But if it sends the MIME type you're interested in exploiting, you're in business. The Perl script in listing 10.1 displays the MIME types sent by your browser.
Listing 10.1 mimetest.cgi: Reporting the MIME Types Your Browser Accepts
#! /usr/local/bin/perl
# print out a MIME header so the server knows
#this is an HTML document
print qq|Content-type: text/html;\n\n|;
# print out standard HTML beginning of document
print qq|<html><head><title>MIME Test</title></head>\n|;
print qq|<body>\n|;
# print the environment variable
print qq|<h1>Your browser accepts: $ENV{'HTTP_ACCEPT'}</h1>\n|;
# close the document
print qq|</body></html>\n|;
This script makes use of an environment variable that's set by UNIX Web servers. (Windows-based servers make these variables available to scripts in a different manner. See your server's manual for information.) Many environment variables are set, including SERVER_SOFTWARE, SERVER_NAME, PATH_INFO, QUERY_STRING, and SCRIPT_NAME. The variable that's most important for MIME processing is HTTP_ACCEPT. This variable contains all the MIME types that the browser has passed to the server, separated by commas.
Unfortunately, when you run this script, you'll discover that Netscape is among the browsers that send a few image types and a wild card. Netcom's NetCruiser doesn't even send a wild card, since you can't add new MIME types to its repertoire. Microsoft's Internet Explorer has it backward-it sends the wild card, followed by a handful of media types. SPRY Mosaic, on the other hand, reports all MIME types to the server.
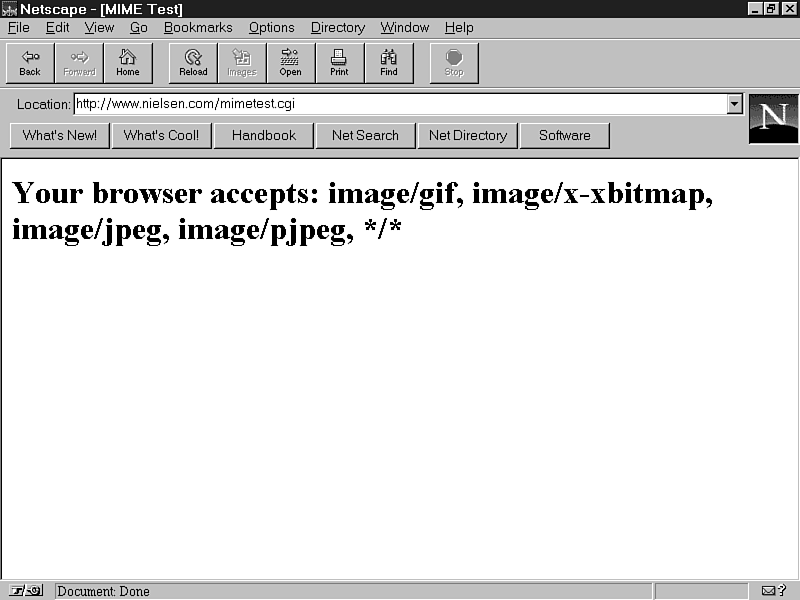
If you run the MIMETEST script using Netscape, you see a display similar to figure 10.6.
Figure 10.6 : The MIMETEST script shows that Netscape uses the wild-card MIME type.
As you can see, not much information is here. Netscape uses the wild card to indicate that any MIME type is fine. While this speeds up the requesting of documents (and we know that Netscape will do almost anything for speed), it deprives the server-and you, the CGI programmer-from valuable information about the capabilities of the browser. You have no idea whether this client can accept audio files, QuickTime movies, or VRML.
Other browsers provide more information on MIME types. For example, figure 10.7 shows what happens when you run the MIMETEST script using SPRY Mosaic.
Figure 10.7 : The MIMETEST script shows that SPRY Mosaic reports all MIME types.
For purposes of argument, say that you have two formats of an image-a GIF and a JPEG. You'd much rather have your server deliver the JPEG because it's much smaller. Since you realize that not every browser out there can render a JPEG, you'd like to check first before sending the image.
In a perfect world, content negotiation such as this would be handled between the browser and the server, without the user ever knowing and without you having to do any programming. In this world, however, you have to write a CGI script that assembles the requested document from parts. In this way, you can put logic in your script to determine whether the browser can handle the MIME type you want to send.
The Perl script in listing 10.2 parses the HTTP_ACCEPT environment variable and creates a document on the fly, tailored to the specific browser making the request.
Listing 10.2 imgtest.cgi: Delivering a Different Image Type, Depending on Browser Capabilities
#! /usr/local/bin/perl
# print out a MIME header so the server knows
#this is an HTML document
print qq|Content-type: text/html;\n\n|;
# print out standard HTML beginning of document
print qq|<html><head><title>Mike Ellsworth's Tool Time</title>\n|;
print qq|</head><BODY bgcolor="#ffffff">\n|;
# assign the environment variable to a Perl variable
# if you want to get fancy, you can add some code to put the parts
# into an array by splitting on the comma between MIME types
$accepts = $ENV{'HTTP_ACCEPT'};
# now test to see if the string jpeg exists in the environment
if ($accepts =~ /jpeg/i) {
print qq|<img border=0 src="testme.jpg" alt="Yo" align=left></a>|;
} else {
print qq|<img border=0 src="testme.gif" alt="Yo" align=left></a>|;
}
# read in the base document and print to STDOUT
open(READ, "testimg.txt");
while (<READ>) {
print;
}
close(READ);
# close the document
print qq|</body></html>\n|;
One disadvantage of this approach to content negotiation is that every document must be served by a CGI script. You can set up a master script to serve up all the documents on your site, but then all your URLs could look funny when displayed on your users' current URL line, or when they put them in a bookmark or hotlist.
Another disadvantage is that serving all your Web documents via a CGI script really slows your server's performance. There's considerable overhead in the server recognizing the CGI script, forking a process to run it, and returning the output to the user. Also, you're adding more I/Os by starting the Perl interpreter, opening the CGI script, opening and reading the base document, and so on.
There's not much you can do about this second point, except write tight code or use fast languages. But you can clean up the URLs of documents served by a CGI script by using the POST method to call the script rather than the familiar GET method.
For example, one script I wrote for my site takes a parameter from the user and delivers a document describing services available in the country selected. Using the GET method to call this script makes the URL look like the following:
http://www.nielsen.com/home/countries/country.cgi?country=Great+Britain
It's not a pretty sight. But you could bookmark this URL and return exactly to this page later.
If you use the POST method to call your CGI program, the URL displayed to the user never changes. Say that you want to get two documents-somedoc.htm and someotherdoc.htm. With the POST method, even though the links specify the proper document, your resulting URLs look identical to the user. Your document displays links such as the following:
<FORM ACTION="get.cgi" METHOD="POST"> <INPUT TYPE="hidden" VALUE="doc2get" NAME="somedoc.htm"> <INPUT TYPE="submit" VALUE="A fabulous doc" NAME="item"> </form> <FORM ACTION="get.cgi" METHOD="POST"> <INPUT TYPE="hidden" VALUE="doc2get" NAME="someotherdoc.htm"> <INPUT TYPE="submit" VALUE="An equally fabulous doc" NAME="item"> </form>
After users view each document, however, it appears to them that the URL is the same:
http://www.yoursite.com/get.cgi http://www.yoursite.com/get.cgi
This is because when you use the POST method, information is sent to the server using STDIN rather than as part of a the QUERY_STRING. Unlike QUERY_STRING, STDIN information isn't displayed as part of the URL. However, if you were to bookmark either URL and return later, the get.cgi program would be run with no parameters because they weren't saved as part of the URL. As a result, you wouldn't get the document you thought you had bookmarked.
If instead you use the GET method to call your CGI programs, the links can look something like this:
<a href ="get.cgi?doc2get=somedoc.htm>A fabulous doc</a> <a href ="get.cgi?doc2get=someotherdoc.htm>An equally fabulous doc</a>
When the user views each resulting document, the URL appears as follows:
http://www.yoursite.com/get.cgi?doc2get=somedoc.htm http://www.yoursite.com/get.cgi?doc2get=someotherdoc.htm
This is perhaps an improvement, but it's hard for humans to understand or to tell a friend.
Using the PATH_INFO environment variable instead of the default (QUERY_STRING) makes the URLs look a little better:
http://www.yoursite.com/get/somedoc.htm http://www.yoursite.com/get/someotherdoc.htm
This assumes that your CGI program is called get, with no extension. It further assumes that you've established a script alias for the root directory so that CGI scripts can be run from there.
The CGI scripts shown as examples in this chapter all begin the output with a MIME header, which should always be followed by a blank line. When you do this, the header is read and interpreted by the server rather than passed directly to the browser. Because a process or document can generate three types of headers, the server must parse the header to determine its type. The three HTML header types are as follows:
Any header not following these forms is passed back to the client, as long as the script name begins with nph-, which stands for non-parsed header. A non-parsed header is, as its name implies, not parsed by the server, but rather sent directly to the client. The server assumes that all relevant header information is contained in the proper format when you use an NPH script. However, you must be careful if you decide to use this option, since you'll be responsible for assembling the entire header. There are many possible fields for complete result headers. At a minimum, you must provide the following information:
The order of header lines within the HTTP header isn't important. However, as a matter of style, make the MIME fields the last ones, so that the MIME fields and the following document form a valid MIME document. (Always remember that the header is separated from the document or file being sent by a blank line.) Listing 10.3 is an example of using this technique.
Listing 10.3 nph-test.cgi: Causing the Server to Send the Header Directly to the Client Without Parsing It
#! /usr/local/bin/perl # print out an entire HTTP header print qq|HTTP/1.0 200 OK\n|; print qq|Server: NCSA/1.4\n|; print qq|Content-type: text/html\n\n|; # print out standard HTML beginning of document print qq|<html><head><title>A test page</title></title></head>\n|; print qq|<BODY bgcolor="#ffffff">\n|; # print the HTML document print qq|<h1>This is a test, only a test.</h1>\n|; # close the document print qq|</body></html>\n|;
For a good discussion of headers and CGI, go to http://hoohoo. ncsa.uiuc.edu/cgi/out.html. This document is also available on the CD-ROM accompanying this book.